### _Why are the changes needed?_
#### 1. know about this pr
When we execute flink(1.17+) test case, it may throw exception when the test case is `show/stop job`, the exception desc like this
```
- execute statement - show/stop jobs *** FAILED ***
org.apache.kyuubi.jdbc.hive.KyuubiSQLException: Error operating ExecuteStatement: org.apache.flink.table.gateway.service.utils.SqlExecutionException: Could not stop job 4dece26857fab91d63fad1abd8c6bdd0 with savepoint for operation 9ed8247a-b7bd-4004-875b-61ba654ab3dd.
at org.apache.flink.table.gateway.service.operation.OperationExecutor.lambda$callStopJobOperation$11(OperationExecutor.java:628)
at org.apache.flink.table.gateway.service.operation.OperationExecutor.runClusterAction(OperationExecutor.java:716)
at org.apache.flink.table.gateway.service.operation.OperationExecutor.callStopJobOperation(OperationExecutor.java:601)
at org.apache.flink.table.gateway.service.operation.OperationExecutor.executeOperation(OperationExecutor.java:434)
at org.apache.flink.table.gateway.service.operation.OperationExecutor.executeStatement(OperationExecutor.java:195)
at org.apache.kyuubi.engine.flink.operation.ExecuteStatement.executeStatement(ExecuteStatement.scala:64)
at org.apache.kyuubi.engine.flink.operation.ExecuteStatement.runInternal(ExecuteStatement.scala:56)
at org.apache.kyuubi.operation.AbstractOperation.run(AbstractOperation.scala:171)
at org.apache.kyuubi.session.AbstractSession.runOperation(AbstractSession.scala:101)
at org.apache.kyuubi.session.AbstractSession.$anonfun$executeStatement$1(AbstractSession.scala:131)
at org.apache.kyuubi.session.AbstractSession.withAcquireRelease(AbstractSession.scala:82)
at org.apache.kyuubi.session.AbstractSession.executeStatement(AbstractSession.scala:128)
at org.apache.kyuubi.service.AbstractBackendService.executeStatement(AbstractBackendService.scala:67)
at org.apache.kyuubi.service.TFrontendService.ExecuteStatement(TFrontendService.scala:252)
at org.apache.kyuubi.shade.org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1557)
at org.apache.kyuubi.shade.org.apache.hive.service.rpc.thrift.TCLIService$Processor$ExecuteStatement.getResult(TCLIService.java:1542)
at org.apache.kyuubi.shade.org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.kyuubi.shade.org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.kyuubi.service.authentication.TSetIpAddressProcessor.process(TSetIpAddressProcessor.scala:36)
at org.apache.kyuubi.shade.org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1[149](https://github.com/apache/kyuubi/actions/runs/6649714451/job/18068699087?pr=5501#step:8:150))
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: java.util.concurrent.ExecutionException: java.util.concurrent.CompletionException: java.util.concurrent.CompletionException: org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint triggering task Source: tbl_a[6] -> Sink: tbl_b[7] (1/1) of job 4dece26857fab91d63fad1abd8c6bdd0 is not being executed at the moment. Aborting checkpoint. Failure reason: Not all required tasks are currently running.
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1928)
at org.apache.flink.table.gateway.service.operation.OperationExecutor.lambda$callStopJobOperation$11(OperationExecutor.java:617)
... 22 more
Caused by: java.util.concurrent.CompletionException: java.util.concurrent.CompletionException: org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint triggering task Source: tbl_a[6] -> Sink: tbl_b[7] (1/1) of job 4dece26857fab91d63fad1abd8c6bdd0 is not being executed at the moment. Aborting checkpoint. Failure reason: Not all required tasks are currently running.
at java.util.concurrent.CompletableFuture.encodeRelay(CompletableFuture.java:326)
at java.util.concurrent.CompletableFuture.completeRelay(CompletableFuture.java:338)
at java.util.concurrent.CompletableFuture.uniRelay(CompletableFuture.java:925)
at java.util.concurrent.CompletableFuture$UniRelay.tryFire(CompletableFuture.java:913)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1990)
at org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$1(AkkaInvocationHandler.java:260)
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1990)
at org.apache.flink.util.concurrent.FutureUtils.doForward(FutureUtils.java:1298)
at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.lambda$null$1(ClassLoadingUtils.java:93)
at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.lambda$guardCompletionWithContextClassLoader$2(ClassLoadingUtils.java:92)
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1990)
at org.apache.flink.runtime.concurrent.akka.AkkaFutureUtils$1.onComplete(AkkaFutureUtils.java:45)
at akka.dispatch.OnComplete.internal(Future.scala:299)
at akka.dispatch.OnComplete.internal(Future.scala:297)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:224)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:221)
at org.apache.kyuubi.operation.AbstractOperation.run(AbstractOperation.scala:171)
...
Cause: java.lang.RuntimeException: org.apache.flink.util.SerializedThrowable:java.util.concurrent.CompletionException: org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint triggering task Source: tbl_a[6] -> Sink: tbl_b[7] (1/1) of job 4dece26857fab91d63fad1abd8c6bdd0 is not being executed at the moment. Aborting checkpoint. Failure reason: Not all required tasks are currently running.
at java.util.concurrent.CompletableFuture.encodeRelay(CompletableFuture.java:326)
at java.util.concurrent.CompletableFuture.completeRelay(CompletableFuture.java:338)
at java.util.concurrent.CompletableFuture.uniRelay(CompletableFuture.java:925)
at java.util.concurrent.CompletableFuture$UniRelay.tryFire(CompletableFuture.java:913)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1990)
at org.apache.flink.runtime.rpc.akka.AkkaInvocationHandler.lambda$invokeRpc$1(AkkaInvocationHandler.java:260)
at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774)
at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
...
Cause: java.lang.RuntimeException: org.apache.flink.util.SerializedThrowable:org.apache.flink.runtime.checkpoint.CheckpointException: Checkpoint triggering task Source: tbl_a[6] -> Sink: tbl_b[7] (1/1) of job 4dece26857fab91d63fad1abd8c6bdd0 is not being executed at the moment. Aborting checkpoint. Failure reason: Not all required tasks are currently running.
at org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.checkTasksStarted(DefaultCheckpointPlanCalculator.java:143)
at org.apache.flink.runtime.checkpoint.DefaultCheckpointPlanCalculator.lambda$calculateCheckpointPlan$1(DefaultCheckpointPlanCalculator.java:105)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:[160](https://github.com/apache/kyuubi/actions/runs/6649714451/job/18068699087?pr=5501#step:8:161)4)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRunAsync$4(AkkaRpcActor.java:453)
at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:68)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:453)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:218)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:84)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:[168](https://github.com/apache/kyuubi/actions/runs/6649714451/job/18068699087?pr=5501#step:8:169))
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24)
...
```
#### 2. what make the test case failed?
If we want know the reason about the exception, we need to understand the process of flink executing stop job, the process line like this code space show(it's source is our bad test case, we can use this test case to solve similar problems)
```
1. sql
1.1 create table tbl_a (a int) with ('connector' = 'datagen','rows-per-second'='10')
1.2 create table tbl_b (a int) with ('connector' = 'blackhole')
1.3 insert into tbl_b select * from tbl_a
2. start job: it will get 2 tasks abount source sink
3. show job: we can get job info
4. stop job(the main error):
4.1 stop job need checkpoint
4.2 start checkpoint, it need all task state is running
4.3 checkpoint can not get all task state is running, then throw the exception
```
Actually, in a normal process, it should not throw the exception, if this happens to your job, please check your kyuubi conf `kyuubi.session.engine.flink.max.rows`, it's default value is 1000000. But in the test case, we only the the conf's value is 10.
It's the reason to make the error, this conf makes when we execute a stream query, it will cancel the when the limit is reached. Because flink's datagen is a streamconnector, so we can imagine, when we execute those sql, because our conf, it will make the sink task be canceled because the query reached 10. So when we execute stop job, flink checkpoint cannot get the tasks about this job is all in running state, then flink throw this exception.
#### 3. how can we solve this problem?
When your job makes the same exception, please make sure your kyuubi conf `kyuubi.session.engine.flink.max.rows`'s value can it meet your streaming query needs? Then changes the conf's value.
close#5531
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5549 from davidyuan1223/fix_flink_test_bug.
Closes#5531
ce7fd7961 [david yuan] Update externals/kyuubi-flink-sql-engine/src/test/scala/org/apache/kyuubi/engine/flink/operation/FlinkOperationSuite.scala
dc3a4b9ba [davidyuan] fix flink on yarn test bug
86a647ad9 [davidyuan] fix flink on yarn test bug
cbd4c0c3d [davidyuan] fix flink on yarn test bug
8b51840bc [davidyuan] add common method to get session level config
bcb0cf372 [davidyuan] Merge remote-tracking branch 'origin/master'
72e7aea3c [david yuan] Merge branch 'apache:master' into master
57ec746e9 [david yuan] Merge pull request #13 from davidyuan1223/fix
56b91a321 [yuanfuyuan] fix_4186
c8eb9a2c7 [david yuan] Merge branch 'apache:master' into master
2beccb6ca [david yuan] Merge branch 'apache:master' into master
0925a4b6f [david yuan] Merge pull request #12 from davidyuan1223/revert-11-fix_4186
40e80d9a8 [david yuan] Revert "fix_4186"
c83836b43 [david yuan] Merge pull request #11 from davidyuan1223/fix_4186
360d183b0 [david yuan] Merge branch 'master' into fix_4186
b61604442 [yuanfuyuan] fix_4186
e244029b8 [david yuan] Merge branch 'apache:master' into master
bfa6cbf97 [davidyuan1223] Merge branch 'apache:master' into master
16237c2a9 [davidyuan1223] Merge branch 'apache:master' into master
c48ad38c7 [yuanfuyuan] remove the used blank lines
55a0a43c5 [xiaoyuandajian] Merge pull request #10 from xiaoyuandajian/fix-#4057
cb1193576 [yuan] Merge remote-tracking branch 'origin/fix-#4057' into fix-#4057
86e4e1ce0 [yuan] fix-#4057 info: modify the shellcheck errors file in ./bin 1. "$@" is a array, we want use string to compare. so update "$@" => "$*" 2. `tty` mean execute the command, we can use $(tty) replace it 3. param $# is a number, compare number should use -gt/-lt,not >/< 4. not sure the /bin/kyuubi line 63 'exit -1' need modify? so the directory bin only have a shellcheck note in /bin/kyuubi
dd39efdeb [袁福元] fix-#4057 info: 1. "$@" is a array, we want use string to compare. so update "$@" => "$*" 2. `tty` mean execute the command, we can use $(tty) replace it 3. param $# is a number, compare number should use -gt/-lt,not >/<
Lead-authored-by: davidyuan <yuanfuyuan@mafengwo.com>
Co-authored-by: david yuan <51512358+davidyuan1223@users.noreply.github.com>
Co-authored-by: yuanfuyuan <1406957364@qq.com>
Co-authored-by: yuan <yuanfuyuan@mafengwo.com>
Co-authored-by: davidyuan1223 <51512358+davidyuan1223@users.noreply.github.com>
Co-authored-by: xiaoyuandajian <51512358+xiaoyuandajian@users.noreply.github.com>
Co-authored-by: 袁福元 <yuanfuyuan@mafengwo.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
current version, when set `kyuubi.session.engine.spark.showProgress=true`, it will show stage's progress info,but the info only show stage's detail, now we need to add job info in this, just like
```
[Stage 1:> (0 + 1) / 2]
```
to
```
[Job 1 (0 / 1) Stages] [Stage 1:> (0 + 1) / 2]
```
**this update is useful when user want know their sql execute detail**
closes#4186
### _How was this patch tested?_
- [x] Add screenshots for manual tests if appropriate
**The photo show match log**

- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5410 from davidyuan1223/improvement_add_job_log.
Closes#4186
d8d03c4c0 [Cheng Pan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/SQLOperationListener.scala
a06e9a17c [david yuan] Update SparkConsoleProgressBar.scala
854408416 [david yuan] Merge branch 'apache:master' into improvement_add_job_log
963ff18b9 [david yuan] Update SparkConsoleProgressBar.scala
9e4635653 [david yuan] Update SparkConsoleProgressBar.scala
8c04dca7d [david yuan] Update SQLOperationListener.scala
39751bffa [davidyuan] fix
4f657e728 [davidyuan] fix deleted files
86756eba7 [david yuan] Merge branch 'apache:master' into improvement_add_job_log
0c9ac27b5 [davidyuan] add showProgress with jobInfo Unit Test
d4434a0de [davidyuan] Revert "add showProgress with jobInfo Unit Test"
84b1aa005 [davidyuan] Revert "improvement_add_job_log fix"
66126f96e [davidyuan] Merge remote-tracking branch 'origin/improvement_add_job_log' into improvement_add_job_log
228fd9cf3 [davidyuan] add showProgress with jobInfo Unit Test
055e0ac96 [davidyuan] add showProgress with jobInfo Unit Test
e4aac34bd [davidyuan] Merge remote-tracking branch 'origin/improvement_add_job_log' into improvement_add_job_log
b226adad8 [davidyuan] Merge remote-tracking branch 'origin/improvement_add_job_log' into improvement_add_job_log
a08799ca0 [david yuan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/StageStatus.scala
a991b68c4 [david yuan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/StageStatus.scala
d12046dac [davidyuan] add showProgress with jobInfo Unit Test
10a56b159 [davidyuan] add showProgress with jobInfo Unit Test
a973cdde6 [davidyuan] improvement_add_job_log fix 1. provide Option[Int] with JobId
e8a510891 [davidyuan] improvement_add_job_log fix 1. provide Option[Int] with JobId
7b9e874f2 [davidyuan] improvement_add_job_log fix 1. provide Option[Int] with JobId
5b4aaa8b5 [davidyuan] improvement_add_job_log fix 1. fix new end line 2. provide Option[Int] with JobId
780f9d15e [davidyuan] improvement_add_job_log fix 1. remove duplicate synchronized 2. because the activeJobs is ConcurrentHashMap, so reduce synchronized 3. fix scala code style 4. change forEach to asScala code style 5. change conf str to KyuubiConf.XXX.key
59340b713 [davidyuan] add showProgress with jobInfo Unit Test
af05089d4 [davidyuan] add showProgress with jobInfo Unit Test
c07535a01 [davidyuan] [Improvement] spark showProgress can briefly output info of the job #4186
d4bdec798 [yuanfuyuan] fix_4186
9fa8e73fc [davidyuan] add showProgress with jobInfo Unit Test
49debfbe3 [davidyuan] improvement_add_job_log fix 1. provide Option[Int] with JobId
5cf8714e0 [davidyuan] improvement_add_job_log fix 1. provide Option[Int] with JobId
249a422b6 [davidyuan] improvement_add_job_log fix 1. provide Option[Int] with JobId
e15fc7195 [davidyuan] improvement_add_job_log fix 1. fix new end line 2. provide Option[Int] with JobId
4564ef98f [davidyuan] improvement_add_job_log fix 1. remove duplicate synchronized 2. because the activeJobs is ConcurrentHashMap, so reduce synchronized 3. fix scala code style 4. change forEach to asScala code style 5. change conf str to KyuubiConf.XXX.key
32ad0759b [davidyuan] add showProgress with jobInfo Unit Test
d30492e46 [davidyuan] add showProgress with jobInfo Unit Test
6209c344e [davidyuan] [Improvement] spark showProgress can briefly output info of the job #4186
56b91a321 [yuanfuyuan] fix_4186
Lead-authored-by: davidyuan <yuanfuyuan@mafengwo.com>
Co-authored-by: davidyuan <davidyuan1223@gmail.com>
Co-authored-by: david yuan <51512358+davidyuan1223@users.noreply.github.com>
Co-authored-by: yuanfuyuan <1406957364@qq.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Resolve: #5405 Support the Flink 1.18
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5465 from YesOrNo828/flink-1.18.
Closes#5405
a0010ca14 [Xianxun Ye] [KYUUBI #5405] [FLINK] Remove flink1.18 rc repo
2a4ae365c [Xianxun Ye] Update .github/workflows/master.yml
d4d458dc7 [Xianxun Ye] [KYUUBI #5405] [FLINK] Update the flink1.18-rc3 repo
99172e3da [Xianxun Ye] [KYUUBI #5405] [FLINK] Using the staging repo during the RC stage
4c0cf887b [Xianxun Ye] [KYUUBI #5405] [FLINK] Using the staging repo during the RC stage
c74f5c31b [Xianxun Ye] [KYUUBI #5405] [FLINK] fixed Pan's comments.
1933ebadd [Xianxun Ye] [KYUUBI #5405] [FLINK] Support Flink 1.18
Authored-by: Xianxun Ye <yesorno828423@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Refer to spark and flink settings conf, support configure Trino session conf in kyuubi-default.conf
issue : https://github.com/apache/kyuubi/issues/5282
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5283 from ASiegeLion/kyuubi-master-trino.
Closes#5282
87a3f57b4 [Cheng Pan] Apply suggestions from code review
effdd79f4 [liupeiyue] [KYUUBI #5282]Add trino's session conf to kyuubi-default.xml
399a200f7 [liupeiyue] [KYUUBI #5282]Add trino's session conf to kyuubi-default.xml
7462b32c2 [liupeiyue] [KYUUBI #5282]Add trino's session conf to kyuubi-default.xml--Update documentation
5295f5f94 [liupeiyue] [KYUUBI #5282]Add trino's session conf to kyuubi-default.xml
Lead-authored-by: liupeiyue <liupeiyue@yy.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
To close#5382.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5490 from zhuyaogai/issue-5382.
Closes#5382
4757445e7 [Fantasy-Jay] Remove unrelated comment.
f68c7aa6c [Fantasy-Jay] Refactor JDBC engine to reduce to code duplication.
