[KYUUBI #3896] Support to get spark home and python exec from archive during runtime
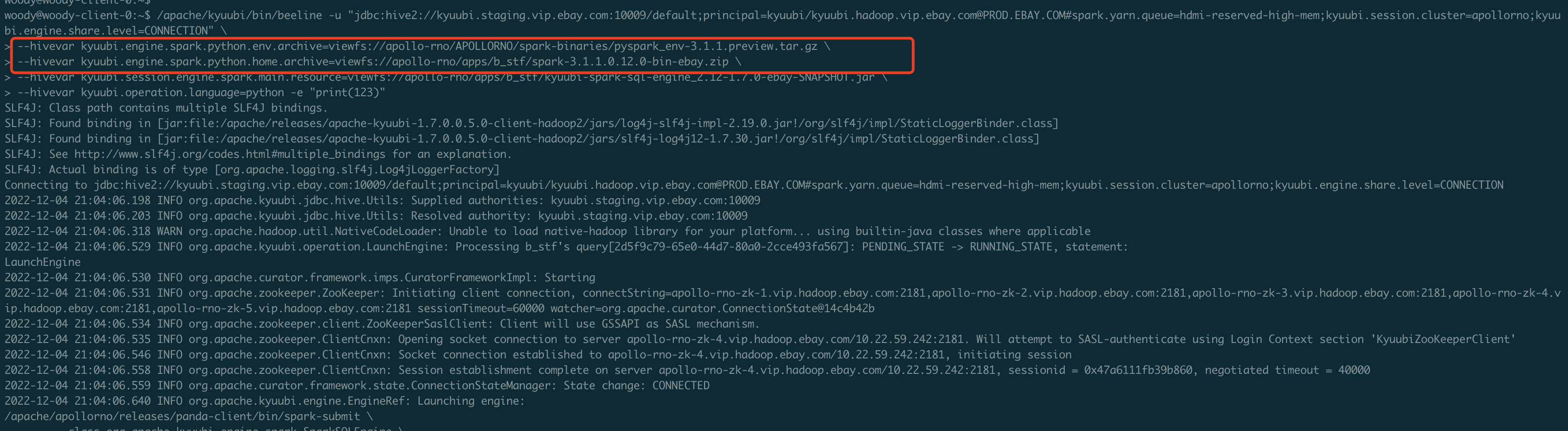
### _Why are the changes needed?_ Close #3896 Support to get spark home and python exec from spark python archive during runtime ### _How was this patch tested?_ - [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible - [x] Add screenshots for manual tests if appropriate <img width="1728" alt="image" src="https://user-images.githubusercontent.com/6757692/205547208-f4b06f2d-0175-4339-9d0e-aa638ed9aef9.png"> <img width="1661" alt="image" src="https://user-images.githubusercontent.com/6757692/205547253-cd8ef0c4-ef71-4d5e-a291-c4b7221c031e.png"> <img width="1440" alt="image" src="https://user-images.githubusercontent.com/6757692/205547483-60573ce6-e786-457e-9561-6b846ac53e42.png"> - [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request Closes #3899 from turboFei/python_archive. Closes #3896 4858e9ff [fwang12] use SparkFiles d58c4b23 [fwang12] respect user defined conf 1fc02476 [fwang12] runtime python exec fad40aed [fwang12] refactor b269a03e [fwang12] refactor -> do not add handle as alias 9920d762 [fwang12] refactor fragment 9c16290b [fwang12] support to load spark python archive runtime 6b41ca2b [fwang12] save Authored-by: fwang12 <fwang12@ebay.com> Signed-off-by: fwang12 <fwang12@ebay.com>
{kind=link}
{kind=link}
{kind=link}
This commit is contained in:
parent
f3600012f8
commit
b4b579d48e
@ -254,6 +254,9 @@ kyuubi.engine.share.level.sub.domain|<undefined>|(deprecated) - Using kyuu
|
||||
kyuubi.engine.share.level.subdomain|<undefined>|Allow end-users to create a subdomain for the share level of an engine. A subdomain is a case-insensitive string values that must be a valid zookeeper sub path. For example, for `USER` share level, an end-user can share a certain engine within a subdomain, not for all of its clients. End-users are free to create multiple engines in the `USER` share level. When disable engine pool, use 'default' if absent.|string|1.4.0
|
||||
kyuubi.engine.single.spark.session|false|When set to true, this engine is running in a single session mode. All the JDBC/ODBC connections share the temporary views, function registries, SQL configuration and the current database.|boolean|1.3.0
|
||||
kyuubi.engine.spark.event.loggers|SPARK|A comma separated list of engine loggers, where engine/session/operation etc events go.<ul> <li>SPARK: the events will be written to the spark listener bus.</li> <li>JSON: the events will be written to the location of kyuubi.engine.event.json.log.path</li> <li>JDBC: to be done</li> <li>CUSTOM: to be done.</li></ul>|seq|1.7.0
|
||||
