[KYUUBI #3782][PYSPARK] Initial support PySpark
### _Why are the changes needed?_ Close #3758 #3782 Limitations: - only support kyuubi beeline Examples: 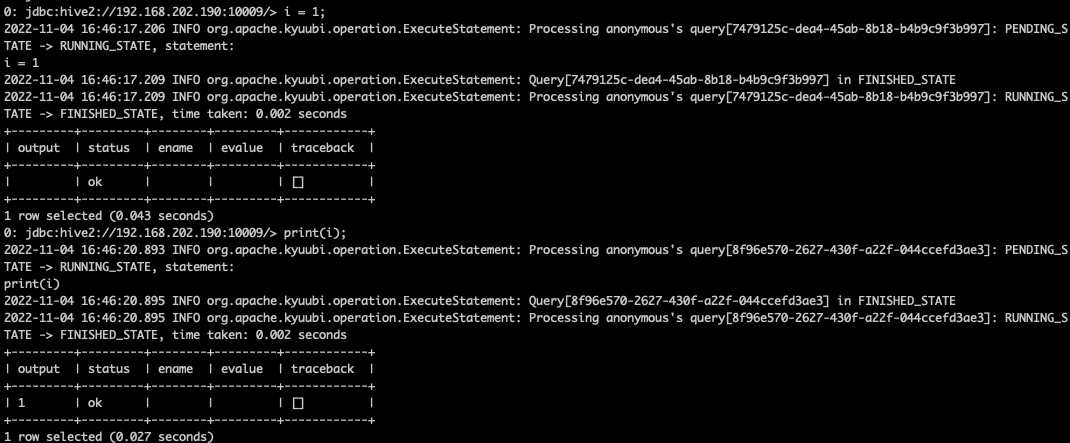 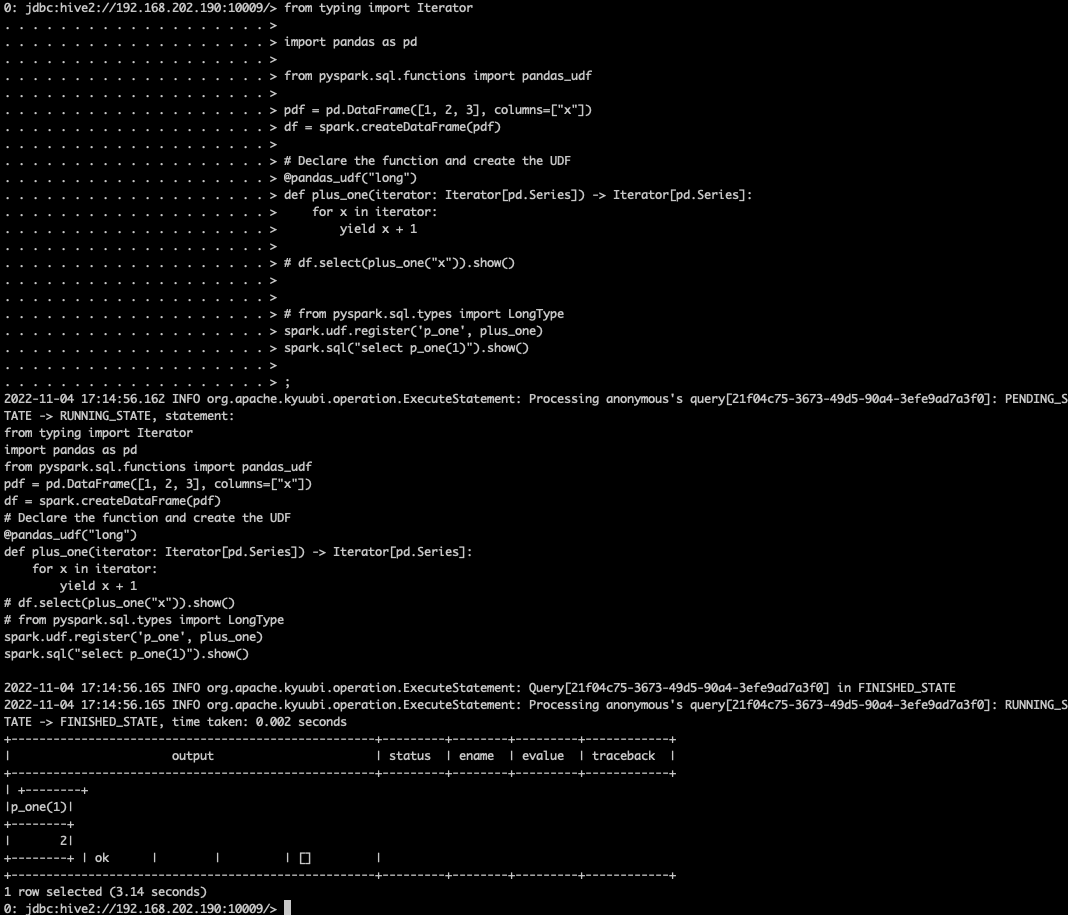 ### _How was this patch tested?_ - [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible - [ ] Add screenshots for manual tests if appropriate - [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request Closes #3762 from cfmcgrady/python-support. Closes #3782 83839a80 [Fu Chen] double check 3e4d6e3f [Fu Chen] multi-line ec56b3c2 [Fu Chen] address comment 4d204b68 [Fu Chen] fix style aa6aedfb [Fu Chen] address comment db786fe3 [Fu Chen] resolve conflict af0d1d9f [Fu Chen] revert kyuubi-hive-beeline/src/main/java/org/apache/hive/beeline/KyuubiCommands.java 8687a825 [Fu Chen] address comment 8954fed8 [Fu Chen] get conn_info_file from env 2952eb9f [Fu Chen] pythonExec a919f1ad [Fu Chen] fix ga 47543bf0 [Fu Chen] remove findspark dependency 003bf343 [Fu Chen] [GA] setup python 594e3cdc [Fu Chen] add ut 427e1e96 [Fu Chen] pass SPARK_HOME environment variable. 69dd7dfb [Fu Chen] license b8e44fd1 [Fu Chen] fix style df33efcd [Fu Chen] PySpark support Authored-by: Fu Chen <cfmcgrady@gmail.com> Signed-off-by: Cheng Pan <chengpan@apache.org>
{kind=link}
{kind=link}
This commit is contained in:
parent
78e80b8e01
commit
70590f71ef
4
.github/workflows/master.yml
vendored
4
.github/workflows/master.yml
vendored
@ -75,6 +75,10 @@ jobs:
|
||||
java-version: ${{ matrix.java }}
|
||||
cache: 'maven'
|
||||
check-latest: false
|
||||
- name: Setup Python
|
||||
uses: actions/setup-python@v4
|
||||
with:
|
||||