4ad6b3c53 [Fantasy-Jay] Refactor JDBC engine to reduce to code duplication.
Authored-by: Fantasy-Jay <13631435453@163.com>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
close [#5449](https://github.com/apache/kyuubi/issues/5449).
Unlike the initial preview release, Delta Spark 3.0.0 is now built on top of Apache Spark™ 3.5.
Delta Spark maven artifact has been renamed from delta-core to delta-spark.
https://github.com/delta-io/delta/releases/tag/v3.0.0
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5450 from zml1206/5449.
Closes#5449
a7969ed6a [zml1206] bump Delta Lake 3.0.0
Authored-by: zml1206 <zhuml1206@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
The Apache Spark Community found a performance regression with log4j2. See https://github.com/apache/spark/pull/36747.
This PR to fix the performance issue on our side.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5400 from ITzhangqiang/KYUUBI_5365.
Closes#5365
dbb9d8b32 [ITzhangqiang] [KYUUBI #5365] Don't use Log4j2's extended throwable conversion pattern in default logging configurations
Authored-by: ITzhangqiang <itzhangqiang@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Replace string literal with constant variable
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5339 from cxzl25/use_engine_init_timeout_key.
Closes#5339
bef2eaa4a [sychen] fix
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Extract common assertion method for verifying file contents
- Ensure integrity of the file by comparing the line count
- Correct the script name for Spark engine KDF doc generation from `gen_kdf.sh` to `gen_spark_kdf_docs.sh`
- Add `gen_hive_kdf_docs.sh` script for Hive engine KDF doc generation
- Fix incorrect hints for Ranger spec file generation
- shows the line number of the incorrect file content
- Streamingly read file content by line with buffered support
- Regeneration hints:
<img width="656" alt="image" src="https://github.com/apache/kyuubi/assets/1935105/d1a7cb70-8b63-4fe9-ae27-80dadbe84799">
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5275 from bowenliang123/doc-regen-hint.
Closes#5275
9af97ab86 [Bowen Liang] implicit source position
07020c74d [liangbowen] assertFileContent
Lead-authored-by: liangbowen <liangbowen@gf.com.cn>
Co-authored-by: Bowen Liang <liangbowen@gf.com.cn>
Signed-off-by: Bowen Liang <liangbowen@gf.com.cn>
### _Why are the changes needed?_
Flink sessions are now managed by Kyuubi, hence disable session timeout from Flink itself.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5264 from link3280/disable_flink_session_timeout.
Closes#5264
fff5c54d7 [Paul Lin] Force disable Flink's session timeout
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Paul Lin <paullin3280@gmail.com>
### _Why are the changes needed?_
Recover CI.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5258 from pan3793/testcontainers.
Closes#5253
c1c8241af [Cheng Pan] fix
ce4f9ed2c [Cheng Pan] [KYUUBI #5253][FOLLOWUP] Supply testcontainers-scala-scalatest deps for ha module
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Implement this issue: #5232
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No
Closes#5240 from XorSum/always_cancel_job_group.
Closes#5232
7da16aaa7 [bkhan] In SparkOperation#cleanup always calls cancelJobGroup even though it's in the completed state
Authored-by: bkhan <bkhan@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
Closes#3444
### _Why are the changes needed?_
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3558 from iodone/kyuubi-3444.
Closes#3444
acaa72afe [odone] remove plugin dependency from kyuubi spark engine
739f7dd5b [odone] remove plugin dependency from kyuubi spark engine
1146eb6e0 [odone] kyuubi-3444
Authored-by: odone <odone.zhang@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
The generated application name is not effective in Flink app mode. The PR moves the name generating to the `ProcessBuilder`.
The generated app name would be like `kyuubi_USER_FLINK_SQL_myuser_default_382c0371-8cc1-4aec-90bd-a2acf4de6fac`.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5200 from link3280/flink_app_name.
Closes#5200
bf06d1c16 [Paul Lin] Fix engine name udf test
6aa09e462 [Paul Lin] Filter out unused conf in app mode
957d18c42 [Paul Lin] Fix test error in local mode
eaa5de9b4 [Paul Lin] Fix engine name missing in tests
109ff46f5 [Paul Lin] Fix test error
efb1cda82 [Paul Lin] Fix compatibility with YARN and local
65e6759b2 [Paul Lin] Remove unused import
49860f65e [Paul Lin] Optimize Flink application name generating
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Remove the provided dependency `flink-table-planner_${scala.binary.version}` which provides a legacy table planner API on Scala, but is never used in Kyuubi's source code or in runtime directly.
- `** The legacy planner is deprecated and will be dropped in Flink 1.14.**` according to [Flink 1.13's doc of Legacy Planner](https://nightlies.apache.org/flink/flink-docs-release-1.13/docs/dev/table/legacy_planner/)
- Kyuubi has dropped support for Flink 1.14 and before in #4588
- Remove the unused provided dependency `flink-sql-parser`
- All tests on Scala 2.12 work fine without them, as `flink-table-runtime` dependency provides enough Java API for usage.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5222 from bowenliang123/flink-remove-planner.
Closes#5222
716ec06e9 [liangbowen] remove flink-sql-parser dependency
0922ba5af [liangbowen] Remove unnecessary dependency flink-table-planner
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Bowen Liang <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- adding source code in `src/main/scala-2.12/**/*.scala` and `src/main/scala-2.13/**/*.scala` to including paths for Scala spotless styling
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5209 from bowenliang123/scala-reformat.
Closes#5209
84b4205e9 [liangbowen] use wildcard for scala versions
0c32c582d [liangbowen] reformat scala-2.12 specific code
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- Use `Set` collection for order-insensitive configs instead of `Seq`
- kyuubi.frontend.thrift.binary.ssl.disallowed.protocols
- kyuubi.authentication
- kyuubi.authentication.ldap.groupFilter
- kyuubi.authentication.ldap.userFilter
- kyuubi.kubernetes.context.allow.list
- kyuubi.kubernetes.namespace.allow.list
- kyuubi.session.conf.ignore.list
- kyuubi.session.conf.restrict.list
- kyuubi.session.local.dir.allow.list
- kyuubi.batch.conf.ignore.list
- kyuubi.engine.deregister.exception.classes
- kyuubi.engine.deregister.exception.messages
- kyuubi.operation.plan.only.excludes
- kyuubi.server.limit.connections.user.unlimited.list
- kyuubi.server.administrators
- kyuubi.metrics.reporters
- Support skipping blank elements
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5185 from bowenliang123/conf-toset.
Closes#5185
c656af78a [liangbowen] conf to set
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
Currently, the name of flink bootstrap SQL is auto-generated 'collect'.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5190 from link3280/bootstrap_job_name.
Closes#5190
ac769295c [Paul Lin] Explicit name Flink bootstrap sql
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Paul Lin <paullin3280@gmail.com>
### _Why are the changes needed?_
As titled.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5134 from link3280/KYUUBI-4806.
Closes#4806
a1b74783c [Paul Lin] Optimize code style
546cfdf5b [Paul Lin] Update externals/kyuubi-flink-sql-engine/src/main/scala/org/apache/kyuubi/engine/flink/operation/FlinkOperation.scala
b6eb7af4f [Paul Lin] Update externals/kyuubi-flink-sql-engine/src/main/scala/org/apache/kyuubi/engine/flink/result/ResultSet.scala
1563fa98b [Paul Lin] Remove explicit StartRowOffset for Flink
4e61a348c [Paul Lin] Add comments
c93294650 [Paul Lin] Improve code style
6bd0c8e69 [Paul Lin] Use dedicated thread pool
15412db3a [Paul Lin] Improve logging
d6a2a9cff [Paul Lin] [KYUUBI #4806][FLINK] Implement incremental result fetching
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Paul Lin <paullin3280@gmail.com>
### _Why are the changes needed?_
- adding a basic compilation CI test on Scala 2.13 , skipping test runs
- separate versions of `KyuubiSparkILoop` for Scala 2.12 and 2.13, adapting the changes of Scala interpreter packages
- rename `export` variable
```
[Error] /Users/bw/dev/kyuubi/kyuubi-server/src/test/scala/org/apache/kyuubi/server/api/v1/AdminResourceSuite.scala:563: Wrap `export` in backticks to use it as an identifier, it will become a keyword in Scala 3.
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5188 from bowenliang123/sparksql-213.
Closes#5188
04f192064 [liangbowen] update
9e764271b [liangbowen] add ci for compilation with server module
a465375bd [liangbowen] update
5c3f24fdf [liangbowen] update
4b6a6e339 [liangbowen] use Iterable for the row in MySQLTextResultSetRowPacket
f09d61d26 [liangbowen] use ListMap.newBuilder
6b5480872 [liangbowen] Use Iterable for collections
1abfa29d8 [liangbowen] 2.12's KyuubiSparkILoop
b1c9da591 [liangbowen] rename export variable
b6a6e077b [liangbowen] remove original KyuubiSparkILoop
15438b503 [liangbowen] move back scala 2.12's KyuubiSparkILoop
dd3244351 [liangbowen] adapt spark sql module to 2.13
62d3abbf0 [liangbowen] adapt server module to 2.13
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- Fix class mismatch when trying to compilation on Scala 2.13, due to implicit class reference to `StageInfo`. The compilation fails by type mismatching, if the compiler classloader loads Spark's `org.apache.spark.schedulerStageInfo` ahead of Kyuubi's `org.apache.spark.kyuubi.StageInfo`.
- Change var integer to AtomicInteger for `numActiveTasks` and `numCompleteTasks`, preventing possible concurrent inconsistency
```
[ERROR] [Error] /Users/bw/dev/kyuubi/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/SQLOperationListener.scala:56: type mismatch;
found : java.util.concurrent.ConcurrentHashMap[org.apache.spark.kyuubi.StageAttempt,org.apache.spark.scheduler.StageInfo]
required: java.util.concurrent.ConcurrentHashMap[org.apache.spark.kyuubi.StageAttempt,org.apache.spark.kyuubi.StageInfo]
[INFO] [Info] : java.util.concurrent.ConcurrentHashMap[org.apache.spark.kyuubi.StageAttempt,org.apache.spark.scheduler.StageInfo] <: java.util.concurrent.ConcurrentHashMap[org.apache.spark.kyuubi.StageAttempt,org.apache.spark.kyuubi.StageInfo]?
[INFO] [Info] : false
[ERROR] [Error] /Users/bw/dev/kyuubi/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/SQLOperationListener.scala:126: not enough arguments for constructor StageInfo: (stageId: Int, attemptId: Int, name: String, numTasks: Int, rddInfos: Seq[org.apache.spark.storage.RDDInfo], parentIds: Seq[Int], details: String, taskMetrics: org.apache.spark.executor.TaskMetrics, taskLocalityPreferences: Seq[Seq[org.apache.spark.scheduler.TaskLocation]], shuffleDepId: Option[Int], resourceProfileId: Int, isPushBasedShuffleEnabled: Boolean, shuffleMergerCount: Int): org.apache.spark.scheduler.StageInfo.
Unspecified value parameters name, numTasks, rddInfos...
[ERROR] [Error] /Users/bw/dev/kyuubi/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/SQLOperationListener.scala:148: value numActiveTasks is not a member of org.apache.spark.scheduler.StageInfo
[ERROR] [Error] /Users/bw/dev/kyuubi/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/SQLOperationListener.scala:156: value numActiveTasks is not a member of org.apache.spark.scheduler.StageInfo
[ERROR] [Error] /Users/bw/dev/kyuubi/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/kyuubi/SQLOperationListener.scala:158: value numCompleteTasks is not a member of org.apache.spark.scheduler.StageInfo
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5184 from bowenliang123/spark-stage-info.
Closes#5184
fd0b9b564 [liangbowen] update
d410491f3 [liangbowen] rename Kyuubi's StageInfo to SparkStageInfo preventing class mismatch
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- Replace deprecated class alias `scala.tools.nsc.interpreter.IR` and `scala.tools.nsc.interpreter.JPrintWriter` in Scala 2.13 with equivalent classes `scala.tools.nsc.interpreter.Results` and `java.io.PrintWriter`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
Closes#5180 from bowenliang123/interpreter-213.
Closes#5180
e76f1f05a [liangbowen] prevent to use deprecated classes in the package scala.tools.nsc.interpreter of Scala 2.13
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- Change hardcoded Scala's version 2.12 in Maven module's `artifactId` to placeholder `scala.binary.version` which is defined in project parent pom as 2.12
- Preparation for Scala 2.13/3.x support in the future
- No impact on using or building Maven modules
- Some ignorable warning messages for unstable artifactId will be thrown by Maven.
```
Warning: Some problems were encountered while building the effective model for org.apache.kyuubi:kyuubi-server_2.12🫙1.8.0-SNAPSHOT
Warning: 'artifactId' contains an expression but should be a constant
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5175 from bowenliang123/artifactId-scala.
Closes#5177
2eba29cfa [liangbowen] use placeholder of scala binary version for artifactId
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Currently, `getNextRowSetInternal` returns `TRowSet` which is not friendly to explicit EOS in streaming result fetch.
This PR changes the return type to `TFetchResultsResp` to allow the engines to determine the EOS.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5160 from link3280/refactor_result.
Closes#5160
09822f2ee [Paul Lin] Fix hasMoreRows missing
c94907e2b [Paul Lin] Explicitly set `resp.setHasMoreRows(false)` for operations
4d193fb1d [Paul Lin] Revert unrelated changes in FlinkOperation
ffd0367b3 [Paul Lin] Refactor getNextRowSetInternal to support fetch streaming data
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- extract development scripts for regenerating and verifying the golden files
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5121 from bowenliang123/gen-golden.
Closes#5121
a8fb20046 [liangbowen] add golden result file path hint in comment
444e5aff9 [liangbowen] nit
eec4fe84f [liangbowen] use the generation scripts for running test suites.
5a97785e6 [liangbowen] fix class name in gen_ranger_spec_json.sh
3be9aacf5 [liangbowen] comments
32993de43 [liangbowen] comments
ca0090909 [liangbowen] update scripts
6439ad3e9 [liangbowen] update scripts
f26d77935 [liangbowen] add scripts for golden files' generation
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
Before this PR, the ip address obtained in the K8s environment is incorrect, and `spark.driver.host` cannot be manually specified.
This time pr will adjust the way the IP is obtained and support the external parameter `spark.driver.host`
### _How was this patch tested?_
It has been tested in the local environment and verified as expected
Add screenshots for manual tests if appropriate

Closes#5148 from fantasticKe/feat_k8s_driver_ip.
Closes#5148
330f5f93d [marcoluo] feat: 修改k8s模式下获取spark.driver.host的方式
Authored-by: marcoluo <marcoluo@verizontal.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- allow using the session's user/password to connect database in the JDBC engine
- it is allowed to be applied on any share level of engines, since every kyuubi session maintains a dedicated JDBC connection in the current implementation
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5120 from bowenliang123/jdbc-user.
Closes#5120
7b8ebd137 [liangbowen] Use session's user and password to connect to database in JDBC engine
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- use `ListBuffer` instead of `ArrayBuffer` for inner string buffer, to minimize allocations for resizing
- handy `+=` operator in chaining style without explicit quotes, to make the user focus on content assembly and less distraction of quoting
- make `MarkdownBuilder` extending `Growable`, to utilize semantic operators like `+=` and `++=` which is unified inside for single or batch operation
- use `this +=` rather than `line(...)` , to reflect side effects in semantic way
- change list to stream for output comparison
- remove unused methods
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5127 from bowenliang123/md-buff.
Closes#5127
458e18c3d [liangbowen] Improvements for markdown builder
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
close#5105
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5128 from lsm1/features/kyuubi_5105.
Closes#5105
84be7fd6d [senmiaoliu] distinct default namespace
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Support SSL for trino engine.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3374 from hddong/support-trino-password.
Closes#3374
f39daaf78 [Cheng Pan] improve
6308c4cf7 [hongdongdong] Support SSL for trino engine
Lead-authored-by: Cheng Pan <chengpan@apache.org>
Co-authored-by: hongdongdong <hongdd@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close#5122
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5125 from lsm1/features/kyuubi_5122.
Closes#5122
02d0769cc [senmiaoliu] add hive kdf docs
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
close#4940
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5110 from lsm1/features/kyuubi_4940.
Closes#4940
6c0a9a37f [senmiaoliu] add kdf for hive engine
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As titled.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5109 from link3280/bootstrap_file_not_found.
Closes#5108
318199fa2 [Paul Lin] [KYUUBI #5108][Flink] Fix iFileNotFoundException during Flink engine bootstrap
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As titled.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5107 from link3280/engine_fatal_log.
Closes#5106
db45392d1 [Paul Lin] [KYUUBI #5106][Flink] Improve logs for fatal errors
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Paul Lin <paullin3280@gmail.com>
### _Why are the changes needed?_
close#5076
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5102 from lsm1/features/kyuubi_5076.
Closes#5076
ce7cfe678 [senmiaoliu] kdf support engine url
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Support initializing or comparing version with major version only, e.g "3" equivalent to "3.0"
- Remove redundant version comparison methods by using semantic versions of Spark, Flink and Kyuubi
- adding common `toDouble` method
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5039 from bowenliang123/improve-semanticversion.
Closes#5039
b6868264f [liangbowen] nit
d39646b7d [liangbowen] SPARK_ENGINE_RUNTIME_VERSION
9148caad0 [liangbowen] use semantic versions
ecc3b4af6 [mans2singh] [KYUUBI #5086] [KYUUBI # 5085] Update config section of deploy on kubernetes
Lead-authored-by: liangbowen <liangbowen@gf.com.cn>
Co-authored-by: mans2singh <mans2singh@yahoo.com>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
close#5090
### _How was this patch tested?_
After this PR it generates normal settings file in windows.