kyuubi.engine.spark.python.env.archive|<undefined>|Portable python env archive used for Spark engine python language mode.|string|1.7.0
|
||||
kyuubi.engine.spark.python.env.archive.exec.path|bin/python|The python exec path under the python env archive.|string|1.7.0
|
||||
kyuubi.engine.spark.python.home.archive|<undefined>|Spark archive containing $SPARK_HOME/python directory, which is used to init session python worker for python language mode.|string|1.7.0
|
||||
kyuubi.engine.trino.event.loggers|JSON|A comma separated list of engine history loggers, where engine/session/operation etc events go.<ul> <li>JSON: the events will be written to the location of kyuubi.engine.event.json.log.path</li> <li>JDBC: to be done</li> <li>CUSTOM: to be done.</li></ul>|seq|1.7.0
|
||||
kyuubi.engine.trino.extra.classpath|<undefined>|The extra classpath for the trino query engine, for configuring other libs which may need by the trino engine |string|1.6.0
|
||||
kyuubi.engine.trino.java.options|<undefined>|The extra java options for the trino query engine|string|1.6.0
|
||||
|
||||
@ -19,19 +19,23 @@ package org.apache.kyuubi.engine.spark.operation
|
||||
|
||||
import java.io.{BufferedReader, File, FilenameFilter, FileOutputStream, InputStreamReader, PrintWriter}
|
||||
import java.lang.ProcessBuilder.Redirect
|
||||
import java.net.URI
|
||||
import java.nio.file.{Files, Path, Paths}
|
||||
import java.util.concurrent.atomic.AtomicBoolean
|
||||
import javax.ws.rs.core.UriBuilder
|
||||
|
||||
import scala.collection.JavaConverters._
|
||||
|
||||
import com.fasterxml.jackson.databind.ObjectMapper
|
||||
import com.fasterxml.jackson.module.scala.DefaultScalaModule
|
||||
import org.apache.commons.lang3.StringUtils
|
||||
import org.apache.spark.SparkFiles
|
||||
import org.apache.spark.api.python.KyuubiPythonGatewayServer
|
||||
import org.apache.spark.sql.{Row, RuntimeConfig}
|
||||
import org.apache.spark.sql.{Row, SparkSession}
|
||||
import org.apache.spark.sql.types.StructType
|
||||
|
||||
import org.apache.kyuubi.Logging
|
||||
import org.apache.kyuubi.config.KyuubiConf.{ENGINE_SPARK_PYTHON_ENV_ARCHIVE, ENGINE_SPARK_PYTHON_ENV_ARCHIVE_EXEC_PATH, ENGINE_SPARK_PYTHON_HOME_ARCHIVE}
|
||||
import org.apache.kyuubi.config.KyuubiReservedKeys.{KYUUBI_SESSION_USER_KEY, KYUUBI_STATEMENT_ID_KEY}
|
||||
import org.apache.kyuubi.engine.spark.KyuubiSparkUtil.SPARK_SCHEDULER_POOL_KEY
|
||||
import org.apache.kyuubi.operation.ArrayFetchIterator
|
||||
@ -137,6 +141,8 @@ case class SessionPythonWorker(
|
||||
}
|
||||
|
||||
object ExecutePython extends Logging {
|
||||
final val DEFAULT_SPARK_PYTHON_HOME_ARCHIVE_FRAGMENT = "__kyuubi_spark_python_home__"
|
||||