python-version: '3.9'
|
||||
- name: Build and test Kyuubi and Spark with maven w/o linters
|
||||
run: |
|
||||
TEST_MODULES="dev/kyuubi-codecov"
|
||||
|
||||
260
externals/kyuubi-spark-sql-engine/src/main/resources/python/execute_python.py
vendored
Normal file
260
externals/kyuubi-spark-sql-engine/src/main/resources/python/execute_python.py
vendored
Normal file
@ -0,0 +1,260 @@
|
||||
#
|
||||
# Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
# contributor license agreements. See the NOTICE file distributed with
|
||||
# this work for additional information regarding copyright ownership.
|
||||
# The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
# (the "License"); you may not use this file except in compliance with
|
||||
# the License. You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
from glob import glob
|
||||
import ast
|
||||
import sys
|
||||
import io
|
||||
import json
|
||||
import traceback
|
||||
import re
|
||||
import os
|
||||
|
||||
TOP_FRAME_REGEX = re.compile(r'\s*File "<stdin>".*in <module>')
|
||||
|
||||
global_dict = {}
|
||||
|
||||
class NormalNode(object):
|
||||
def __init__(self, code):
|
||||
self.code = compile(code, '<stdin>', 'exec', ast.PyCF_ONLY_AST, 1)
|
||||
|
||||
def execute(self):
|
||||
to_run_exec, to_run_single = self.code.body[:-1], self.code.body[-1:]
|
||||
|
||||
try:
|
||||
for node in to_run_exec:
|
||||
mod = ast.Module([node])
|
||||
code = compile(mod, '<stdin>', 'exec')
|
||||
exec(code, global_dict)
|
||||
|
||||
for node in to_run_single:
|
||||
mod = ast.Interactive([node])
|
||||
code = compile(mod, '<stdin>', 'single')
|
||||
exec(code, global_dict)
|
||||
except:
|
||||
# We don't need to log the exception because we're just executing user
|
||||
# code and passing the error along.
|
||||
raise ExecutionError(sys.exc_info())
|
||||
|
||||
class ExecutionError(Exception):
|
||||
def __init__(self, exc_info):
|
||||
self.exc_info = exc_info
|
||||
|
||||
class UnicodeDecodingStringIO(io.StringIO):
|
||||
def write(self, s):
|
||||
if isinstance(s, bytes):
|
||||
s = s.decode("utf-8")
|
||||
super(UnicodeDecodingStringIO, self).write(s)
|
||||
|
||||
def clearOutputs():
|
||||
sys.stdout.close()
|
||||
sys.stderr.close()
|
||||
sys.stdout = UnicodeDecodingStringIO()
|
||||
sys.stderr = UnicodeDecodingStringIO()
|
||||
|
||||
|
||||
def parse_code_into_nodes(code):
|
||||
nodes = []
|
||||
try:
|
||||
nodes.append(NormalNode(code))
|
||||
except SyntaxError:
|
||||
# It's possible we hit a syntax error because of a magic command. Split the code groups
|
||||
# of 'normal code', and code that starts with a '%'. possibly magic code
|
||||
# lines, and see if any of the lines
|
||||
# Remove lines until we find a node that parses, then check if the next line is a magic
|
||||
# line
|
||||
# .
|
||||
|
||||
# Split the code into chunks of normal code, and possibly magic code, which starts with
|
||||
# a '%'.
|
||||
|
||||
normal = []
|
||||
chunks = []
|
||||
for i, line in enumerate(code.rstrip().split('\n')):
|
||||
if line.startswith('%'):
|
||||
if normal:
|
||||
chunks.append('\n'.join(normal))
|
||||
normal = []
|
||||
|
||||
chunks.append(line)
|
||||
else:
|
||||
normal.append(line)
|
||||
|
||||
if normal:
|
||||
chunks.append('\n'.join(normal))
|
||||
|
||||
# Convert the chunks into AST nodes. Let exceptions propagate.
|
||||
for chunk in chunks:
|
||||
if chunk.startswith('%'):
|
||||
nodes.append(MagicNode(chunk))
|
||||
else:
|
||||
nodes.append(NormalNode(chunk))
|
||||
|
||||
return nodes
|
||||
|
||||
def execute_reply(status, content):
|
||||
msg = {
|
||||
'msg_type': 'execute_reply',
|
||||
'content': dict(
|
||||
content,
|
||||
status=status,
|
||||
)
|
||||
}
|
||||
return json.dumps(msg)
|
||||
|
||||
def execute_reply_ok(data):
|
||||
return execute_reply("ok", {
|
||||
"data": data,
|
||||
})
|
||||
|
||||
def execute_reply_error(exc_type, exc_value, tb):
|
||||
# LOG.error('execute_reply', exc_info=True)
|
||||
if sys.version >= '3':
|
||||
formatted_tb = traceback.format_exception(exc_type, exc_value, tb, chain=False)
|
||||
else:
|
||||
formatted_tb = traceback.format_exception(exc_type, exc_value, tb)
|
||||
for i in range(len(formatted_tb)):
|
||||
if TOP_FRAME_REGEX.match(formatted_tb[i]):
|
||||
formatted_tb = formatted_tb[:1] + formatted_tb[i + 1:]
|
||||
break
|
||||
|
||||
return execute_reply('error', {
|
||||
'ename': str(exc_type.__name__),
|
||||
'evalue': str(exc_value),
|
||||
'traceback': formatted_tb,
|
||||
})
|
||||
|
||||
def execute_request(content):
|
||||
try:
|
||||
code = content['code']
|
||||
except KeyError:
|
||||
return execute_reply_internal_error(
|
||||
'Malformed message: content object missing "code"', sys.exc_info()
|
||||
)
|
||||
|
||||
try:
|
||||
nodes = parse_code_into_nodes(code)
|
||||
except SyntaxError:
|
||||
exc_type, exc_value, tb = sys.exc_info()
|
||||
return execute_reply_error(exc_type, exc_value, None)
|
||||
|
||||
result = None
|
||||
|
||||
try:
|
||||
for node in nodes:
|
||||
result = node.execute()
|
||||
except ExecutionError as e:
|
||||
return execute_reply_error(*e.exc_info)
|
||||
|
||||
if result is None:
|
||||
result = {}
|
||||
|
||||
stdout = sys.stdout.getvalue()
|
||||
stderr = sys.stderr.getvalue()
|
||||
|
||||
clearOutputs()
|
||||
|
||||
output = result.pop('text/plain', '')
|
||||
|
||||
if stdout:
|
||||
output += stdout
|
||||
|
||||
if stderr:
|
||||
output += stderr
|
||||
|
||||
output = output.rstrip()