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5091 from wForget/KYUUBI-5090.
Closes#5090
9e974c7f8 [wforget] fix
dc1ebfc08 [wforget] fix
2cbec60f9 [wforget] [KYUUBI-5090] Fix AllKyuubiConfiguration to generate redundant blank lines in Windows
ecc3b4af6 [mans2singh] [KYUUBI #5086] [KYUUBI # 5085] Update config section of deploy on kubernetes
Lead-authored-by: wforget <643348094@qq.com>
Co-authored-by: mans2singh <mans2singh@yahoo.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As titled.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5082 from link3280/KYUUBI-5080.
Closes#5080
e8026b89b [Paul Lin] [KYUUBI #4806][FLINK] Improve logs
fd78f3239 [Paul Lin] [KYUUBI #4806][FLINK] Fix gateway NPE
a0a7c4422 [Cheng Pan] Update externals/kyuubi-flink-sql-engine/src/main/java/org/apache/flink/client/deployment/application/executors/EmbeddedExecutorFactory.java
50830d4d4 [Paul Lin] [KYUUBI #5080][FLINK] Fix EmbeddedExecutorFactory not thread-safe during bootstrap
Lead-authored-by: Paul Lin <paullin3280@gmail.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to fix
```
SparkDeltaOperationSuite:
org.apache.kyuubi.engine.spark.operation.SparkDeltaOperationSuite *** ABORTED ***
java.lang.RuntimeException: Unable to load a Suite class org.apache.kyuubi.engine.spark.operation.SparkDeltaOperationSuite that was discovered in the runpath: Not Support spark version (4,0)
at org.scalatest.tools.DiscoverySuite$.getSuiteInstance(DiscoverySuite.scala:80)
at org.scalatest.tools.DiscoverySuite.$anonfun$nestedSuites$1(DiscoverySuite.scala:38)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at scala.collection.TraversableLike.map(TraversableLike.scala:286)
...
Cause: java.lang.IllegalArgumentException: Not Support spark version (4,0)
at org.apache.kyuubi.engine.spark.WithSparkSQLEngine.$init$(WithSparkSQLEngine.scala:42)
at org.apache.kyuubi.engine.spark.operation.SparkDeltaOperationSuite.<init>(SparkDeltaOperationSuite.scala:25)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at java.lang.Class.newInstance(Class.java:442)
at org.scalatest.tools.DiscoverySuite$.getSuiteInstance(DiscoverySuite.scala:66)
at org.scalatest.tools.DiscoverySuite.$anonfun$nestedSuites$1(DiscoverySuite.scala:38)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)
...
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5075 from cfmcgrady/spark-4.0.
Closes#5075
ad38c0d98 [Fu Chen] refine test to adapt Spark 4.0
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Please refer to #4997
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
1. connect to KyuubiServer with beeline
2. Confirm the Application is ACCEPTed in ResourceManager, Restart KyuubiServer
3. Confirmed that Engine was terminated shortly
```
23/06/28 10:44:59 INFO storage.BlockManagerMaster: Removed 1 successfully in removeExecutor
23/06/28 10:45:00 INFO spark.SparkSQLEngine: Current open session is 0
23/06/28 10:45:00 ERROR spark.SparkSQLEngine: Spark engine has been terminated because no incoming connection for more than 60000 ms, deregistering from engine discovery space.
23/06/28 10:45:00 WARN zookeeper.ZookeeperDiscoveryClient: This Kyuubi instance lniuhpi1616.nhnjp.ism:46588 is now de-registered from ZooKeeper. The server will be shut down after the last client session completes.
23/06/28 10:45:00 INFO spark.SparkSQLEngine: Service: [SparkTBinaryFrontend] is stopping.
```
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5002 from risyomei/feature/failfast.
Closes#5002
402d6c01f [Xieming LI] Changed runInNewThread based on comment
58f11e157 [Xieming LI] Changed runInNewThread to non-blocking
c6bb02d6a [Xieming LI] Fixed Unit Test
168d996d0 [Xieming LI] Start countdown after engine is started
48ee819f2 [Xieming LI] Fixed a typo
a8d305942 [Xieming LI] Using runInNewThread ported from Spark
21f0671df [Xieming LI] Updated document
a7d5d1082 [Xieming LI] Changed the default value to turn off this feature
437be512d [Xieming LI] Trigger CI to test agagin
42a847e84 [Xieming LI] Added Configuration for timeout, changed to ThreadPoolExecutor
639bd5239 [Xieming LI] Fail the engine fast when no incoming connection in CONNECTION mode
Authored-by: Xieming LI <risyomei@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
I came cross an issue that is the the value of EXECUTOR_POD_NAME_PREFIX_MAX_LENGTH is 0 when the param is accessed in generateExecutorPodNamePrefixForK8s method.
I tried to move the EXECUTOR_POD_NAME_PREFIX_MAX_LENGTH ahead of generateExecutorPodNamePrefixForK8s method. Then, I found this issue was gone.
So is it necessary to declare the EXECUTOR_POD_NAME_PREFIX_MAX_LENGTH variable before the method definition?
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5045 from zhaohehuhu/Improvement.
Closes#5045
c74732f0c [hezhao2] recover the blank line
99aa14b0c [hezhao2] fix the code style
29929a2cb [hezhao2] declare EXECUTOR_POD_NAME_PREFIX_MAX_LENGTH param before generateExecutorPodNamePrefixForK8s method
Authored-by: hezhao2 <hezhao2@cisco.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
This PR aims to support `getQueryId` in Spark engine. It get `sparl.sql.execution.id` by adding a Listener.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5037 from Yikf/spark-queryid.
Closes#5030
9f2b5a3cb [yikaifei] Support get query id in Spark engine
Authored-by: yikaifei <yikaifei@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close#5035
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate

- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5038 from lsm1/features/kyuubi_5035.
Closes#5035
9ee06f113 [senmiaoliu] fix style
c68fd65ab [senmiaoliu] fix style
5d3d86972 [senmiaoliu] show session end time
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
As titled.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5014 from link3280/KYUUBI-4938.
Closes#4938
c43d480f9 [Paul Lin] [KYUUBI #4938][FLINK] Update function description
0dd991f03 [Paul Lin] [KYUUBI #4938][FLINK] Fix compatibility problems with Flink 1.16
7e6a3b184 [Paul Lin] [KYUUBI #4938][FLINK] Fix inconsistent istant in engine names
6ecde4c60 [Paul Lin] [KYUUBI #4938][FLINK] Implement Kyuubi UDF in Flink engine
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Adding compilation details info in SparkUI's Engine tab
- shows details of kyuubi version, including revision, revision time and branch
- show compilation version of Spark, Scala, Hadoop and Hive

### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5019 from bowenliang123/enginetab-info.
Closes#5019
3ea108bd6 [liangbowen] shows Compilation Info in SparkUI's Engine tab
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- remove unnecessary blank classSparkSimpleStatsReportListener
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5008 from bowenliang123/5007-followup.
Closes#5007
34e19f664 [liangbowen] remove blank SparkSimpleStatsReportListener
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- Scalafmt 3.7.5 release note: https://github.com/scalameta/scalafmt/releases/tag/v3.7.5
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5007 from bowenliang123/scalafmt-3.7.5.
Closes#5007
f3f7163a4 [liangbowen] Bump Scalafmt from 3.7.4 to 3.7.5
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
close#5005
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
Closes#5006 from QianyongY/features/kyuubi-5005.
Closes#5005
3bc8b7482 [yongqian] [KYUUBI #5005] Remove default settings
Authored-by: yongqian <yongqian@trip.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
- Remove redundant quoteIfNeeded method
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4973 from bowenliang123/redundant-quoteifneeded.
Closes#4937
acec0fb09 [liangbowen] Remove redundant quoteIfNeeded method
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- To improve Scala code with corrections, simplification, scala style, redundancy cleaning-up. No feature changes introduced.
Corrections:
- Class doesn't correspond to file name (SparkListenerExtensionTest)
- Correct package name in ResultSetUtil and PySparkTests
Improvements:
- 'var' could be a 'val'
- GetOrElse(null) to orNull
Cleanup & Simplification:
- Redundant cast inspection
- Redundant collection conversion
- Simplify boolean expression
- Redundant new on case class
- Redundant return
- Unnecessary parentheses
- Unnecessary partial function
- Simplifiable empty check
- Anonymous function convertible to a method value
Scala Style:
- Constructing range for seq indices
- Get and getOrElse to getOrElse
- Convert expression to Single Abstract Method (SAM)
- Scala unnecessary semicolon inspection
- Map and getOrElse(false) to exists
- Map and flatten to flatMap
- Null initializer can be replaced by _
- scaladoc link to method
Other Improvements:
- Replace map and getOrElse(true) with forall
- Unit return type in the argument of map
- Size to length on arrays and strings
- Type check can be pattern matching
- Java mutator method accessed as parameterless
- Procedure syntax in method definition
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4959 from bowenliang123/scala-Improve.
Closes#4959
2d36ff351 [liangbowen] code improvement for Scala
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- comment https://github.com/apache/kyuubi/pull/4963#discussion_r1230490326
- simplify reflection calling with unified `invokeAs` / `getField` method for either declared, inherited, or static methods / fields
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4970 from bowenliang123/unify-invokeas.
Closes#4970
592833459 [liangbowen] Revert "dedicate invokeStaticAs method"
ad45ff3fd [liangbowen] dedicate invokeStaticAs method
f08528c0f [liangbowen] nit
42aeb9fcf [liangbowen] add ut case
b5b384120 [liangbowen] nit
072add599 [liangbowen] add ut
8d019ab35 [liangbowen] unified invokeAs and getField
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
to close#4937.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4963 from bowenliang123/remove-spark-shim.
Closes#4937
e6593b474 [liangbowen] remove unnecessary row
2481e3317 [liangbowen] remove SparkCatalogShim
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
When the default databases of glue do not exist, initializing the engine session failed.
```
Caused by: software.amazon.awssdk.services.glue.model.AccessDeniedException: User: arn:aws:iam::xxxxx:user/vault-token-wap-udp-int-readwrite-1686560253-eVgl3oauuaB7v0V6wX9 is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:us-east-1:xxxxx:database/default because no identity-based policy allows the glue:GetDatabase action (Service: Glue, Status Code: 400, Request ID: 3f816608-0cb2-467b-9181-05c5bfcd29b3, Extended Request ID: null)
```

The default initialize sql "SHOW DATABASES" when Kyuubi spark accesses the glue catalog. Try to change the initialize sql "use glue.wap" has the same error.
```
kyuubi.engine.initialize.sql=use glue.wap
kyuubi.engine.session.initialize.sql=use glue.wap
```
The root cause is that hive defines a use:database, which will initialize access to the database default.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4952 from dev-lpq/glue_database.
Closes#4952
8f0951d4d [pengqli] add Glue database
90e47712f [pengqli] enhance AWS Glue database
Authored-by: pengqli <pengqli@cisco.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close https://github.com/apache/kyuubi/issues/4881
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4886 from rhh777/jdbcengine.
Closes#4881
e0439f8e6 [haorenhui] [KYUUBI #4881] update settings.md
d667d8fe8 [haorenhui] [KYUUBI #4881] update conf/docs
cba06b4b9 [haorenhui] [KYUUBI #4881] simplify code
80be4d27c [haorenhui] [KYUUBI #4881] fix style
4f0fa3ab2 [haorenhui] [KYUUBI #4881] JDBCEngine performs initialization sql
Authored-by: haorenhui <haorenhui@kingsoft.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
For the operation getNextRowSet method, we shall add lock for it.
For example, for spark operation, the result iterator is not thread-safe, it might throw exception(if the jdbc client to kyuubi server connection socket timeout).
For incremental collect mode, the fetchResult might trigger a spark task to collect the incremental result(`self.next().toIterator`).
The jdbc client to kyuubi gateway timeout, but the fetchResult request has been sent to engine.
Then the jdbc client re-send the fetchResult request.
And the getNextResultSet in spark engine side concurrent execute.
And the result iterator is not thread-safe and might cause NPE.


### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4949 from turboFei/lock_next_rowset.
Closes#4949
8f18f3236 [fwang12] getNextRowSetInternal and withLockRequired
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
- apply the usage of `ReflectUtils` and `Dyn*` to the modules of engines and plugins (eg. Spark engine, Authz plugin, lineage plugin, beeline)
- remove similar redundant methods for calling reflected methods or getting field values
- unified reflection helper methods with type casting support, as `getField[T]` for getting field values from `getFields`, `invokeAs[T]` for invoking methods in `getMethods`.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4879 from bowenliang123/reflect-use.
Closes#4879
c685fb67d [liangbowen] bug fix for "Cannot bind static field options" when executing "bin/beeline"
fc1fdf1de [liangbowen] import
59c3dd032 [liangbowen] comment
c435c131d [liangbowen] reflect util usage
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
to adapt Spark 3.5, the new conf `spark.sql.execution.arrow.useLargeVarType` was introduced in https://github.com/apache/spark/pull/39572
the signature of function `ArrowUtils#toArrowSchema` before
```scala
def toArrowSchema(
schema: StructType,
timeZoneId: String,
errorOnDuplicatedFieldNames: Boolean): Schema
```
after
```scala
def toArrowSchema(
schema: StructType,
timeZoneId: String,
errorOnDuplicatedFieldNames: Boolean,
largeVarTypes: Boolean = false): Schema
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4923 from cfmcgrady/arrow-toArrowSchema.
Closes#4923
3806494a5 [Fu Chen] Update Arguments of ArrowUtils#toArrowSchema Function
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Spark is migrating to the error class framework, in SPARK-40360(fixed in 3.4.0) SCHEMA_NOT_FOUND was introduced, which changes the output of the error message on switching a not existing database.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4915 from pan3793/schema-not-found.
Closes#4915
c0e03feaf [Cheng Pan] nit
0ee0deada [Cheng Pan] SCHEMA_NOT_FOUND
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Generalize util method for loading class from service loader in `kyuubi-util-scala` module
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4905 from bowenliang123/service-load-util.
Closes#4905
545183fbf [liangbowen] nit
8714e0591 [liangbowen] rename loadClassFromServiceLoader to loadFromServiceLoader
11936419e [liangbowen] nit
81584e335 [liangbowen] fix loadExtractorsToMap
1d64b662d [liangbowen] fix
b7d8895d3 [liangbowen] update
e15b7d22c [liangbowen] optimize JpsApplicationOperationSuite
c58ef573c [liangbowen] simplify ConnectionProvider.loadProviders
31de53df8 [liangbowen] nit
fca265998 [liangbowen] simplify
1fada9516 [liangbowen] import
323b2bd0e [liangbowen] generalize util method for loading class from service loader
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
to adapt Spark 3.5
the signature of function `ArrowConverters#fromBatchIterator` is changed in [SPARK-43528](https://github.com/apache/spark/pull/41190) (since Spark 3.5)
Spark 3.4 or previous
```scala
private[sql] def fromBatchIterator(
arrowBatchIter: Iterator[Array[Byte]],
schema: StructType,
timeZoneId: String,
context: TaskContext): Iterator[InternalRow]
```
Spark 3.5 or later
```scala
private[sql] def fromBatchIterator(
arrowBatchIter: Iterator[Array[Byte]],
schema: StructType,
timeZoneId: String,
errorOnDuplicatedFieldNames: Boolean,
context: TaskContext): Iterator[InternalRow]
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4895 from cfmcgrady/arrow-spark35.
Closes#4895
87d5b7240 [Fu Chen] fix ci
b37b321d5 [Fu Chen] adapt Spark 3.5
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- add unit tests for `ClassUtils`
- refactor `ClassUtils.createInstance` method with DynConstructors
- move `classIsLoadable` method to `ReflectUtils.isClassLoadable`, refeactor to use DynClasses
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4887 from bowenliang123/classutil.
Closes#4887
c39f9a0a4 [liangbowen] simplify ut
633e21ddc [liangbowen] Refactor and add ut for ClassUtils
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
Close#4870
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4872 from pan3793/util.
Closes#4870
0b9fe3cba [Cheng Pan] nit
ecc5ee4f2 [Cheng Pan] fix
63be7a20c [Cheng Pan] test
85363c187 [Cheng Pan] style
2227247dd [Cheng Pan] fix package
11d10a081 [Cheng Pan] Add kyuubi-util and kyuubi-util-scala modules
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
This PR aims to migrate the vanilla Zookeeper and Curator to the Kyuubi Shaded Zookeeper. It's the first step to adapting JDK 17.
There is a known issue [ZOOKEEPER-3779](https://issues.apache.org/jira/browse/ZOOKEEPER-3779) that Zookeeper 3.4 client can not run on JDK 14 and above, in https://github.com/apache/kyuubi-shaded/pull/5, we fixed this issue by a surgical.
With the above fixing, zk-3.4 and zk-3.6 clients both work well on JDK 17, we just randomly pick some cases to make sure zk-3.6 is tested
zk-3.4 client supports zk-3.4+ server, but zk-3.6 client only supports zk-3.5+ server; in the meanwhile, zk-3.4 is adopted widely, (CDH 5/6, HDP, EMR created before 2023).
We are sticky to zk-3.4 to ensure that Kyuubi can be out-of-box in the most existing Hadoop cluster but also provide zk-3.6 as an alternative(simply replace the kyuubi-shaded-zk-3.4 jar w/ kyuubi-shaded-zk-3.6, or build w/ -Pzookeeper-3.6) for users who concerns that zk-3.4 is EOL.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4852 from pan3793/shaded-zk.