final val DEFAULT_SPARK_PYTHON_ENV_ARCHIVE_FRAGMENT = "__kyuubi_spark_python_env__"
|
||||
|
||||
private val isPythonGatewayStart = new AtomicBoolean(false)
|
||||
private val kyuubiPythonPath = Files.createTempDirectory("")
|
||||
@ -153,13 +159,13 @@ object ExecutePython extends Logging {
|
||||
}
|
||||
}
|
||||
|
||||
def createSessionPythonWorker(conf: RuntimeConfig): SessionPythonWorker = {
|
||||
def createSessionPythonWorker(spark: SparkSession, session: Session): SessionPythonWorker = {
|
||||
val pythonExec = StringUtils.firstNonBlank(
|
||||
conf.getOption("spark.pyspark.driver.python").orNull,
|
||||
conf.getOption("spark.pyspark.python").orNull,
|
||||
spark.conf.getOption("spark.pyspark.driver.python").orNull,
|
||||
spark.conf.getOption("spark.pyspark.python").orNull,
|
||||
System.getenv("PYSPARK_DRIVER_PYTHON"),
|
||||
System.getenv("PYSPARK_PYTHON"),
|
||||
"python3")
|
||||
getSparkPythonExecFromArchive(spark, session).getOrElse("python3"))
|
||||
|
||||
val builder = new ProcessBuilder(Seq(
|
||||
pythonExec,
|
||||
@ -169,7 +175,11 @@ object ExecutePython extends Logging {
|
||||
.split(File.pathSeparator)
|
||||
.++(ExecutePython.kyuubiPythonPath.toString)
|
||||
env.put("PYTHONPATH", pythonPath.mkString(File.pathSeparator))
|
||||
env.put("SPARK_HOME", sys.env.getOrElse("SPARK_HOME", defaultSparkHome()))
|
||||
env.put(
|
||||
"SPARK_HOME",
|
||||
sys.env.getOrElse(
|
||||
"SPARK_HOME",
|
||||
getSparkPythonHomeFromArchive(spark, session).getOrElse(defaultSparkHome)))
|
||||
env.put("PYTHON_GATEWAY_CONNECTION_INFO", KyuubiPythonGatewayServer.CONNECTION_FILE_PATH)
|
||||
logger.info(
|
||||
s"""
|
||||
@ -182,6 +192,36 @@ object ExecutePython extends Logging {
|
||||
SessionPythonWorker(startStderrSteamReader(process), startWatcher(process), process)
|
||||
}
|
||||
|
||||
def getSparkPythonExecFromArchive(spark: SparkSession, session: Session): Option[String] = {
|
||||
val pythonEnvArchive = spark.conf.getOption(ENGINE_SPARK_PYTHON_ENV_ARCHIVE.key)
|
||||
.orElse(session.sessionManager.getConf.get(ENGINE_SPARK_PYTHON_ENV_ARCHIVE))
|
||||
val pythonEnvExecPath = spark.conf.getOption(ENGINE_SPARK_PYTHON_ENV_ARCHIVE_EXEC_PATH.key)
|
||||
.getOrElse(session.sessionManager.getConf.get(ENGINE_SPARK_PYTHON_ENV_ARCHIVE_EXEC_PATH))
|
||||
pythonEnvArchive.map {
|
||||
archive =>
|
||||
var uri = new URI(archive)
|
||||
if (uri.getFragment == null) {
|
||||
uri = UriBuilder.fromUri(uri).fragment(DEFAULT_SPARK_PYTHON_ENV_ARCHIVE_FRAGMENT).build()
|
||||
}
|
||||
spark.sparkContext.addArchive(uri.toString)
|
||||
Paths.get(SparkFiles.get(uri.getFragment), pythonEnvExecPath)
|
||||
}.find(Files.exists(_)).map(_.toAbsolutePath.toFile.getCanonicalPath)
|
||||
}
|