|
||||
|
||||
# Only add the output if it exists, or if there are no other mimetypes in the result.
|
||||
if output or not result:
|
||||
result['text/plain'] = output.rstrip()
|
||||
|
||||
return execute_reply_ok(result)
|
||||
|
||||
# import findspark
|
||||
# findspark.init()
|
||||
|
||||
spark_home = os.environ.get("SPARK_HOME", "")
|
||||
os.environ["PYSPARK_PYTHON"] = os.environ.get("PYSPARK_PYTHON", sys.executable)
|
||||
|
||||
# add pyspark to sys.path
|
||||
|
||||
if "pyspark" not in sys.modules:
|
||||
spark_python = os.path.join(spark_home, "python")
|
||||
try:
|
||||
py4j = glob(os.path.join(spark_python, "lib", "py4j-*.zip"))[0]
|
||||
except IndexError:
|
||||
raise Exception(
|
||||
"Unable to find py4j in {}, your SPARK_HOME may not be configured correctly".format(
|
||||
spark_python
|
||||
)
|
||||
)
|
||||
sys.path[:0] = sys_path = [spark_python, py4j]
|
||||
else:
|
||||
# already imported, no need to patch sys.path
|
||||
sys_path = None
|
||||
|
||||
import kyuubi_util
|
||||
spark = kyuubi_util.get_spark()
|
||||
global_dict['spark'] = spark
|
||||
|
||||
def main():
|
||||
sys_stdin = sys.stdin
|
||||
sys_stdout = sys.stdout
|
||||
sys_stderr = sys.stderr
|
||||
|
||||
if sys.version >= '3':
|
||||
sys.stdin = io.StringIO()
|
||||
else:
|
||||
sys.stdin = cStringIO.StringIO()
|
||||
|
||||
sys.stdout = UnicodeDecodingStringIO()
|
||||
sys.stderr = UnicodeDecodingStringIO()
|
||||
|
||||
stderr = sys.stderr.getvalue()
|
||||
print(stderr, file=sys_stderr)
|
||||
clearOutputs
|
||||
try:
|
||||
|
||||
while True:
|
||||
line = sys_stdin.readline()
|
||||
|
||||
if line == '':
|
||||
break
|
||||
elif line == '\n':
|
||||
continue
|
||||
|
||||
try:
|
||||
content = json.loads(line)
|
||||
except ValueError:
|
||||
# LOG.error('failed to parse message', exc_info=True)
|
||||
continue
|
||||
|
||||
if content['cmd'] == 'exit_worker':
|
||||
break
|
||||
|
||||
result = execute_request(content)
|
||||
print(result, file=sys_stdout)
|
||||
sys_stdout.flush()
|
||||
clearOutputs()
|
||||
finally:
|
||||
print("python worker exit", file=sys_stderr)
|
||||
sys.stdin = sys_stdin
|
||||
sys.stdout = sys_stdout
|
||||
sys.stderr = sys_stderr
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(main())