Closes#4852
d960cc945 [Cheng Pan] remove staging repo
1b3622080 [Cheng Pan] Switch to Kyuubi Shaded Zookeeper
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Support Flink session idleness.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4862 from link3280/KYUUBI-4861.
Closes#4861
463d1bf9f [Paul Lin] [KYUUBI #4861] Fix class cast exception
882203157 [Paul Lin] [KYUUBI #4861] Improve code style
451403882 [Paul Lin] [KYUUBI #4861] Support Flink session idleness
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As title.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4832 from turboFei/scala_python_handle.
Closes#4415
a5a44dfa0 [fwang12] ut
eaf7f004f [fwang12] ut
c8d7a5c82 [fwang12] save
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Now we check the sparkContext.hadoopConfiguration to determine whether to apply HIVE_DELEGATION_TOKEN
Here is the method to create sparkContext hadoopConguration.
And it will add `__spark_hadoop_conf__.xml` to hadoop configuration resource.
```
/**
* Return an appropriate (subclass) of Configuration. Creating config can initialize some Hadoop
* subsystems.
*/
def newConfiguration(conf: SparkConf): Configuration = {
val hadoopConf = SparkHadoopUtil.newConfiguration(conf)
hadoopConf.addResource(SparkHadoopUtil.SPARK_HADOOP_CONF_FILE)
hadoopConf
}
```
```
/**
* Name of the file containing the gateway's Hadoop configuration, to be overlayed on top of the
* cluster's Hadoop config. It is up to the Spark code launching the application to create
* this file if it's desired. If the file doesn't exist, it will just be ignored.
*/
private[spark] val SPARK_HADOOP_CONF_FILE = "__spark_hadoop_conf__.xml"
```
<img width="1091" alt="image" src="https://github.com/apache/kyuubi/assets/6757692/f2a87a23-4565-4164-9eaa-5f7e166519de">
Per the code, this file is only created in yarn module.
#### Spark on yarn
after unzip `__spark_conf__.zip` in spark staging dir, there is a file named `__spark_hadoop_conf__.xml`.
```
grep hive.metastore.uris __spark_hadoop_conf__.xml
<property><name>hive.metastore.uris</name><value>thrift://*******:9083</value><source>programatically</source></property>
```
#### Spark on K8S
Seems for spark on k8s, there is no file named `__spark_hadoop_conf__.xml`
<img width="1580" alt="image" src="https://github.com/apache/kyuubi/assets/6757692/99de73d0-3519-4af3-8f0a-90967949ec0e">
<img width="875" alt="image" src="https://github.com/apache/kyuubi/assets/6757692/f7c477a5-23ca-4b25-8638-4b040b78899d">
We need to check the `hiveConf` instead of `hadoopConf`.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4835 from turboFei/hive_token.
Closes#4835
7657cbb11 [fwang12] hive conf
7c0af6789 [fwang12] save
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
As title.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4792 from turboFei/remove_unused.
Closes#4792
fe568af7e [fwang12] server conf
97f510020 [fwang12] save
c44e70a58 [fwang12] remove unused code
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
to adapt Spark 3.5
the signature of function `ArrowUtils#toArrowSchema` is changed in https://github.com/apache/spark/pull/40988 (since Spark3.5)
Spark 3.4 or previous
```scala
def toArrowSchema(schema: StructType, timeZoneId: String): Schema
```
Spark 3.5 or later
```scala
def toArrowSchema(
schema: StructType,
timeZoneId: String,
errorOnDuplicatedFieldNames: Boolean): Schema
```
Kyuubi is not affected by the issue of duplicated nested field names, as it consistently converts struct types to string types in Arrow mode
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4797 from cfmcgrady/arrow-toArrowSchema.
Closes#4797
2eb881b87 [Fu Chen] auto box
f69e0b395 [Fu Chen] asInstanceOf[Object] -> new JBoolean(errorOnDuplicatedFieldNames)
84c0ed381 [Fu Chen] unnecessarily force conversions
5ca65df8e [Fu Chen] Revert "new JBoolean"
0f7a1b4bd [Fu Chen] new JBoolean
044ba421c [Fu Chen] update comment
989c3caf1 [Fu Chen] reflective call ArrowUtils.toArrowSchema
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- explicitly set `n` to 1 in ChatGPT chat completion request (default to 1, https://platform.openai.com/docs/api-reference/chat/create#chat/create-n)
- use the only one choice of the chat completion response
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4810 from bowenliang123/chat-onechoice.
Closes#4810
f221de4e8 [bowenliang] one message
Authored-by: bowenliang <bowenliang@apache.org>
Signed-off-by: bowenliang <bowenliang@apache.org>
### _Why are the changes needed?_
- set session user when opening instance of ChatProvider
- use session user in ChatGPT request, to identify user of message and better monitor and abuse detection by OpenAI report( https://platform.openai.com/docs/api-reference/chat/create#chat/create-user)
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4809 from bowenliang123/chat-user.
Closes#4809
615d2385a [bowenliang] set session user in chatgpt request
Authored-by: bowenliang <bowenliang@apache.org>
Signed-off-by: bowenliang <bowenliang@apache.org>
### _Why are the changes needed?_
Support Flink job management statements.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4774 from link3280/KYUUBI-4495.
Closes#4495
a4aaebcbb [Paul Lin] [KYUUBI #4495] Adjust the order of tests
225a6cdbd [Paul Lin] [KYUUBI #4495] Increase the number of taskmanagers in the mini cluster
67935ac24 [Paul Lin] [KYUUBI #4495] Wait jobs to get ready for show job statements
9c4ce1d6e [Paul Lin] [KYUUBI #4495] Fix show jobs assertion error
ab3113cab [Paul Lin] [KYUUBI #4495] Support Flink job management statements
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to resolve https://github.com/apache/kyuubi/pull/4710#discussion_r1168600486
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4769 from cfmcgrady/arrow-send-driver-metrics.
Closes#4710
a952d088b [Fu Chen] refactor
a5645de90 [Fu Chen] address comment
6749630ee [Fu Chen] update
2dff41eeb [Fu Chen] add SparkMetricsTestUtils
8c772bca7 [Fu Chen] ut
4e3cd7d11 [Fu Chen] metrics
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [X] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4751 from link3280/KYUUBI-4745.
Closes#4745
e1e900bbe [Paul Lin] [KYUUBI #4745] Replace hive's timestamp format with the kyuubi's
0693d1f15 [Paul Lin] [KYUUBI #4745] Pin time zone in tests
462b39f2f [Paul Lin] [KYUUBI #4745] Improve variable naming
5f9976d81 [Paul Lin] [KYUUBI #4745] Support Flink's LocalZonedTimestamp DataType
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to adapt Spark 3.4
the signature of function `ArrowConveters#toBatchIterator` is changed in https://github.com/apache/spark/pull/38618 (since Spark 3.4)
Before Spark 3.4:
```
private[sql] def toBatchIterator(
rowIter: Iterator[InternalRow],
schema: StructType,
maxRecordsPerBatch: Int,
timeZoneId: String,
context: TaskContext): Iterator[Array[Byte]]
```
Spark 3.4
```
private[sql] def toBatchIterator(
rowIter: Iterator[InternalRow],
schema: StructType,
maxRecordsPerBatch: Long,
timeZoneId: String,
context: TaskContext): ArrowBatchIterator
```
the return type is changed from `Iterator[Array[Byte]]` to `ArrowBatchIterator`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4754 from cfmcgrady/arrow-spark34.
Closes#4754
a3c58d0ad [Fu Chen] fix ci
32704c577 [Fu Chen] Revert "fix ci"
e32311a03 [Fu Chen] fix ci
a76af6209 [Cheng Pan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
453b6a6b8 [Cheng Pan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
74a9f7a9d [Cheng Pan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
4ce5844af [Fu Chen] adapt Spark 3.4
Lead-authored-by: Fu Chen <cfmcgrady@gmail.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
To fix issue https://github.com/apache/kyuubi/issues/4713, a PR https://github.com/apache/kyuubi/pull/4714 was submitted, but it had Flaky test issues. After 50 local tests, it succeeded 38 times and failed 12 times.
This PR addresses the issue of flaky tests.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4749 from huangzhir/fixtest-schedulerpool.
Closes#4749
2d2e14069 [huangzhir] call KyuubiSparkContextHelper.waitListenerBus() to make sure there are no more events in the spark event queue
52a34d287 [fwang12] [KYUUBI #4746] Do not recreate async request executor if has been shutdown
d4558ea82 [huangzhir] Merge branch 'master' into fixtest-schedulerpool
44c4cefff [huangzhir] make sure the SparkListener has received the finished events for job1 and job2.
8a753e924 [huangzhir] make sure job1 started before job2
e66ede214 [huangzhir] fixbug TEST SchedulerPoolSuite a false positive result
Lead-authored-by: huangzhir <306824224@qq.com>
Co-authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
We meet an issue that cause all the operation stuck when closing operation.
Because now all the operations try to lock a Scala Enumeration val.
And if one of them stuck, all the others will be keep stuck.
In this pr, I add a lock for each operation.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4739 from turboFei/op_lock.
Closes#4739
535400a42 [fwang12] revert
a93438927 [fwang12] lockInterruptibly
274abc9db [fwang12] utils
ceda7314f [fwang12] op lock
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
This PR aims to remove Hudi integration tests from the Kyuubi project.
Actually, there is no obvious benefit to running Hudi tests w/ Kyuubi, since the real work happens on the compute engine and Hudi integration. Besides, Hudi's horrible dependency management brings significant maintenance efforts to the Kyuubi community.
This change only affects tests, does not affect any functionality.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4744 from pan3793/remove-hudi.
Closes#4744
ea99f747e [Cheng Pan] Remove Hudi integration tests
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
fix issuse https://github.com/apache/kyuubi/issues/4713
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4714 from huangzhir/fixtest-schedulerpool.
Closes#4713
Authored-by: huangzhir <306824224@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
`IpcOption.DEFAULT` was introduced in [ARROW-11081](https://github.com/apache/arrow/pull/9053)(ARROW-4.0.0), add `ARROW_IPC_OPTION_DEFAULT` for adapt Spark-3.1/3.2
```
Caused by: java.lang.NoSuchFieldError: DEFAULT
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.$anonfun$next$1(KyuubiArrowConverters.scala:304)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1491)
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.next(KyuubiArrowConverters.scala:308)
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.next(KyuubiArrowConverters.scala:231)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.foreach(KyuubiArrowConverters.scala:231)
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4720 from cfmcgrady/arrow-ipc-option.
Closes#4720
2c80e670e [Fu Chen] fix style
a8294f637 [Fu Chen] add ARROW_IPC_OPTION_DEFAULT
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Fu Chen <cfmcgrady@gmail.com>
### _Why are the changes needed?_
fix issuse https://github.com/apache/kyuubi/issues/4713
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4714 from huangzhir/fixtest-schedulerpool.
Closes#4713
e66ede214 [huangzhir] fixbug TEST SchedulerPoolSuite a false positive result
Authored-by: huangzhir <306824224@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Since the job was lazily submitted in the incremental mode, the engine should not catch the task failed exception even though the operation is in the terminal state.
Before this PR:
```
0: jdbc:hive2://0.0.0.0:10009/> set kyuubi.operation.incremental.collect=true;
+---------------------------------------+--------+
| key | value |
+---------------------------------------+--------+
| kyuubi.operation.incremental.collect | true |
+---------------------------------------+--------+
0: jdbc:hive2://0.0.0.0:10009/> SELECT raise_error('custom error message');
Error: (state=,code=0)
0: jdbc:hive2://0.0.0.0:10009/>
```
kyuubi server log
```
2023-04-14 18:47:50.185 ERROR org.apache.kyuubi.server.KyuubiTBinaryFrontendService: Error fetching results:
java.lang.NullPointerException: null
at org.apache.kyuubi.server.BackendServiceMetric.$anonfun$fetchResults$1(BackendServiceMetric.scala:191) ~[classes/:?]
at org.apache.kyuubi.metrics.MetricsSystem$.timerTracing(MetricsSystem.scala:111) ~[classes/:?]
at org.apache.kyuubi.server.BackendServiceMetric.fetchResults(BackendServiceMetric.scala:187) ~[classes/:?]
at org.apache.kyuubi.server.BackendServiceMetric.fetchResults$(BackendServiceMetric.scala:182) ~[classes/:?]
at org.apache.kyuubi.server.KyuubiServer$$anon$1.fetchResults(KyuubiServer.scala:147) ~[classes/:?]
at org.apache.kyuubi.service.TFrontendService.FetchResults(TFrontendService.scala:530) [classes/:?]
```
After this PR:
```
0: jdbc:hive2://0.0.0.0:10009/> set kyuubi.operation.incremental.collect=true;
+---------------------------------------+--------+
| key | value |
+---------------------------------------+--------+
| kyuubi.operation.incremental.collect | true |
+---------------------------------------+--------+
0: jdbc:hive2://0.0.0.0:10009/> SELECT raise_error('custom error message');
Error: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 3.0 failed 1 times, most recent failure: Lost task 0.0 in stage 3.0 (TID 3) (0.0.0.0 executor driver): java.lang.RuntimeException: custom error message
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.project_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:364)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:890)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:890)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2672)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2608)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2607)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2607)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1182)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2860)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2802)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2791)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:952)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2228)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2249)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2268)
at org.apache.spark.rdd.RDD.collectPartition$1(RDD.scala:1036)
at org.apache.spark.rdd.RDD.$anonfun$toLocalIterator$3(RDD.scala:1038)
at org.apache.spark.rdd.RDD.$anonfun$toLocalIterator$3$adapted(RDD.scala:1038)
at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:486)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:492)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.kyuubi.operation.IterableFetchIterator.hasNext(FetchIterator.scala:97)
at scala.collection.Iterator$SliceIterator.hasNext(Iterator.scala:268)
at scala.collection.Iterator.toStream(Iterator.scala:1417)
at scala.collection.Iterator.toStream$(Iterator.scala:1416)
at scala.collection.AbstractIterator.toStream(Iterator.scala:1431)
at scala.collection.TraversableOnce.toSeq(TraversableOnce.scala:354)
at scala.collection.TraversableOnce.toSeq$(TraversableOnce.scala:354)
at scala.collection.AbstractIterator.toSeq(Iterator.scala:1431)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.$anonfun$getNextRowSet$1(SparkOperation.scala:265)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.$anonfun$withLocalProperties$1(SparkOperation.scala:155)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.withLocalProperties(SparkOperation.scala:139)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.getNextRowSet(SparkOperation.scala:243)
at org.apache.kyuubi.operation.OperationManager.getOperationNextRowSet(OperationManager.scala:141)
at org.apache.kyuubi.session.AbstractSession.fetchResults(AbstractSession.scala:240)
at org.apache.kyuubi.service.AbstractBackendService.fetchResults(AbstractBackendService.scala:214)
at org.apache.kyuubi.service.TFrontendService.FetchResults(TFrontendService.scala:530)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1837)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1822)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.kyuubi.service.authentication.TSetIpAddressProcessor.process(TSetIpAddressProcessor.scala:36)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: custom error message
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.project_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:364)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:890)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:890)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
... 3 more (state=,code=0)
0: jdbc:hive2://0.0.0.0:10009/>
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4711 from cfmcgrady/incremental-show-error-msg.
Closes#4711
66bb527ce [Fu Chen] JDBC client should catch task failed exception in the incremental mode
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Close#4681
Set `CreateSparkTimeoutChecker` in `SparkSQLEngine` daemon.
Exit when spark session initialize fail.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4682 from zwangsheng/KYUUBI_4681.
Closes#4681
1928a67ec [zwangsheng] Add thread name
57f1914e4 [zwangsheng] Add thread name
71ff31a2b [zwangsheng] revert
4e8a619b2 [zwangsheng] DEBUG
ea23fae11 [zwangsheng] Change Init Timeout => 10M
3a89acc64 [zwangsheng] fix comments
565d1c90a [zwangsheng] [KYUUBI #4681][Engine] Set thread daemon
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Now `GetCurrentCatalog`/`GetCurrentDatabase`/`SetCurrentCatalog`/`SetCurrentDatabase`is executed through the statement, and the jdbc client will try to obtain the operation log corresponding to the statement.
At present, these operations do not generate operation logs, so the engine log will be throw exception(`failed to generate operation log`).
```java
23/04/10 20:25:23 INFO GetCurrentCatalog: Processing anonymous's query[8218e7ed-b4a4-41ad-a1cc-6f82bf3d55bb]: INITIALIZED_STATE -> RUNNING_STATE, statement:
GetCurrentCatalog
23/04/10 20:25:23 INFO GetCurrentCatalog: Processing anonymous's query[8218e7ed-b4a4-41ad-a1cc-6f82bf3d55bb]: RUNNING_STATE -> FINISHED_STATE, time taken: 0.002 seconds
23/04/10 20:25:23 ERROR SparkTBinaryFrontendService: Error fetching results:
org.apache.kyuubi.KyuubiSQLException: OperationHandle [8218e7ed-b4a4-41ad-a1cc-6f82bf3d55bb] failed to generate operation log
at org.apache.kyuubi.KyuubiSQLException$.apply(KyuubiSQLException.scala:69)
at org.apache.kyuubi.operation.OperationManager.$anonfun$getOperationLogRowSet$2(OperationManager.scala:146)
at scala.Option.getOrElse(Option.scala:189)
```
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4688 from cxzl25/op_log_catalog.
Closes#4688
8ebc0f570 [sychen] Fix the failure to read the operation log after executing Catalog and database operation
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
closed#1770
Support flink `varbinary` type in query operation
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4666 from yuruguo/support-flink-varbinary-type.
Closes#4666
e05675e03 [Ruguo Yu] Support flink varbinary type in query operation
Authored-by: Ruguo Yu <jiang7chengzitc@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close#4522
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4648 from lsm1/fix/kyuubi_4522.