||||
|
||||
def getSparkPythonHomeFromArchive(spark: SparkSession, session: Session): Option[String] = {
|
||||
val pythonHomeArchive = spark.conf.getOption(ENGINE_SPARK_PYTHON_HOME_ARCHIVE.key)
|
||||
.orElse(session.sessionManager.getConf.get(ENGINE_SPARK_PYTHON_HOME_ARCHIVE))
|
||||
pythonHomeArchive.map {
|
||||
archive =>
|
||||
var uri = new URI(archive)
|
||||
if (uri.getFragment == null) {
|
||||
uri = UriBuilder.fromUri(uri).fragment(DEFAULT_SPARK_PYTHON_HOME_ARCHIVE_FRAGMENT).build()
|
||||
}
|
||||
spark.sparkContext.addArchive(uri.toString)
|
||||
Paths.get(SparkFiles.get(uri.getFragment))
|
||||
}.find(Files.exists(_)).map(_.toAbsolutePath.toFile.getCanonicalPath)
|
||||
}
|
||||
|
||||
// for test
|
||||
def defaultSparkHome(): String = {
|
||||
val homeDirFilter: FilenameFilter = (dir: File, name: String) =>
|
||||
|
||||
@ -93,7 +93,7 @@ class SparkSQLOperationManager private (name: String) extends OperationManager(n
|
||||
ExecutePython.init()
|
||||
val worker = sessionToPythonProcess.getOrElseUpdate(
|
||||
session.handle,
|
||||
ExecutePython.createSessionPythonWorker(spark.conf))
|
||||
ExecutePython.createSessionPythonWorker(spark, session))
|
||||
new ExecutePython(session, statement, worker)
|
||||
case OperationLanguages.UNKNOWN =>
|
||||
spark.conf.unset(OPERATION_LANGUAGE.key)
|
||||
|
||||
@ -2297,6 +2297,28 @@ object KyuubiConf {
|
||||
.version("1.7.0")
|
||||
.fallbackConf(ENGINE_EVENT_LOGGERS)
|
||||
|
||||
val ENGINE_SPARK_PYTHON_HOME_ARCHIVE: OptionalConfigEntry[String] =
|
||||
buildConf("kyuubi.engine.spark.python.home.archive")
|
||||
.doc("Spark archive containing $SPARK_HOME/python directory, which is used to init session" +
|
||||
" python worker for python language mode.")
|
||||
.version("1.7.0")
|
||||
.stringConf
|
||||
.createOptional
|
||||
|
||||
val ENGINE_SPARK_PYTHON_ENV_ARCHIVE: OptionalConfigEntry[String] =
|
||||
buildConf("kyuubi.engine.spark.python.env.archive")
|
||||
.doc("Portable python env archive used for Spark engine python language mode.")
|
||||
.version("1.7.0")
|
||||
.stringConf
|
||||
.createOptional
|
||||
|
||||
val ENGINE_SPARK_PYTHON_ENV_ARCHIVE_EXEC_PATH: ConfigEntry[String] =
|
||||
buildConf("kyuubi.engine.spark.python.env.archive.exec.path")
|
||||
.doc("The python exec path under the python env archive.")
|
||||
.version("1.7.0")
|
||||
.stringConf
|
||||
.createWithDefault("bin/python")
|
||||
|
||||
val ENGINE_HIVE_EVENT_LOGGERS: ConfigEntry[Seq[String]] =
|
||||
buildConf("kyuubi.engine.hive.event.loggers")
|
||||
.doc("A comma separated list of engine history loggers, where engine/session/operation etc" +
|
||||
|
||||
Loading…
Reference in New Issue
Block a user