|
||||
87
externals/kyuubi-spark-sql-engine/src/main/resources/python/kyuubi_util.py
vendored
Normal file
87
externals/kyuubi-spark-sql-engine/src/main/resources/python/kyuubi_util.py
vendored
Normal file
@ -0,0 +1,87 @@
|
||||
#
|
||||
# Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
# contributor license agreements. See the NOTICE file distributed with
|
||||
# this work for additional information regarding copyright ownership.
|
||||
# The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
# (the "License"); you may not use this file except in compliance with
|
||||
# the License. You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
import atexit
|
||||
import os
|
||||
import sys
|
||||
import signal
|
||||
import shlex
|
||||
import shutil
|
||||
import socket
|
||||
import platform
|
||||
import tempfile
|
||||
import time
|
||||
from subprocess import Popen, PIPE
|
||||
|
||||
from py4j.java_gateway import java_import, JavaGateway, JavaObject, GatewayParameters
|
||||
from py4j.clientserver import ClientServer, JavaParameters, PythonParameters
|
||||
from pyspark.context import SparkContext
|
||||
from pyspark.serializers import read_int, write_with_length, UTF8Deserializer
|
||||
from pyspark.sql import SparkSession
|
||||
|
||||
|
||||
def connect_to_exist_gateway():
|
||||
conn_info_file = os.environ.get("PYTHON_GATEWAY_CONNECTION_INFO")
|
||||
if conn_info_file is None:
|
||||
raise SystemExit("the python gateway connection information file not found!")
|
||||
with open(conn_info_file, "rb") as info:
|
||||
gateway_port = read_int(info)
|
||||
gateway_secret = UTF8Deserializer().loads(info)
|
||||
if os.environ.get("PYSPARK_PIN_THREAD", "true").lower() == "true":
|
||||
gateway = ClientServer(
|
||||
java_parameters=JavaParameters(
|
||||
port=gateway_port,
|
||||
auth_token=gateway_secret,
|
||||
auto_convert=True),
|
||||
python_parameters=PythonParameters(
|
||||
port=0,
|
||||
eager_load=False))
|
||||
else:
|
||||
gateway = JavaGateway(
|
||||
gateway_parameters=GatewayParameters(
|
||||
port=gateway_port,
|
||||
auth_token=gateway_secret,
|
||||
auto_convert=True))
|
||||
# gateway.proc = proc
|
||||
|
||||
# Import the classes used by PySpark
|
||||
java_import(gateway.jvm, "org.apache.spark.SparkConf")
|
||||
java_import(gateway.jvm, "org.apache.spark.api.java.*")
|
||||
java_import(gateway.jvm, "org.apache.spark.api.python.*")
|
||||
java_import(gateway.jvm, "org.apache.spark.ml.python.*")
|
||||
java_import(gateway.jvm, "org.apache.spark.mllib.api.python.*")
|
||||
java_import(gateway.jvm, "org.apache.spark.resource.*")
|
||||
java_import(gateway.jvm, "org.apache.spark.sql.*")
|
||||
java_import(gateway.jvm, "org.apache.spark.sql.api.python.*")
|
||||
java_import(gateway.jvm, "org.apache.spark.sql.hive.*")
|
||||
java_import(gateway.jvm, "scala.Tuple2")
|
||||
|
||||
return gateway
|
||||
|
||||
def _get_exist_spark_context(self, jconf):
|
||||
"""
|
||||
Initialize SparkContext in function to allow subclass specific initialization
|
||||
"""
|
||||
return self._jvm.JavaSparkContext(self._jvm.org.apache.spark.SparkContext.getOrCreate(jconf))
|
||||
|
||||
def get_spark():
|
||||
SparkContext._initialize_context = _get_exist_spark_context
|
||||
gateway = connect_to_exist_gateway()
|
||||
SparkContext._ensure_initialized(gateway=gateway)
|
||||
spark = SparkSession.builder.master('local').appName('test').getOrCreate()
|
||||
return spark
|
||||
|
||||
@ -0,0 +1,240 @@
|
||||
/*
|
||||
* Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
* contributor license agreements. See the NOTICE file distributed with
|
||||
* this work for additional information regarding copyright ownership.