Closes#4522
e06046899 [senmiaoliu] use foreach
bd83d6623 [senmiaoliu] spilt narmalizedConf
4d8445aac [senmiaoliu] avoid sort
eda34d480 [senmiaoliu] use catalog first
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Due to the Py4JServer initiating with a non-daemon thread, there is a possibility of it impeding the engine's termination. Therefore, it is imperative to manually terminate the Py4JServer during engine shutdown.
```
"Thread-23" #96 prio=5 os_prio=0 cpu=7.93ms elapsed=187532.67s tid=0x00007fee840cf000 nid=0x8f runnable [0x00007fedca6bf000]
java.lang.Thread.State: RUNNABLE
at java.net.PlainSocketImpl.socketAccept(java.base11.0.16/Native Method)
at java.net.AbstractPlainSocketImpl.accept(java.base11.0.16/Unknown Source)
at java.net.ServerSocket.implAccept(java.base11.0.16/Unknown Source)
at java.net.ServerSocket.accept(java.base11.0.16/Unknown Source)
at py4j.GatewayServer.run(GatewayServer.java:685)
at java.lang.Thread.run(java.base11.0.16/Unknown Source)
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4644 from cfmcgrady/pyserver-non-daemon.
Closes#4644
d4f1a57a6 [Fu Chen] synchronized
cdc9630a7 [Fu Chen] shutdown Py4JServer
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
Followup #1704, support flink `time` type in query operation
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4635 from yuruguo/support-flink-time-type.
Closes#4635
9f9a3e72d [Ruguo Yu] [Kyuubi #1704] Support flink time type in query operation
Authored-by: Ruguo Yu <jiang7chengzitc@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As discussed before, Kyuubi is going to support the latest 3 Flink versions, and to reduce the complexity of supporting Flink 1.17 https://github.com/apache/kyuubi/pull/4368, we are going to remove support Flink 1.14 first.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4588 from pan3793/rm-flink-1.14.
Closes#4387
97d263324 [Cheng Pan] Remove support for Flink 1.14
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4541 from turboFei/expose.
Closes#4541
f882b4dda [fwang12] engine register attributes
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
- Make ChatGPT model ID configurable
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4558 from bowenliang123/chatgpt-model.
Closes#4558
63f8ee30d [liangbowen] nit
3012ccaaa [liangbowen] make chatgpt model configurable
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- use Java SDK `openai-java` for ChatGPT which is popular and listed in official website, https://github.com/TheoKanning/openai-java
- Focus on lifecycle in ChatGPTProvider, and prevent handling lower-level concepts in details, like POJO mapping, HTTP request handling.
- follow the changes from upstream changes from OpenAI
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4556 from bowenliang123/chatgpt-third.
Closes#4556
ecf1e2cf6 [liangbowen] manually add `openai-gpt3-java:*` and its dependency to LICENSE-binary
53b8375a5 [liangbowen] refactor ChatGPTProvider to use `openai-java` SDK
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
Fix bug in flink 1.14 version, multiple executions lead to abnormal results
### _Why are the changes needed?_
Fix bug in flink 1.14 version, multiple executions lead to abnormal results
### _How was this patch tested?_
- [X] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [X] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4517 from waywtdcc/flink1.14_result_ok_error.
Closes#4517
96ce6129c [Cheng Pan] ut
1bd9d1e2f [Cheng Pan] nit
5e5bccc91 [Cheng Pan] Migrate Flink engine Java code to Scala
4afb02064 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
3d5dc64c5 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
c084864bd [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
954d76062 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
d63ec55f2 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
Lead-authored-by: Chao Chen <chenchao4@grgbanking.com>
Co-authored-by: chenchao4 <Chenchao123>
Co-authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- set authentication as default header in client construction instead of request construction
- handle response's status code in scala style
- transforming config's long value to int with `.intValue` instead of `asInstanceOf` casting
- fix var name to `response`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4554 from bowenliang123/chatgpt-http.
Closes#4554
114484a4d [liangbowen] httpclient improvement in ChatGPTProvider
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Support Chinese question
- Support proxy settings
- Support setting timeout
<img width="1228" alt="image" src="https://user-images.githubusercontent.com/3898450/225851246-8762a451-9743-4c1d-8a33-cc49a926dfec.png">
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4548 from cxzl25/chatgpt_followup.
Closes#4548
1d5715442 [Cheng Pan] Update externals/kyuubi-chat-engine/src/main/scala/org/apache/kyuubi/engine/chat/provider/ChatGPTProvider.scala
7add6a733 [Cheng Pan] Update externals/kyuubi-chat-engine/src/main/scala/org/apache/kyuubi/engine/chat/provider/ChatGPTProvider.scala
55974f298 [sychen] fix
2d360e102 [sychen] typo
19b5d0814 [sychen] doc
bdf8e29b6 [sychen] 1.utf8;2.proxy;timeout
Lead-authored-by: sychen <sychen@ctrip.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Introduce a brand new CHAT engine, it's supposed to support different backends, e.g. ChatGPT, 文心一言, etc.
This PR implements the following providers:
- ECHO, simply replies a welcome message.
- GPT: a.k.a ChatGPT, powered by OpenAI, which requires a API key for authentication. https://platform.openai.com/account/api-keys
Add the following configurations in `kyuubi-defaults.conf`
```
kyuubi.engine.chat.provider=[ECHO|GPT]
kyuubi.engine.chat.gpt.apiKey=<chat-gpt-api-key>
```
Open an ECHO beeline chat engine.
```
beeline -u 'jdbc:hive2://localhost:10009/?kyuubi.engine.type=CHAT;kyuubi.engine.chat.provider=ECHO'
```
```
Connecting to jdbc:hive2://localhost:10009/
Connected to: Kyuubi Chat Engine (version 1.8.0-SNAPSHOT)
Driver: Kyuubi Project Hive JDBC Client (version 1.7.0)
Beeline version 1.7.0 by Apache Kyuubi
0: jdbc:hive2://localhost:10009/> Hello, Kyuubi!;
+----------------------------------------+
| reply |
+----------------------------------------+
| This is ChatKyuubi, nice to meet you! |
+----------------------------------------+
1 row selected (0.397 seconds)
```
Open a ChatGPT beeline chat engine. (make sure your network can connect the open API and configure the API key)
```
beeline -u 'jdbc:hive2://localhost:10009/?kyuubi.engine.type=CHAT;kyuubi.engine.chat.provider=GPT'
```
<img width="1109" alt="image" src="https://user-images.githubusercontent.com/26535726/225813625-a002e6e2-3b0d-4194-b061-2e215d58ba94.png">
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4544 from pan3793/chatgpt.
Closes#4544
87bdebb6d [Cheng Pan] nit
f7dee18f3 [Cheng Pan] Update docs
9beb55162 [cxzl25] chat api (#1)
af38bdc7c [Cheng Pan] update docs
9aa6d83a6 [Cheng Pan] Initial implement Kyuubi Chat Engine
Lead-authored-by: Cheng Pan <chengpan@apache.org>
Co-authored-by: cxzl25 <cxzl25@users.noreply.github.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
see detail in KYUUBI #3436
Splitting it out of a giant PR https://github.com/apache/kyuubi/pull/4002 to perfect
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4459 from zwangsheng/3420.
Closes#3420
2fd9b3131 [zwangsheng] [KYUUBI #3420]Fouce on spark web ui
3fbee02b7 [zwangsheng] [KYUUBI #3420] With inter config and expose explicit conf
09841d17b [zwangsheng] [KYUUBI #3420] Fix style
b47c3e5d1 [zwangsheng] [KYUUBI #3420] Fix unit test
b3ab3e23b [zwangsheng] [KYUUBI #3420] Expose more spark engine info
69292abf4 [zwangsheng] [KYUUBI #3420] Using common test case
cf889b09b [zwangsheng] [KYUUBI #3420] Fix unit test
1a0ac582f [zwangsheng] [KYUUBI #3420] Fix style
daf41de2d [zwangsheng] [KYUUBI #4453] Add etcd test
ab1038369 [zwangsheng] [KYUUBI #3420 Add Spark Web UI Url in zk node]
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Flink 1.15 refactors the result fetching of insert statements and now `TableResult.await()` would block till the insert finishes. We could remove this line because the insert results are immediately available as other non-job statements.
Flink JIRA: https://issues.apache.org/jira/browse/FLINK-24461
Critical changes: https://github.com/apache/flink/pull/17441/files#diff-ec88f0e06d880b53e2f152113ab1a4240a820cbb7248815c5f9ecf9ab4fce4caR108
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4485 from link3280/KYUUBI-4446.
Closes#4446
256176c3b [Paul Lin] [KYUUBI #4446] Update comments
3cb982ca4 [Paul Lin] [KYUUBI #4446] Add comments
d4c194ee5 [Paul Lin] [KYUUBI #4446] Fix connections blocked by Flink insert statements
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
`GetTables` operation is too slow because it queries table details info one by one, but then only a table comment is used to construct a result row, which i think could be optional.
This PR add an optional config which can control this operation. By default, `GetTables` operation queries all message. Otherwise, `GetTables` operation just return table identifiers.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4444 from liaoyt/master.
Closes#4171
af5e60e36 [yeatsliao] rename config
0c9985e32 [yeatsliao] add doc
5e8687cb3 [yeatsliao] Supports ignore table comment when list all tables.
Authored-by: yeatsliao <liaoyt66066@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
#4412 follow up
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4422 from turboFei/align_session_id.
Closes#4412
319373296 [fwang12] save
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
1. get spark engine runtime version instead of compile version
2. moved `PySparkTests` from the module `kyuubi-spark-sql-engine` to `kyuubi-server` to ensure that the python progress loading library PYSPARK has the same version as the launched Spark engine. see https://github.com/apache/kyuubi/pull/4381#issuecomment-1442871106
### _How was this patch tested?_
Pass Github Action.
Closes#4381 from cfmcgrady/spark-3.4.0.
Closes#4381
2711f51b3 [Fu Chen] remove verify spark-3.4 binary
a93b6d13e [Fu Chen] mv PySparkTests and enabled
6d5aad537 [Fu Chen] fix style
2da641561 [Fu Chen] fix style
3c9e300ce [Fu Chen] spark compile version -> runtime version
a8e7b7481 [Fu Chen] unused import
6be502ca6 [Fu Chen] fix ut
c1a1e1a8e [Fu Chen] skip pyspark tests
0049c23b7 [Fu Chen] verify spark-3.4.0 binary
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4415 from turboFei/operation_handle_align.
Closes#4415
71721797a [fwang12] refactor
c8b667a89 [fwang12] refactor
d3fbf05f3 [fwang12] stmt handle
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4414 from turboFei/get_or_else.
Closes#4412
e7d45ef24 [fwang12] refactor
f8583ec94 [fwang12] use different handle for alive probe
33a776cf0 [fwang12] launch sync
967ae41fa [fwang12] [KYUUBI #4412][FOLLOWUP] Fallback to new engine session handle for UT
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Align the server session handle and engine session handle for Spark engine.
It make it easy to recovery the engine session in any kyuubi instance easy.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4412 from turboFei/server_engine_handle_align.
Closes#4412
a20e0f155 [fwang12] fix
9d590e38b [fwang12] fix
94267e583 [fwang12] save
7012c2bef [fwang12] align
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Currently, the SQL metrics are missing from the SQL UI tab, this is because we mistakenly bound QueryExecution in [PR-4392](https://github.com/apache/kyuubi/pull/4392), before this PR, it was `resultDF.queryExecution` that was bound to `SQLExecution.withNewExecutionId()`, But the executed Dataset is `resultDF.select(cols: _*)`, this PR passed the correct QueryExecution `resultDF.select(cols: _*).queryExecution` to solve this problem.
```sql
set kyuubi.operation.result.format=arrow;
select 1;
```
Before this PR:

After this PR:

### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4402 from cfmcgrady/arrow-metrics.
Closes#4402
e0cde3b1 [Fu Chen] fix style
b35cbfdc [Fu Chen] fix
542414ef [Fu Chen] make arrow-based query metrics trackable in SQL UI
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
If SessionManager tries to close a session, that was previously closed - it throws an error `org.apache.kyuubi.KyuubiSQLException: Invalid SessionHandle` which causes spark session exit with non-zero code.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4386 from hanna-liashchuk/catch-invalid-sessionhandle.
Closes#4267
bf364bad [Hanna Liashchuk] Show warning if SessionHandle is invalid
Authored-by: Hanna Liashchuk <g.liashchuk@temabit.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
1. this PR introduces a new configuration called `kyuubi.operation.result.arrow.timestampAsString`, when true, arrow-based rowsets will convert timestamp-type columns to strings for transmission.
2. `kyuubi.operation.result.arrow.timestampAsString` default setting to false for better transmission performance
3. the PR fixes timezone issue in arrow based result format described in #3958
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4326 from cfmcgrady/arrow-string-ts.
Closes#4326
38c7fc9b [Fu Chen] fix style
d864db00 [Fu Chen] address comment
b714b3ee [Fu Chen] revert externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/kyuubi/engine/spark/schema/RowSet.scala
6c4eb507 [Fu Chen] minor
289b6007 [Fu Chen] timstampAsString = false by default
78b7caba [Fu Chen] fix
f5601356 [Fu Chen] debug info
b8e4b288 [Fu Chen] fix ut
87c6f9ef [Fu Chen] update docs
86f6cb73 [Fu Chen] arrow based rowset timestamp as string
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- to avoid violation in Apache archives website's daily total download size quote, prevent repeatedly downloading engine archives by manual cache in actions
### _How was this patch tested?_
- [ ] Pass CI jobs and check cached engine archives
Closes#4348 from bowenliang123/cache-downloaded-archives.
Closes#4348
a9deeea4 [liangbowen] apply engine caching to all jobs in master
d253a497 [liangbowen] Merge commit '38eb74c26ebbdbb57aba51ad18c7e4a6bb9e1144' into cache-downloaded-archives
0cf2a759 [liangbowen] remove conditions for action
38eb74c2 [Bowen Liang] Merge branch 'master' into cache-downloaded-archives
105d507e [liangbowen] remove
c6542797 [liangbowen] extract `cache-engine-archives` action and cache engine archives
Lead-authored-by: liangbowen <liangbowen@gf.com.cn>
Co-authored-by: Bowen Liang <bowenliang@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
It can help to know the backend pressure if the exec pool is full.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4344 from turboFei/wait_queue.
Closes#4344
161e3808a [fwang12] nit
6d122e238 [fwang12] save
55a4b499d [fwang12] version
668ff8bfe [fwang12] save
9f56b98a8 [fwang12] save
a401771ec [fwang12] wait
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Some DBMS tools like DBeaver and HUE will call thrift meta api for listing catalogs, databases, and tables. The current implementation of `CatalogShim_v3_0#getSchemas` will call `listAllNamespaces` first and do schema pruning on the Spark driver, which may cause "permission denied" exception when HMS has permission control, like the ranger plugin.
This PR proposes to call HMS API(through v1 session catalog) directly for `spark_catalog`, to suppress the above issue.
```
2023-02-15 20:02:13.048 ERROR org.apache.kyuubi.server.KyuubiTBinaryFrontendService: Error getting schemas:
org.apache.kyuubi.KyuubiSQLException: Error operating GetSchemas: org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:Permission denied: user [user1] does not have [SELECT] privilege on [userdb1])
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:134)
at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:249)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.databaseExists(ExternalCatalogWithListener.scala:69)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.databaseExists(SessionCatalog.scala:294)
at org.apache.spark.sql.execution.datasources.v2.V2SessionCatalog.listNamespaces(V2SessionCatalog.scala:212)
at org.apache.kyuubi.engine.spark.shim.CatalogShim_v3_0.$anonfun$listAllNamespaces$1(CatalogShim_v3_0.scala:74)
at org.apache.kyuubi.engine.spark.shim.CatalogShim_v3_0.$anonfun$listAllNamespaces$1$adapted(CatalogShim_v3_0.scala:73)
at scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:293)
at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)
at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)
at scala.collection.TraversableLike.flatMap(TraversableLike.scala:293)
at scala.collection.TraversableLike.flatMap$(TraversableLike.scala:290)
at scala.collection.mutable.ArrayOps$ofRef.flatMap(ArrayOps.scala:198)
at org.apache.kyuubi.engine.spark.shim.CatalogShim_v3_0.listAllNamespaces(CatalogShim_v3_0.scala:73)
at org.apache.kyuubi.engine.spark.shim.CatalogShim_v3_0.listAllNamespaces(CatalogShim_v3_0.scala:90)
at org.apache.kyuubi.engine.spark.shim.CatalogShim_v3_0.getSchemasWithPattern(CatalogShim_v3_0.scala:118)
at org.apache.kyuubi.engine.spark.shim.CatalogShim_v3_0.getSchemas(CatalogShim_v3_0.scala:133)
at org.apache.kyuubi.engine.spark.operation.GetSchemas.runInternal(GetSchemas.scala:43)
at org.apache.kyuubi.operation.AbstractOperation.run(AbstractOperation.scala:164)
at org.apache.kyuubi.session.AbstractSession.runOperation(AbstractSession.scala:99)
at org.apache.kyuubi.engine.spark.session.SparkSessionImpl.runOperation(SparkSessionImpl.scala:78)
at org.apache.kyuubi.session.AbstractSession.getSchemas(AbstractSession.scala:150)
at org.apache.kyuubi.service.AbstractBackendService.getSchemas(AbstractBackendService.scala:83)
at org.apache.kyuubi.service.TFrontendService.GetSchemas(TFrontendService.scala:294)
at org.apache.kyuubi.shade.org.apache.hive.service.rpc.thrift.TCLIService$Processor$GetSchemas.getResult(TCLIService.java:1617)
at org.apache.kyuubi.shade.org.apache.hive.service.rpc.thrift.TCLIService$Processor$GetSchemas.getResult(TCLIService.java:1602)
at org.apache.kyuubi.shade.org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.kyuubi.shade.org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.kyuubi.service.authentication.TSetIpAddressProcessor.process(TSetIpAddressProcessor.scala:36)
at org.apache.kyuubi.shade.org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4336 from pan3793/list-schemas.
Closes#4336
9ece864c [Cheng Pan] fix
f71587e9 [Cheng Pan] Avoid listing all schemas for Spark session catalog on schema prunning
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
This PR proposes to use `org.apache.spark.sql.execution#toHiveString` to replace `org.apache.kyuubi.engine.spark.schema#toHiveString` to get consistent result w/ `spark-sql` and `STS`.
Because of [SPARK-32006](https://issues.apache.org/jira/browse/SPARK-32006), it only works w/ Spark 3.1 and above.
The patch takes effects on both thrift and arrow result format.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
```
➜ ~ beeline -u 'jdbc:hive2://0.0.0.0:10009/default'
Connecting to jdbc:hive2://0.0.0.0:10009/default
Connected to: Spark SQL (version 3.3.1)
Driver: Hive JDBC (version 2.3.9)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 2.3.9 by Apache Hive
0: jdbc:hive2://0.0.0.0:10009/default> select to_timestamp('2023-02-08 22:17:33.123456789');
+----------------------------------------------+
| to_timestamp(2023-02-08 22:17:33.123456789) |
+----------------------------------------------+
| 2023-02-08 22:17:33.123456 |
+----------------------------------------------+
1 row selected (0.415 seconds)
```
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4318 from pan3793/hive-string.
Closes#4316
ba9016f6 [Cheng Pan] nit
8be774b4 [Cheng Pan] nit
bd696fe3 [Cheng Pan] nit
b5cf051c [Cheng Pan] fix
dd6b7021 [Cheng Pan] test
63edd34d [Cheng Pan] nit
37cc70af [Cheng Pan] Fix python ut
c66ad22d [Cheng Pan] [KYUUBI #4316] Fix returned Timestamp values may lose precision
41d94445 [Cheng Pan] Revert "[KYUUBI #3958] Fix Spark session timezone format"
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close#4250
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4275 from df-Liu/fix_4250.
Closes#4250
723c4b745 [df_liu] [KYUUBI #4250] fix 1.16.1
0e151a408 [df_liu] [KYUUBI #4250] Bump Flink 1.16.1
Authored-by: df_liu <df_liu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
`kyuubi.operation.result.max.rows` does not take effect on incremental collect mode because of performance concerns, this PR updates the configuration docs to mention that.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4271 from pan3793/maxrow.
Closes#4271
29b290a3e [Cheng Pan] nit
3d2872352 [Cheng Pan] log
277ebb5ff [Cheng Pan] ifx
091511a91 [Cheng Pan] nit
f15fb2270 [Cheng Pan] nit
1a1259ef5 [Cheng Pan] nit
ba57a2660 [Cheng Pan] fix
0b58d8b1a [Cheng Pan] ut
74b59dcee [Cheng Pan] nit
230defbff [Cheng Pan] Increamental collect mode should respect kyuubi.operation.result.max.rows
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Note:
- No output changes to existed generated docs as in `settings.md` and `functions.md`.
Improvement:
- readability in Scala code for doc auto-generation, and easy to maintain docs in group of sections
- reline on markdown linting from `flexmark`, and reducing un-meaningful blank lines or alignment
- declaration over operation by replacing repeated usages of `newOutput` itself by elegantly wrapped `.line`,`.lines`and etc.
- less fragile and more handy for changing in a long single line, as now using auto margin stripping in `.line()` method
- reusable extracted licence and auto-generation hints
- more elegant and safer way to read and appending file content
- possible less memory footprint by apply operators to Stream instead of to ArrayBuffer
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4244 from bowenliang123/config-regen.
Closes#4244
3d90ad304 [liangbowen] make buffer private in MarkdownBuilder
8250a55f3 [liangbowen] remove licence.md
a4c7baf78 [liangbowen] add MarkdownBuilder.apply
248a046a4 [liangbowen] Improvement in auto-generated Markdown docs with MarkdownBuilder
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
To close#4218 .
This change ensures BI tools can list columns on Delta Lake tables in all schemas.
<img width="312" alt="image" src="https://user-images.githubusercontent.com/89149767/215793967-722eb5f9-ffe4-4ffb-b7f9-1ded06c146d7.png">
<img width="725" alt="image" src="https://user-images.githubusercontent.com/89149767/215794036-871f005f-1494-487d-90aa-1f99891177c2.png">
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4219 from nousot-cloud-guy/feature/delta-db-schema.
Closes#4218
569843213 [Alex Wiss-Wolferding] Reversing match order in getColumnsByCatalog.
a6d973a3e [Alex Wiss-Wolferding] Revert "[KYUUBI #1458] Delta lake table columns won't show up in DBeaver."
20337dc96 [Alex Wiss-Wolferding] Revert "Using DB and table name when checking Delta table schema."
f7e4675a7 [Alex Wiss-Wolferding] Using DB and table name when checking Delta table schema.
Authored-by: Alex Wiss-Wolferding <alex@nousot.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Show line number and assertion when verifying generated markdown files, e.g. `settings.md` from `AllKyuubiConfiguration`, for quicker locating the place and differences in files.
- updated hint message to `mvn clean test` instead of `mvn clean install` for faster verification or regeneration
Hints with line num as below if assertion fails in line comparison.
<img width="1121" alt="image" src="https://user-images.githubusercontent.com/1935105/215451115-813b90f0-9d9d-4ebd-974e-8a071424aa42.png">
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4212 from bowenliang123/markdown-verify-linenum.
Closes#4212
82791a88 [liangbowen] style
609c3b35 [liangbowen] update hints
ed889915 [liangbowen] nit
c676653b [liangbowen] updated hints of markdown generation for AllKyuubiConfiguration and KyuubiDefinedFunctionSuite
646832a0 [liangbowen] show line number and content of expected and got when verifying markdown files
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- to consolidate styles in markdown files from manual written or auto-generated
- apply markdown formatting rules with flexmark from [spotless-maven-plugin](https://github.com/diffplug/spotless/tree/main/plugin-maven#markdown) to *.md files in `/docs`
- use `flexmark` to format markdown generation in `TestUtils` of common module used by `AllKyuubiConfiguration` and `KyuubiDefinedFunctionSuite`, as the same way in `FlexmarkFormatterFunc ` of `spotless-maven-plugin` using with `COMMONMARK` as `FORMATTER_EMULATION_PROFILE` (https://github.com/diffplug/spotless/blob/maven/2.30.0/lib/src/flexmark/java/com/diffplug/spotless/glue/markdown/FlexmarkFormatterFunc.java)
- using `flexmark` of` 0.62.2`, as the last version requiring Java 8+ (checked from pom file and bytecode version)
```
<markdown>
<includes>
<include>docs/**/*.md</include>
</includes>
<flexmark></flexmark>
</markdown>
```
- Changes applied to markdown doc files,
- no style change or breakings in built docs by `make html`
- removal all the first blank in licences and comments to conform markdown style rules
- tables regenerated by flexmark following as in [GitHub Flavored Markdown](https://help.github.com/articles/organizing-information-with-tables/) (https://github.com/vsch/flexmark-java/wiki/Extensions#tables)
### _How was this patch tested?_
- [x] regenerate docs using `make html` successfully and check all the markdown pages available
- [x] regenerate `settings.md` and `functions.md` by `AllKyuubiConfiguration` and `KyuubiDefinedFunctionSuite`, and pass the checks by both themselves and spotless check via `dev/reformat`
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4200 from bowenliang123/markdown-formatting.
Closes#4200
1eeafce4 [liangbowen] revert minor changes in AllKyuubiConfiguration
4f892857 [liangbowen] use flexmark in markdown doc generation
8c978abd [liangbowen] changes on markdown files
a9190556 [liangbowen] apply markdown formatting rules with `spotless-maven-plugin` to markdown files with in `/docs`
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
Motivation: When the running result of scala code is very long, all the information will be printed to info, and it is not very elegant to print the result set to the info level.
Closes#4189 from imperio-wxm/master.
Closes#4189
3e0b7764 [wxmimperio] Scala repl output log level adjusted to debug
Authored-by: wxmimperio <wxmimperio@outlook.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As Kyuubi graduated as top level project, the setting page will be more often requested and should be increasingly reliable and readable with less grammar and spelling mistakes.
This PR is to
- correct mistakes in grammar, spelling, abbreviation and terminology
- with no config name or essential meanings changed
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4161 from bowenliang123/conf-grammar.
Closes#4161
038edfbea [liangbowen] nit
1ec073a4b [liangbowen] to JSON
4f5259a32 [liangbowen] to Prometheus
523855008 [liangbowen] to K8s
fc7a3a81e [liangbowen] to AUTO-GENERATED
da64f54fa [liangbowen] update
d54f9a528 [liangbowen] fix `comma separated` to `comma-separated`
f1d7cc1f1 [liangbowen] update
d84208844 [liangbowen] update
1b75f011c [liangbowen] correction of grammar and spelling mistakes
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Kent Yao <yao@apache.org>
### _Why are the changes needed?_
Support to execute Scala statement synchronized to prevent conflicts, because they share the same `spark.repl.class.outputDir`.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4150 from turboFei/lock_scala.
Closes#4150
f11f12a26 [fwang12] lock more
d7a9fe8ed [fwang12] remove conf
d4175827e [fwang12] update docs
c1524a7fc [fwang12] lock required
a6e663be7 [fwang12] lock scala
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Close https://github.com/apache/kyuubi/issues/4111, JDBC ExecuteStatement operation should contain operationLog
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4113 from Yikf/KYUUBI-4111.
Closes#4111
172852070 [Yikf] Operations without log fetch log should fetch empty instead of report an error
Authored-by: Yikf <yikaifei1@gmail.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
After some offline discussions, I propose to change the configuration key from`kyuubi.operation.result.codec` to `kyuubi.operation.result.format`.
### _How was this patch tested?_
Pass CI.
Closes#4075 from cfmcgrady/arrow-conf-rename.
Closes#4075
5ad45507 [Fu Chen] fix
214b43fd [Fu Chen] rename
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4069 from lightning-L/kyuubi-4020.
Closes#4020
97406ca0 [Tianlin Liao] [KYUUBI #4020] remove incubating from kyuubi source code
Authored-by: Tianlin Liao <tiliao@ebay.com>
Signed-off-by: ulysses-you <ulyssesyou@apache.org>
### _Why are the changes needed?_
This pr aims to suppress warnning of the maven-antrun-plugin echo;
before:
```log
[WARNING] [echo] unpacking netty jar
[WARNING] [echo] renaming netty native libraries
[WARNING] [echo] deleting META-INF/native-image folder
[WARNING] [echo] repackaging netty jar
```
after:
```log
[INFO] [echo] unpacking netty jar
[INFO] [echo] renaming netty native libraries
[INFO] [echo] deleting META-INF/native-image folder
[INFO] [echo] repackaging netty jar
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4050 from Yikf/echo.
Closes#4050
2729f7988 [Yikf] Suppress warnning of the maven-antrun-plugin echo
Authored-by: Yikf <yikaifei1@gmail.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Followup for #4035
Add `eventEnabled` method for KyuubiOperation and SparkOperation.
For `KyuubiOperation`, enable below operations as before
- ExecuteStatement
- BatchJobSubmission
For `SparkOperation`, disable
- GetTypeInfo
- because it is used by `KyuubiConnection::isValid` and might be called with interval to check session alive
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4046 from turboFei/post_event.
Closes#4035
d558d7706 [fwang12] event enabled
4926c8b56 [fwang12] event enabled
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Use `globalSparkContext` to simplify the code.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4041 from zwangsheng/improve/diagnostics_deploy_mode_for_k8s_cluster.
Closes#4038
9426944c [zwangsheng] [FOLLOW UP]Improve print diagnostics info in kubernetes cluster deploy-mode
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
For Spark On Kubernetes Cluster Deploy-Mode, spark will set `spark.submit.deployMode=client` and `spark.kubernetes.submitInDriver=true`.
Kyuubi print diagnostics about deploy-mode for spark sql engine should not only dependence on `spark.submit.deployMode`.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4038 from zwangsheng/improve/diagnostics_deploy_mode_for_k8s_cluster.
Closes#4038
5149a0be [zwangsheng] Improve Diagnostics Info in Kubernetes Cluster Mode Case
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Before, if the pyspark environment is not set up correctly,the python response was always `None`.
In this pr, fail if the session python worker process has been exited.
BTW: Filter the empty log.
<img width="1422" alt="image" src="https://user-images.githubusercontent.com/6757692/209502683-49aa9088-8686-4a54-b88c-85881a3fb089.png">
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4026 from turboFei/python_exec.
Closes#4026
499e19b54 [fwang12] more insights
17cefc02e [fwang12] Fail if the session python worker has been exited
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
1. wrap the code with correct delimiter
Before:
```
{"code":"spark.sparkContext.setJobGroup(07753dd9-804e-478f-b84f-bf0735732334, ..., true)","cmd":"run_code"}
```
After:
```
{"code":"spark.sparkContext.setJobGroup('07753dd9-804e-478f-b84f-bf0735732334', '...', True)","cmd":"run_code"}
```
2. using cancelJobGroup for pyspark
Before:
```
'SparkContext' object has no attribute 'clearJobGroup'
```
After:
Using SparkContext.cancelJobGroup
3. Simplify the internal python code and throw exception on failure
We can not trust the user code is formatted correctly and we shall ensure the internal python code is simple and correct to prevent code correctness and even cause result out of sequence.
Such as, the user code might be below(maybe user invoke executePython api)
```
spark.sql('123\'\n\b\t'
```
It is difficult to escape the user code and set the job description as the statement as.
So, in this pr, I simplify the job description, just record its statementId, user can check the original code from log or on UI I think.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4028 from turboFei/python_async_debug.
Closes#4028
51a4c5ea5 [fwang12] typo
6da88d1b3 [fwang12] code style
83f5a48f7 [fwang12] fail the internal python code
5f2db042c [fwang12] remove debug code
3a798cf6c [fwang12] Simplify the statement
c3b4640ca [fwang12] do not lock for close
009f66aaa [fwang12] add ReentrantLock for SessionPythonWorker run python code
39bd861a1 [fwang12] fix
4116dabbc [fwang12] job desc
f16c656fc [fwang12] escape
81db20ccb [fwang12] fix 'SparkContext' object has no attribute 'clearJobGroup'
985118e92 [fwang12] escape for python
f7250c114 [fwang12] revert withLocalProperties
13228f964 [fwang12] debug
e318c698a [fwang12] Revert "prevent timeout"
f81c605e0 [fwang12] prevent timeout
2ca5339e3 [fwang12] test
1390b0f21 [fwang12] remove not needed
26ee60275 [fwang12] remove not needed
93c08ff08 [fwang12] debug
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Bind python and SQL spark session, then the variables we set on the python side can be visited on the SQL side
After this PR, we can change the execution mode from python to sql by running
```python
spark.sql("SET kyuubi.operation.language=SQL").show()
```
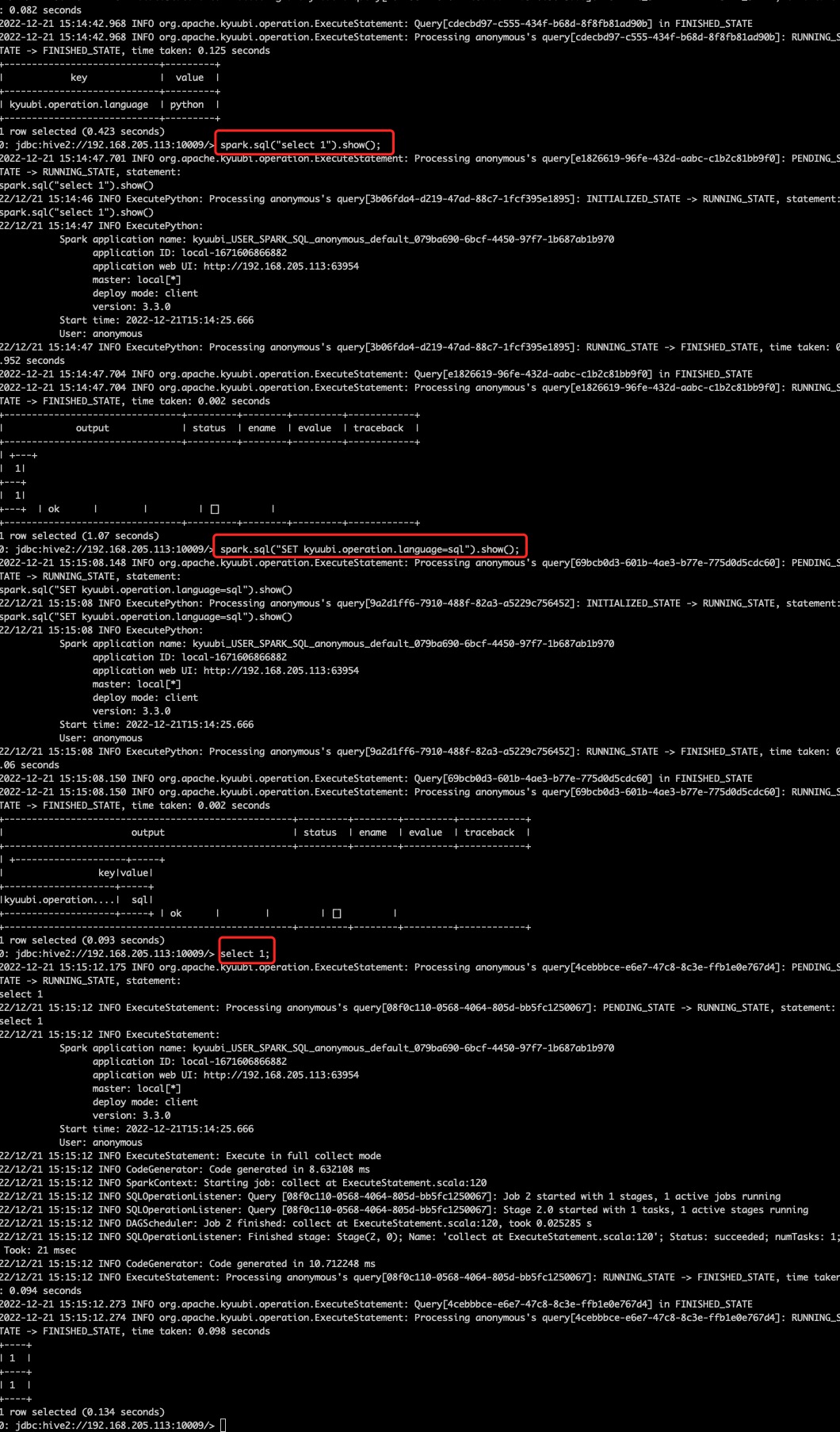
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4019 from cfmcgrady/binding-sql.