|
||||
* The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
* (the "License"); you may not use this file except in compliance with
|
||||
* the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
package org.apache.kyuubi.engine.spark.operation
|
||||
|
||||
import java.io.{BufferedReader, File, FilenameFilter, FileOutputStream, InputStreamReader, PrintWriter}
|
||||
import java.lang.ProcessBuilder.Redirect
|
||||
import java.nio.file.{Files, Path, Paths}
|
||||
import java.util.concurrent.atomic.AtomicBoolean
|
||||
|
||||
import scala.collection.JavaConverters._
|
||||
|
||||
import com.fasterxml.jackson.databind.ObjectMapper
|
||||
import com.fasterxml.jackson.module.scala.DefaultScalaModule
|
||||
import org.apache.spark.api.python.KyuubiPythonGatewayServer
|
||||
import org.apache.spark.sql.Row
|
||||
import org.apache.spark.sql.types.StructType
|
||||
|
||||
import org.apache.kyuubi.Logging
|
||||
import org.apache.kyuubi.operation.ArrayFetchIterator
|
||||
import org.apache.kyuubi.session.Session
|
||||
|
||||
class ExecutePython(
|
||||
session: Session,
|
||||
override val statement: String,
|
||||
worker: SessionPythonWorker) extends SparkOperation(session) {
|
||||
|
||||
override protected def resultSchema: StructType = {
|
||||
if (result == null || result.schema.isEmpty) {
|
||||
new StructType().add("output", "string")
|
||||
.add("status", "string")
|
||||
.add("ename", "string")
|
||||
.add("evalue", "string")
|
||||
.add("traceback", "array<string>")
|
||||
} else {
|
||||
result.schema
|
||||
}
|
||||
}
|
||||
|
||||
override protected def runInternal(): Unit = {
|
||||
val response = worker.runCode(statement)
|
||||
val output = response.map(_.content.getOutput()).getOrElse("")
|
||||
val status = response.map(_.content.status).getOrElse("UNKNOWN_STATUS")
|
||||
val ename = response.map(_.content.getEname()).getOrElse("")
|
||||
val evalue = response.map(_.content.getEvalue()).getOrElse("")
|
||||
val traceback = response.map(_.content.getTraceback()).getOrElse(Array.empty)
|
||||
iter =
|
||||
new ArrayFetchIterator[Row](Array(Row(output, status, ename, evalue, Row(traceback: _*))))
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
case class SessionPythonWorker(
|
||||
errorReader: Thread,
|
||||
pythonWorkerMonitor: Thread,
|
||||
workerProcess: Process) {
|
||||
private val stdin: PrintWriter = new PrintWriter(workerProcess.getOutputStream)
|
||||
private val stdout: BufferedReader =
|
||||
new BufferedReader(new InputStreamReader(workerProcess.getInputStream), 1)
|
||||
|
||||
def runCode(code: String): Option[PythonReponse] = {
|
||||
val input = ExecutePython.toJson(Map("code" -> code, "cmd" -> "run_code"))
|
||||
// scalastyle:off println
|
||||
stdin.println(input)
|
||||
// scalastyle:on
|
||||
stdin.flush()
|
||||
Option(stdout.readLine())
|
||||
.map(ExecutePython.fromJson[PythonReponse](_))
|
||||
}
|
||||
|
||||
def close(): Unit = {
|
||||
val exitCmd = ExecutePython.toJson(Map("cmd" -> "exit_worker"))
|
||||
// scalastyle:off println
|
||||
stdin.println(exitCmd)
|
||||
// scalastyle:on
|
||||
stdin.flush()
|
||||
stdin.close()
|
||||
stdout.close()
|
||||
errorReader.interrupt()
|
||||
pythonWorkerMonitor.interrupt()
|
||||
workerProcess.destroy()
|
||||
}
|
||||
}
|
||||
|
||||
object ExecutePython extends Logging {
|
||||
|
||||
// TODO:(fchen) get from conf
|
||||
val pythonExec =
|
||||
sys.env.getOrElse("PYSPARK_PYTHON", sys.env.getOrElse("PYSPARK_DRIVER_PYTHON", "python3"))
|
||||
private val isPythonGatewayStart = new AtomicBoolean(false)
|
||||
val kyuubiPythonPath = Files.createTempDirectory("")
|
||||
def init(): Unit = {