Closes#4019
2fd16a8e2 [Fu Chen] address comment
2136dfd64 [Fu Chen] fix style
cf8a612ee [Fu Chen] fix ut
57c592ed6 [Fu Chen] fix ut
fed7614dd [Fu Chen] binding python/sql spark session
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Fu Chen <cfmcgrady@gmail.com>
### _Why are the changes needed?_
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4018 from turboFei/python_async.
Closes#4018
2afe3979 [fwang12] move ut
0d9d2f10 [fwang12] only OK
46d14f4c [fwang12] add ut
0e3a0399 [fwang12] add ut
0f2eba5e [fwang12] add ut
e2718ab2 [fwang12] async python
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3915
This pr adds support for jdbc client detecting result set codec
1. in this PR, hints are added in the `TStatus.getInfoMessages()` to return, and the hints were added when the client retrieves the result set schema from the server
2. the hints mechanism is a general extension when we need to change the client behavior, e.g. adding support for result set compression
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3916 from cfmcgrady/arrow-detect-codec.
Closes#3915
90495c30 [Fu Chen] style
bbeada0a [Fu Chen] address comment
825bc0da [Fu Chen] minor refactor
d0a01ff7 [Fu Chen] address comment
08d21a1c [Fu Chen] fix ut
690126ce [Fu Chen] add hint ut
fd32a317 [Fu Chen] style
a1c2bb6c [Fu Chen] simplify KyuubiConnection
f81336d3 [Fu Chen] refactor
500e766f [Fu Chen] unused import
221bc928 [Fu Chen] fix ut
cf564d0a [Fu Chen] refactor
4b895e45 [Fu Chen] fix compile
3efcc335 [Fu Chen] clean up
95ea29c3 [Fu Chen] Client support detecting ResultSet codec
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Set `spark.driver.host` to ip instead of pod name when kyuubi on k8s submit spark with client deploy-mode.
When Kyuubi On Kubernetes submit spark with client deploy mode, spark driver will using kyuubi pod name as `spark.driver.host`, which can't be recognized by executors(Exclude kyuubi deployed as Statefulset + serivce case).
We have done this in #1596
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3914 from zwangsheng/k8s/set_driver_host_if_client.
Closes#3914
8fb89657 [zwangsheng] fix style
fc38143f [Binjie Yang] Merge branch 'master' into k8s/set_driver_host_if_client
4a313655 [zwangsheng] fix style
c61b7b8f [zwangsheng] fix
Lead-authored-by: zwangsheng <2213335496@qq.com>
Co-authored-by: Binjie Yang <52876270+zwangsheng@users.noreply.github.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
See more in #3590
For #3590 this PR is reverted, and author not reply for long time.
Fix this issue #3385 here.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3913 from zwangsheng/k8s/set_executor_pod_name_prefix.
Closes#3385
64b2c6b7 [zwangsheng] fix for review
b58ff3f5 [zwangsheng] add unit test
cb0ad9f1 [zwangsheng] fix
7a36292b [zwangsheng] init
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
The Spark session supports setting the time zone through `spark.sql.session.timeZone` and formatting according to the time zone, but `timestamp` does not use timezone, resulting in some incorrect results.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3958 from cxzl25/fix_session_timezone.
Closes#3958
3f2e375c [sychen] ut
e2fd90ac [sychen] session timezone format
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
If master is yarn and `spark.yarn.isPython` is true, spark will submit the builtin python lib(including pyspark.zip and py4j-*.zip) by default.
Support to use builtin spark python lib with `spark.yarn.isPython`.
- try to get the py4j lib from `PYTHONPATH` and set it as the value of `PY4J_PATH` for the python process
- if `spark.yarn.isPython` is true, SPARK_HOME is not needed to set
- get the PY4J_PATH if set in `execute_python.py`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
<img width="1724" alt="image" src="https://user-images.githubusercontent.com/6757692/205811759-b2bc3734-96c6-492c-875c-a5c273b9f58b.png">
<img width="1336" alt="image" src="https://user-images.githubusercontent.com/6757692/205823571-87830b6c-53a0-4f5f-bad3-c28d890bcaa3.png">
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3908 from turboFei/skip_spark_home_yarn_python.
Closes#3908
4901e849d [fwang12] add comments
2d500fe72 [fwang12] fix style
86c0c9650 [fwang12] modify python
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Fu Chen <cfmcgrady@gmail.com>
### _Why are the changes needed?_
Execute scala code now does not support async and query timeout.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3884 from cxzl25/async_scala.
Closes#3884
d231f682 [sychen] Execute scala code supports asynchronous and timeout
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
To prevent the error as below:
<img width="1385" alt="image" src="https://user-images.githubusercontent.com/6757692/205498862-e162cd49-8aed-4f42-b51d-12d0b49c4e2d.png">
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3898 from turboFei/python_log.
Closes#3898
f9ec7a02 [fwang12] Init operation log for ExecutePython to prevent error when fetching log
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
To remove the sensitive info and do not show it on UI as well.
<img width="1129" alt="image" src="https://user-images.githubusercontent.com/6757692/205428303-d1d3155c-3184-43ef-9b12-b3f7dfb6c3c6.png">
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3892 from turboFei/credes_show.
Closes#3892
eb50cd40 [fwang12] Do not show kyuubi.engine.credentials
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3839 .
The session signing feature is introduced with asymmetric encryption to prevent manipulation of session user identity or other key session elements, which could cause privilege leaking in scripts.
1. Server: Server creates and holds the singleton `keypair` for session signing if feature enabled
2. Server -> Engine: Server passes the `public key` to Engine when launching
3. Server -> Engine: Server generates session signing on `session user` when opening Kyuubi Session to Engine
4. Session -> Statement: Kyuubi session create Statement with context bringing `publickey` and `session user signature`
5. Engine: Engine verify `session user signature` with signature wherever necessary, e.g. in Authz for session name authentication.
ECDSA, with a shorter key length and better performance than RSA, is the supported asymmetric encryption in the initial implementation, which is widely supported on JDK7+ in HotSpot or OpenJDK. The session signature is generated with `SHA256withECDSA`.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3838 from bowenliang123/check-sessionuser.
Closes#3839
925eee47 [liangbowen] Revert "generalize setSparkLocalProperty"
d726d661 [liangbowen] generalize setSparkLocalProperty
470176db [liangbowen] allow setSparkLocalProperty to set value null
8f2a6e38 [liangbowen] nit
cb5891c9 [liangbowen] nit
edbe3c9c [liangbowen] only set to opensession conf when true, since kyuubi.session.user.sign.enabled is default to false
60546c82 [liangbowen] remove setting setSessionSigningPublicKey in KyuubiSessionManager
9a2a60dd [liangbowen] fix asserts
2e2a51b4 [liangbowen] nit
f37f4dd6 [Bowen Liang] Merge branch 'master' into check-sessionuser
9cd22003 [liangbowen] generalize illegalAccessWithUnverifiedUser in AuthZUtils
c1f27afa [liangbowen] generalize setSessionUserSign and clearSessionUserSign in SparkOperation
3683150f [liangbowen] update error message with `Invalid user identifier`
e143ea77 [liangbowen] fast fail for getting missing session configs
866fc821 [liangbowen] rename param name of base64 encoded pubkey with `Base64` suffix
280a95ef [liangbowen] refactor config key name to new class `ReservedKeys` in Authz
8592070e [liangbowen] nit
bf227e35 [liangbowen] remove redundant ut case
9ed14feb [liangbowen] remove redundant ut case
33a723d0 [liangbowen] add AuthzSessionSigningSuite with session user sign enabled
b77d53e3 [liangbowen] remove config setting in ut
2d56bd30 [liangbowen] remove config setting in ut
a25c1c0b [liangbowen] fail w/ AccessControlException, when kyuubi.session.user.sign.enabled is true and kyuubi.session.user is absent
c8a88fe9 [liangbowen] check not null of userPubKeyStr, userSign
c8bc590a [liangbowen] rename param to publicKeyBase64
b55beb60 [liangbowen] revert to use EC secp256k1 for compatibility
8acfd41d [liangbowen] nit
842b3698 [liangbowen] nit
983585bc [liangbowen] nit
d1003cd7 [liangbowen] nit
f9d6cfb6 [liangbowen] make generateKeyPair return (PrivateKey, PublicKey)
52eaaddc [liangbowen] add ut for SignUtils
b4a44687 [liangbowen] general keypair algorithm
7d40da49 [liangbowen] change to use secp192r1 curve for EC key pair for better performance
1ceed876 [liangbowen] sync settings.md with `false` default value
07d23602 [liangbowen] update ut
eec9d44a [liangbowen] move to _confIgnoreList
b7969446 [liangbowen] create SessionSigningSuite and add ut for 1. verifying user sign , 2. conf kyuubi.session.user.sign.enabled restriction
a50c71a3 [liangbowen] set kyuubi.session.user.sign.enabled to openEngineSessionConf
a2f1ed67 [liangbowen] set kyuubi.session.user.sign.enabled to _confRestrictList
5a12182e [liangbowen] make kyuubi.session.user.sign.enabled default to false, and removed from serverOnlyConfEntries
991a4569 [liangbowen] put SESSION_USER_SIGN_ENABLED in serverOnlyConfEntries
3e863af4 [liangbowen] nit
b232e5c0 [liangbowen] npe
13a046be [liangbowen] nit
2d2a6659 [liangbowen] nit
a0d4721d [liangbowen] move session signing keypair generation to KyuubiSessionImpl on server side. and rename config to KYUUBI_SESSION_SIGN_PUBLICKEY
ab430c39 [liangbowen] make generateKeyPair return Key pair and accept algorithm param
42ee2fe0 [liangbowen] nit
ce5f4af7 [liangbowen] refactoring session pubkey generation on server side (instead of engine side), and passing it to engine via OpenSession op
c2b9d897 [liangbowen] nit: rename to verifySignWithECDSA
d0b2cddb [liangbowen] nit
33a044d0 [liangbowen] add ut
2dc1f57b [liangbowen] change to use spark conf `kyuubi.session.user.sign.enabled` to decide whether verify kyuubi seesion user
b11ba5a5 [liangbowen] clear local prop `kyuubi.session.user.public.key` and `kyuubi.session.user.sign` after execution
2c8b4bf6 [liangbowen] move throwing AccessControlException inside verifyKyuubiSessionUser method
82f5c265 [liangbowen] update conf doc
7cf0d481 [liangbowen] rename config name to `kyuubi.session.user.sign.enabled`
cc2c3570 [liangbowen] typo: fix KYUUBI_SESSION_USER_PUBIC_KEY
bdec509d [liangbowen] update settings.md for config doc
2d00163a [liangbowen] nit
102561a8 [liangbowen] update
af99ea84 [liangbowen] move algorithmSpec to ecKeyPairGenerator
966a327e [liangbowen] update
41064712 [liangbowen] update
9d276799 [liangbowen] add config `kyuubi.session.user.verify.enabled` to control Whether to verify the integrity of session user name in Spark Authz
8a8840f6 [liangbowen] nit
bafd85e9 [liangbowen] replace RSA with ECDSA
2f0c87a5 [liangbowen] KeyPairGenerator init with new SecureRandom instance
7cb31204 [liangbowen] shorten the key size to 1024
5011cf49 [liangbowen] remove unused imports
045fd822 [liangbowen] add to SparkOperation for scala
ce6d394d [liangbowen] move generateRSAKeyPair and signWithRSA to SignUtils.scala
5f295792 [liangbowen] update
1d7f3191 [liangbowen] initial support for signing and verifying `kyuubi.session.user`
Lead-authored-by: liangbowen <liangbowen@gf.com.cn>
Co-authored-by: Bowen Liang <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
1. `mvn antrun:runbuild-info -pl kyuubi-common`
2. debug engine suite
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3847 from cxzl25/profile_jdbc_debug.
Closes#3847
e1c32067 [Cheng Pan] Merge branch 'master' into profile_jdbc_debug
f41d3cd9 [sychen] use jdbc-shaded
25b54b18 [sychen] use jdbc-shaded
dd23f864 [sychen] use kyuubi-hive-jdbc as default
79b0ffcb [sychen] add jdbc profile
Lead-authored-by: sychen <sychen@ctrip.com>
Co-authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Expose `kyuubi.operation.result.codec` to KyuubiConf
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3866 from cfmcgrady/arrow.
Closes#3794
2047f364 [Fu Chen] update
6f3fe24d [Fu Chen] rename
20748ca7 [Fu Chen] expose `kyuubi.operation.result.codec` to KyuubiConf
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Now the kill operation of the Spark engine ui will directly shut down, and the SQL that is being executed by the engine will fail.
We can support grace stop, first log off the engine from the znode, and then wait for the SQL execution to complete.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3792 from cxzl25/spark_ui_grace_stop.
Closes#3792
ebde958d [sychen] global
2676c193 [sychen] remove print session count
9acdf37a [sychen] address comment
25203ef9 [sychen] address comment
6e54ddb7 [sychen] engine ui grace stop
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Shaoyun Chen <csy@apache.org>
### _Why are the changes needed?_
Annotation PySparkTest introduced in <https://github.com/apache/incubator-kyuubi/pull/3832> is not working on trait `PySparkTests`.
In order to close#3805, transforming `PySparkTests` from trait to class, to enable PySparkTest for skipping tests in nighty builds correctly.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3846 from bowenliang123/3805-followup.
Closes#3805
6aacbea84 [liangbowen] make the type of`PySparkTests` from trait to class, in order to enable annotation @PySparkTest for skipping tests
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Fu Chen <cfmcgrady@gmail.com>
### _Why are the changes needed?_
Introduce code style check support for Maven's pom.xml with sortPom in spotless maven plugin.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3843 from bowenliang123/spotless-pom.
Closes#3842
3c654597 [liangbowen] apply to pom.xml
fd1536f7 [liangbowen] set expandEmptyElements to true
e498423f [liangbowen] apply spotless:apply to all pom.xml
e46bcfec [liangbowen] add pom style check support in spotless
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3840.
- bump scalafmt from 3.1.1 to 3.6.1
- bump spotless maven plugin from 2.41.1 to 2.72.2
- add `scalaMajorVersion` setting to spotless plugin configs
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3841 from bowenliang123/bump-scalafmt.
Closes#3840
1714012f [liangbowen] affect exist code with executing dev/reformat
9bafbb48 [liangbowen] change to scalaMajorVersion config name
56bf677d [liangbowen] bump scala fmt version to 3.6.1 and spotless maven plugin to 2.27.2
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3805 .
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3832 from bowenliang123/skip-pyspark-tests.
Closes#3805
02a59bfb [liangbowen] add maven.plugin.scalatest.exclude.tags=org.scalatest.tags.PySparkTest to pom instead
444b6f4e [liangbowen] introduce @PySparkTest annotation and skip PySparkTests for nightly builds
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3828.
Python code style checking support.
1. reuse Spotless maven plugin for Python style check
2. add style check to CI style workflow
3. add python linting support to `dev/reformat`. checks whether `black` installed in PATH.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3823 from bowenliang123/spotless-python.
Closes#3828
4a4de885 [liangbowen] simplify empty tags
0bb9ec7c [liangbowen] simplify empty tag in pom
9dd39531 [liangbowen] lint python code with black via spotless
f85020fa [liangbowen] typo
4c93bce0 [liangbowen] install python 3.9 first
23fc4b96 [liangbowen] ci install black version from added `spotless.python.black.version` property
73f746b0 [Bowen Liang] Update dev/reformat
46667a00 [liangbowen] update style.yml
9c20b434 [liangbowen] update style.yml
21017e5e [liangbowen] update style.yml
8272c0bc [liangbowen] add python style to style checking for CI
e102726c [liangbowen] add profile spotless in dev/reformat if black found in path
062e9bf2 [liangbowen] add python scan for spotless. add new profile `spotless-python` for python file path.
Lead-authored-by: liangbowen <liangbowen@gf.com.cn>
Co-authored-by: Bowen Liang <bowen.liang.123@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3820 .
To improve pyspark script support,
1. skip missing MagicNode implementation, since Jupyter and sparkmagic are not yet supported
2. add missing execute_reply_internal_error method
3. fix by calling clearOutputs before loop
4. ident lines and optimze unsed imports to conform python code style
5. Check Python major version , and exit on Python 2.x
6. fix name typo of `PythonResponse`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3819 from bowenliang123/imrove-pyspark.
Closes#3820
473b9952 [liangbowen] add return type to `connect_to_existed_gateway`
66927821 [liangbowen] remove unnecessary comments for magic code
21e1d7a2 [liangbowen] move pyspark path preparing to the top of exeuction_python
9751e094 [liangbowen] revert to use SparkSessionBuilder for session creation
c4f3ef55 [liangbowen] use `SparkSession._create_shell_session()` to create spark session
c2f65630 [liangbowen] delay importing kyuubi_util
5ed893cc [liangbowen] adding Exception to except, to prevent PEP 8: E203
029361a9 [liangbowen] ast module adaptation for >=3.8
00c75fda [liangbowen] remove legacy code for importing unicode
9f56a4f4 [liangbowen] add todo
1da708ed [liangbowen] fix typo for PythonResponse, and minor declaration improvement
910c62fb [liangbowen] remove MagicNode implementation since Jupyter and sparkmagic are not yet supported
5f15c257 [liangbowen] exit on python 2.x
86ff7d06 [liangbowen] ident lines to conform python code style
5634c5e0 [liangbowen] rename get_spark to get_spark_session, and optimize unused imports in kyuubi_util.py
9d3e1d0c [liangbowen] add missing MagicNode implementation
0ade1dbe [liangbowen] add missing execute_reply_internal_error method
aee205a5 [liangbowen] import cStringIO for fix package resolving problem
acdd4b16 [liangbowen] fix by calling clearOutputs before loop
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3818 .
- add `withLocalProperties` in `ExecutePython`
- set Spark local properties `kyuubi.session.user`, `kyuubi.statement.id`, `spark.scheduler.pool`, `spark.scheduler.pool` in withLocalProperties for other feature relied on it , e.g. Authz plugin.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3817 from bowenliang123/pyspark-sessionuser.
Closes#3818
86876391 [liangbowen] add local props `kyuubi.statement.id` , `spark.scheduler.pool`, `spark.scheduler.pool`. and setting job group
1c2bec4e [liangbowen] nit
276ad43b [liangbowen] generalize setSparkLocalProperties
00da08eb [liangbowen] nit
9f2cdaa5 [liangbowen] set session user to spark local property before execute python
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3807
1. Prefer the system env PYSPARK_DRIVER_PYTHON than PYSPARK_PYTHON for Python execute path, to fix the problem when submitting to YARN with client deploy mode.
2. Support get python path from Spark config
As the same order in Spark (<https://github.com/apache/spark/blob/v3.3.1/launcher/src/main/java/org/apache/spark/launcher/SparkSubmitCommandBuilder.java#L330>),
```
// 1. conf spark.pyspark.driver.python
// 2. conf spark.pyspark.python
// 3. environment variable PYSPARK_DRIVER_PYTHON
// 4. environment variable PYSPARK_PYTHON
// 5. python
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3808 from bowenliang123/3807-pysparkpython.
Closes#3807
567a81d6 [liangbowen] fix NoSuchElementException
8a22a15a [liangbowen] nit
adc25463 [liangbowen] Support get python path from Spark config. Prefer the system env PYSPARK_DRIVER_PYTHON than PYSPARK_PYTHON for Python execute path.
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Code of Conduct_
- [x] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct)
### _Search before asking_
- [x] I have searched in the [issues](https://github.com/apache/incubator-kyuubi/issues?q=is%3Aissue) and found no similar issues.
### _Describe the bug_
activeStages key is StageAttempt, and its value is StageInfo. The contains function defaults to 'containsValue'
### _Affects Version(s)_
master/1.7/1.6
### _Are you willing to submit PR?_
- [x] Yes. I can submit a PR independently to fix.
- [ ] Yes. I would be willing to submit a PR with guidance from the Kyuubi community to fix.
- [ ] No. I cannot submit a PR at this time.
Closes#3801 from lcy999/bug_1113.
Closes#3801
d6d96d30 [lcy999] active stage can't calculate the number of tasks correctly in sql operation listener
Authored-by: lcy999 <1501989483@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3795
Python ast api is changed after python 3.8, see https://github.com/ipython/ipython/pull/11593
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3797 from cfmcgrady/kyuubi-3795.
Closes#3795
44edcea1 [Fu Chen] Revert "debug python version"
f8171b00 [Fu Chen] Revert "print ga debug info"
16fde4ee [Fu Chen] debug python version
331602a8 [Fu Chen] print ga debug info
66eeb3fb [Fu Chen] python 3.8+ support
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close#3790
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3793 from df-Liu/flink_table.
Closes#3790
317434d2 [df_liu] flink table from
Authored-by: df_liu <df_liu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
When the Engine reaches the maximum running time, it can output the OpenSessionCount while waiting to exit
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3774 from lsm1/features/info_opensession_count.
Closes#3774
ae6e12a0 [senmiaoliu] info openSession count before engine shutdown because life time too long
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Expose the engine id when registering the service.
So that we can get more details about the engine when using `list engine` command.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3684 from turboFei/extra_info.
Closes#3684
afbcfdef3 [Fei Wang] refactor
513dd7234 [Fei Wang] split 2
ad3a6ac4f [Fei Wang] comments
cc51c5954 [Fei Wang] fix ut
32e31618a [Fei Wang] check engine id
202bbdb68 [Fei Wang] refactor to details
c5c153b8d [Fei Wang] render extra info
d2642cc8a [Fei Wang] save
1da67c258 [Fei Wang] dto
724ac3af4 [Fei Wang] save
c16c15988 [Fei Wang] expose engine id
e91a61e5a [Fei Wang] save
e38bb0b93 [Fei Wang] save
b1c158ba8 [Fei Wang] parse extra info
Authored-by: Fei Wang <fwang12@ebay.com>
Signed-off-by: Fei Wang <fwang12@ebay.com>
### _Why are the changes needed?_
fix#3730
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3731 from jiaoqingbo/kyuubi3730.
Closes#3730
94e5a871 [jiaoqingbo] [KYUUBI #3730] Change the parameter annotation of the runRemoveJarOperation method to Remove-jar operation instead of Add-jar operation
Authored-by: jiaoqingbo <1178404354@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
fix#3727
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3729 from jiaoqingbo/kyuubi3727.
Closes#3727
cb494c82 [jiaoqingbo] [KYUUBI #3727] Extract the common variables of GetTables in flink and spark to ResultSetSchemaConstant
Authored-by: jiaoqingbo <1178404354@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
fix#3732
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3733 from jiaoqingbo/kyuubi3732.
Closes#3732
1b1625b0 [jiaoqingbo] [KYUUBI #3732] Add logic for judging flink version in AddJarOperation and ShowJarsOperation
Authored-by: jiaoqingbo <1178404354@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3714 from hddong/use-ServicesResourceTransformer.
Closes#3714
d4c0ed27 [hongdongdong] Use ServicesResourceTransformer to concatenating service entries
Authored-by: hongdongdong <hongdd@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Fix https://github.com/apache/incubator-kyuubi/issues/3711
PlanOnly should output engine logs to log files so that they can be pulled from the front end.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3712 from Yikf/planOnly-log-out.
Closes#3711
8469de9a [Yikf] planOnly should output engine logs to log files so that they can be pulled from the front end
Authored-by: Yikf <yikaifei1@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3671.
- fix assert message for '[SCHEMA_NOT_FOUND]' and '[TABLE_OR_VIEW_NOT_FOUND]'
- introduce SparkVersionUtil in kyuubi-common test for checking Spark version
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3676 from bowenliang123/3671-notfound.
Closes#3671
c505098f [Bowen Liang] update
a950abbf [Bowen Liang] fix typo
56464e84 [Bowen Liang] update SparkVersionUtil
2190a93e [Bowen Liang] fix assert message for '[SCHEMA_NOT_FOUND]' and '[TABLE_OR_VIEW_NOT_FOUND]', introduce SparkVersionUtil for checking spark version in kyuubi-common test
Authored-by: Bowen Liang <liangbowen@gf.com.cn>
Signed-off-by: ulysses-you <ulyssesyou@apache.org>
### _Why are the changes needed?_
In Spark, if Kubernetes executor pod is not conforming to Kubernetes naming conventions, a user gets the next error:
```
org.apache.kyuubi.KyuubiSQLException: org.apache.kyuubi.KyuubiSQLException: java.lang.IllegalArgumentException: 'kyuubi-connection-spark-sql-USER-8fc2847d-b65d-4a46-bb41-4a86385cb61c-988995839f29e15f' in spark.kubernetes.executor.podNamePrefix is invalid.
```
It can be fixed by manually setting 'spark.kubernetes.executor.podNamePrefix' in configurations, but since you cannot dynamically set a value for every user to contain their username, it will miss this essential information that helps to distinguish executors one from another. I suggest Kyuubi server adds this config automatically if it's not coming from user.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3590 from hanna-liashchuk/master.
Closes#3385
94613145 [Hanna Liashchuk] Fixed style check
4b2281ce [Hanna Liashchuk] Merged if clauses
2c52988d [hanna-liashchuk] Merge branch 'apache:master' into master
f397cdc7 [Hanna Liashchuk] Added if clause
8b91109c [Hanna Liashchuk] Added EpochMilli to the podNamePrefix
13e8fb53 [hanna-liashchuk] Merge branch 'apache:master' into master
dcef3e10 [Hanna Liashchuk] Set executor.podNamePrefix for k8s if missing
Lead-authored-by: Hanna Liashchuk <g.liashchuk@temabit.com>
Co-authored-by: hanna-liashchuk <47921651+hanna-liashchuk@users.noreply.github.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3635 .
- change test suits to to use Utils.createTempDir of kyuubi-common module to create temp dir with delete on exit to prevent disk usage leaking
- change signature Utils.createTempDir by making `prefix` param from second place to the first, to make it friendly to use without repeating param name itself. The name`prefix` is more closer to Java's style in `Files.createTempDirectory`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3660 from bowenliang123/3635-deletetmp.
Closes#3635
8947fb0f [Bowen Liang] remove unused imports
c06769d4 [Bowen Liang] nit
dac266c9 [Bowen Liang] - change test suits to to use Utils.createTempDir of kyuubi-common module to create temp dir with delete on exit to prevent disk usage leaking - change signature Utils.createTempDir by making prefix param from second place to the first, to make it friendly to use without repeating param name itself. The nameprefix is more closer to Java's style in Files.createTempDirectory
Authored-by: Bowen Liang <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Fix#3627.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
manual test, and the class not found error is gone.
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3630 from pan3793/jetty.
Closes#3627
bf9e4f9b [Cheng Pan] private
f6c496f6 [Cheng Pan] nit
25a7c8cf [Cheng Pan] [KYUUBI #3627] Support vanilla Jetty for Spark packaged by sbt
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#3635 .
- change test suits to to use Utils.createTempDir of kyuubi-common module to create temp dir with delete on exit to prevent disk usage leaking
- change signature Utils.createTempDir by making `prefix` param from second place to the first, to make it friendly to use without repeating param name itself. The name`prefix` is more closer to Java's style in `Files.createTempDirectory`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3636 from bowenliang123/3635-tempdir.
Closes#3635
5f84a16f [Bowen Liang] nit
b82a149f [Bowen Liang] rename `namePrefix` param to `prefix` of `Utils.createTempDir` method, and make it in first place
76d33143 [Bowen Liang] delete files on exit in test suits with Utils.createTempDir
Authored-by: Bowen Liang <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Now kyuubi will help set web ui port to 0 while scalaing up spark sql engine, which is good for the general situation, help avoid port conflicts.
But on k8s case, kyuubi should respect the user's default settings, here means web ui should be `4040`.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3600 from zwangsheng/improve/fix_spark_sql_engine_web_ui_on_k8s.
Closes#3600
0174e22f [zwangsheng] comment
ac2dbedc [zwangsheng] fix
1a2bff70 [zwangsheng] fix
bd4c35c2 [zwangsheng] fix
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
When Kyuubi runs outside of K8s, and w/o enhanced DNS infrastructure, Kyuubi can not access the Pod by using the hostname of Pod, it blocks the user to run Spark on K8s w/ cluster mode out-of-box.
Kyuubi provided a configuration `kyuubi.frontend.connection.url.use.hostname`, turn it off could address this issue, but we can not change the default value globally because of https://github.com/apache/incubator-kyuubi/issues/2266
To improve user experience, we can detect if the Driver is running inside the Pod, and if yes,
change `kyuubi.frontend.connection.url.use.hostname` default value to `false`.
Close#3578
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3597 from pan3793/k8s.
Closes#3597
8b411781 [Cheng Pan] doc
0df15e79 [Cheng Pan] Engine should prefer to use ip for registing on K8s cluster mode
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
fix#3504
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3516 from jiaoqingbo/kyuubi3504.
Closes#3504
93fba696 [jiaoqingbo] remove outdated comment
af3e6a16 [jiaoqingbo] code review
894877b7 [jiaoqingbo] code review
856b28fc [jiaoqingbo] code review
60876a95 [jiaoqingbo] [KYUUBI #3504] Extend JDBC URL to support catalog
Authored-by: jiaoqingbo <1178404354@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close https://github.com/apache/incubator-kyuubi/issues/3568#issue-1388744898
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3569 from zhaomin1423/fix_doris_type.
Closes#3568
f83cc481 [Min Zhao] fix style
d0447473 [Min Zhao] [KYUUBI #3568] [Bug] [Doris Engine] Fix return decimal, date, timestamp using string
Authored-by: Min Zhao <zhaomin1423@163.com>
Signed-off-by: Kent Yao <yao@apache.org>
### _Why are the changes needed?_
Close https://github.com/apache/incubator-kyuubi/issues/3566.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3570 from Yikf/shade-spark-engine.
Closes#3566
0290cbc9 [Yikf] shade zookeeper in spark-engine
Authored-by: Yikf <yikaifei1@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
#1322#2129
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3519 from cxzl25/flink_get_columns.
Closes#3519
ab81776f [sychen] add column size
efdf1b90 [sychen] indent
630e907a [sychen] refactor
48a79d5b [sychen] add ut
69763bd3 [sychen] GetColumns
8e5e6c51 [sychen] GetColumns
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Followup #3230
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3560 from df-Liu/flink_ddl.
Closes#3560
0dbdfb3f [df_liu] flink ddl
Authored-by: df_liu <df_liu@trip.com>
Signed-off-by: Shaoyun Chen <csy@apache.org>
### _Why are the changes needed?_
Fix the flaky test
```
- execute statement - select count *** FAILED ***
92 did not equal 100 (FlinkOperationSuite.scala:663)
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3521 from pan3793/flink-flaky.
Closes#3521
b0ad7e8a [Cheng Pan] Test: Fix flay test execute statement - select count
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Simplify test by using helper method `withJdbcStatement`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3556 from pan3793/followup.
Closes#3549
75103f85 [Cheng Pan] nit
449a2563 [Cheng Pan] [KYUUBI #3549][FOLLOWUP] Simplify test
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Flink engine now doesn't support query id. This PR fixes the problem.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3550 from link3280/KYUUBI-3549.
Closes#3549
4f583cbe [Paul Lin] Update externals/kyuubi-flink-sql-engine/src/main/scala/org/apache/kyuubi/engine/flink/operation/FlinkSQLOperationManager.scala
b8808d73 [Paul Lin] [KYUUBI #3549] Simplify code
a68bc59b [Paul Lin] [KYUUBI #3549] Fix typo in the comments
e6217db2 [Paul Lin] [KYUUBI #3549] Support query id in Flink engine
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
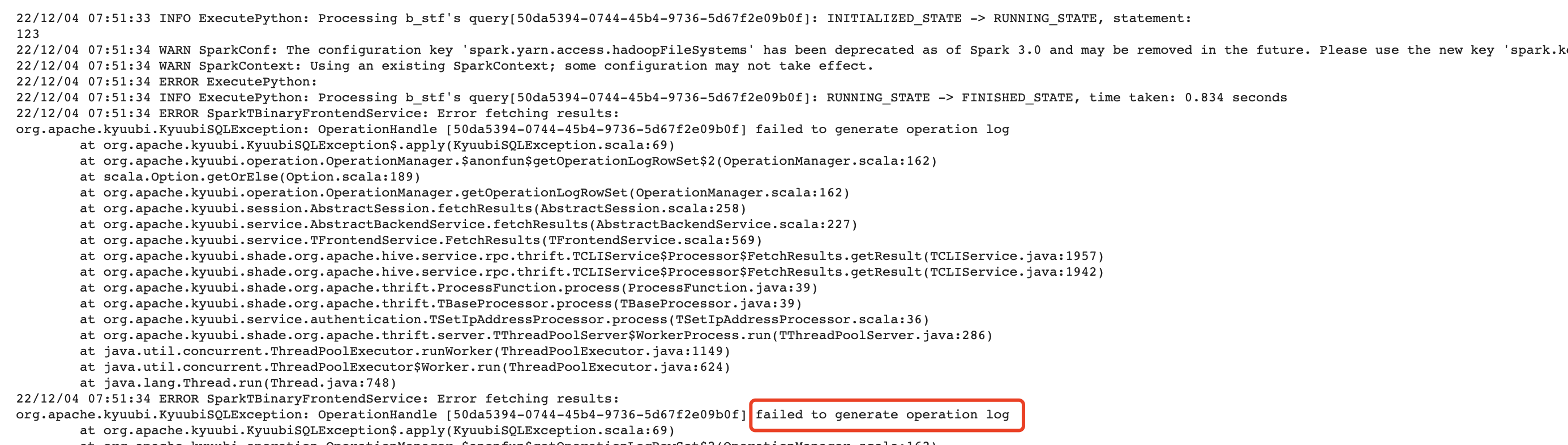{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}