|
||||
if (!isPythonGatewayStart.get()) {
|
||||
synchronized {
|
||||
if (!isPythonGatewayStart.get()) {
|
||||
KyuubiPythonGatewayServer.start()
|
||||
writeTempPyFile(kyuubiPythonPath, "execute_python.py")
|
||||
writeTempPyFile(kyuubiPythonPath, "kyuubi_util.py")
|
||||
isPythonGatewayStart.set(true)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
def createSessionPythonWorker(): SessionPythonWorker = {
|
||||
val builder = new ProcessBuilder(Seq(
|
||||
pythonExec,
|
||||
s"${ExecutePython.kyuubiPythonPath}/execute_python.py").asJava)
|
||||
val env = builder.environment()
|
||||
val pythonPath = sys.env.getOrElse("PYTHONPATH", "")
|
||||
.split(File.pathSeparator)
|
||||
.++(ExecutePython.kyuubiPythonPath.toString)
|
||||
env.put("PYTHONPATH", pythonPath.mkString(File.pathSeparator))
|
||||
env.put("SPARK_HOME", sys.env.getOrElse("SPARK_HOME", defaultSparkHome()))
|
||||
env.put("PYTHON_GATEWAY_CONNECTION_INFO", KyuubiPythonGatewayServer.CONNECTION_FILE_PATH)
|
||||
logger.info(
|
||||
s"""
|
||||
|launch python worker command: ${builder.command().asScala.mkString(" ")}
|
||||
|environment:
|
||||
|${builder.environment().asScala.map(kv => kv._1 + "=" + kv._2).mkString("\n")}
|
||||
|""".stripMargin)
|
||||
builder.redirectError(Redirect.PIPE)
|
||||
val process = builder.start()
|
||||
SessionPythonWorker(startStderrSteamReader(process), startWatcher(process), process)
|
||||
}
|
||||
|
||||
// for test
|
||||
def defaultSparkHome(): String = {
|
||||
val homeDirFilter: FilenameFilter = (dir: File, name: String) =>
|
||||
dir.isDirectory && name.contains("spark-") && !name.contains("-engine")
|
||||
// get from kyuubi-server/../externals/kyuubi-download/target
|
||||
new File(getClass.getProtectionDomain.getCodeSource.getLocation.toURI).getPath
|
||||
.split("kyuubi-spark-sql-engine").flatMap { cwd =>
|
||||
val candidates = Paths.get(cwd, "kyuubi-download", "target")
|
||||
.toFile.listFiles(homeDirFilter)
|
||||
if (candidates == null) None else candidates.map(_.toPath).headOption
|
||||
}.find(Files.exists(_)).map(_.toAbsolutePath.toFile.getCanonicalPath)
|
||||
.getOrElse {
|
||||
throw new IllegalStateException("SPARK_HOME not found!")
|
||||
}
|
||||
}
|
||||
|
||||
private def startStderrSteamReader(process: Process): Thread = {
|
||||
val stderrThread = new Thread("process stderr thread") {
|
||||
override def run() = {
|
||||
val lines = scala.io.Source.fromInputStream(process.getErrorStream).getLines()
|
||||
lines.foreach(logger.error)
|
||||
}
|
||||
}
|
||||
stderrThread.setDaemon(true)
|
||||
stderrThread.start()
|
||||
stderrThread
|
||||
}
|
||||
|
||||
def startWatcher(process: Process): Thread = {
|
||||
val processWatcherThread = new Thread("process watcher thread") {
|
||||
override def run() = {
|
||||
val exitCode = process.waitFor()
|
||||
if (exitCode != 0) {
|
||||
logger.error(f"Process has died with $exitCode")
|
||||
}
|
||||
}
|
||||
}
|
||||
processWatcherThread.setDaemon(true)
|
||||
processWatcherThread.start()
|
||||
processWatcherThread
|
||||
}
|
||||
|
||||
private def writeTempPyFile(pythonPath: Path, pyfile: String): File = {
|
||||
val source = getClass.getClassLoader.getResourceAsStream(s"python/$pyfile")
|
||||
|
||||
val file = new File(pythonPath.toFile, pyfile)
|
||||
file.deleteOnExit()
|
||||
|
||||
val sink = new FileOutputStream(file)
|
||||
val buf = new Array[Byte](1024)
|
||||
var n = source.read(buf)
|
||||
|
||||
while (n > 0) {
|
||||
sink.write(buf, 0, n)
|
||||
n = source.read(buf)
|
||||
}
|
||||
source.close()
|
||||
sink.close()
|
||||
file
|
||||
}
|
||||
|
||||
val mapper = new ObjectMapper().registerModule(DefaultScalaModule)
|
||||
def toJson[T](obj: T): String = {
|
||||
mapper.writeValueAsString(obj)
|
||||
}
|
||||
def fromJson[T](json: String, clz: Class[T]): T = {
|
||||
mapper.readValue(json, clz)
|
||||
}
|
||||
|
||||
def fromJson[T](json: String)(implicit m: Manifest[T]): T = {
|
||||
mapper.readValue(json, m.runtimeClass).asInstanceOf[T]
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
case class PythonReponse(
|
||||
msg_type: String,
|
||||
content: PythonResponseContent)
|
||||
|
||||
case class PythonResponseContent(
|
||||
data: Map[String, String],
|
||||
ename: String,
|
||||
evalue: String,
|
||||
traceback: Array[String],
|
||||
status: String) {
|
||||
def getOutput(): String = {
|
||||
Option(data)
|
||||
.map(_.getOrElse("text/plain", ""))
|
||||
.getOrElse("")
|
||||
}
|
||||
def getEname(): String = {
|
||||
Option(ename).getOrElse("")
|
||||
}
|
||||
def getEvalue(): String = {
|
||||
Option(evalue).getOrElse("")
|
||||
}
|
||||
def getTraceback(): Array[String] = {
|
||||
Option(traceback).getOrElse(Array.empty)
|
||||
}
|
||||
}
|
||||
@ -40,12 +40,19 @@ class SparkSQLOperationManager private (name: String) extends OperationManager(n
|
||||
getConf.get(ENGINE_OPERATION_CONVERT_CATALOG_DATABASE_ENABLED)
|
||||
|
||||
private val sessionToRepl = new ConcurrentHashMap[SessionHandle, KyuubiSparkILoop]().asScala
|
||||
private val sessionToPythonProcess =
|
||||
new ConcurrentHashMap[SessionHandle, SessionPythonWorker]().asScala
|
||||
|
||||
def closeILoop(session: SessionHandle): Unit = {
|
||||
val maybeRepl = sessionToRepl.remove(session)
|
||||
maybeRepl.foreach(_.close())
|
||||
}
|
||||
|
||||
def closePythonProcess(session: SessionHandle): Unit = {
|
||||
val maybeProcess = sessionToPythonProcess.remove(session)
|
||||
maybeProcess.foreach(_.close)
|
||||
}
|
||||
|
||||
override def newExecuteStatementOperation(
|
||||
session: Session,
|
||||
statement: String,
|
||||
@ -82,6 +89,12 @@ class SparkSQLOperationManager private (name: String) extends OperationManager(n
|
||||
case OperationLanguages.SCALA =>
|
||||
val repl = sessionToRepl.getOrElseUpdate(session.handle, KyuubiSparkILoop(spark))
|
||||
new ExecuteScala(session, repl, statement)
|
||||
case OperationLanguages.PYTHON =>
|
||||
ExecutePython.init()
|
||||
val worker = sessionToPythonProcess.getOrElseUpdate(
|
||||
session.handle,
|
||||
ExecutePython.createSessionPythonWorker())
|
||||
new ExecutePython(session, statement, worker)
|
||||
case OperationLanguages.UNKNOWN =>
|
||||
spark.conf.unset(OPERATION_LANGUAGE.key)
|
||||
throw KyuubiSQLException(s"The operation language $lang" +
|
||||
|
||||
@ -97,5 +97,7 @@ class SparkSessionImpl(
|
||||
super.close()
|
||||
spark.sessionState.catalog.getTempViewNames().foreach(spark.catalog.uncacheTable)
|
||||
sessionManager.operationManager.asInstanceOf[SparkSQLOperationManager].closeILoop(handle)
|
||||
sessionManager.operationManager.asInstanceOf[SparkSQLOperationManager].closePythonProcess(
|
||||
handle)
|
||||
}
|
||||
}
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
/*
|
||||
* Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
* contributor license agreements. See the NOTICE file distributed with
|
||||
* this work for additional information regarding copyright ownership.
|
||||
* The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
* (the "License"); you may not use this file except in compliance with
|
||||
* the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
package org.apache.spark.api.python
|
||||
|
||||
import java.io.{DataOutputStream, File, FileOutputStream}
|
||||
import java.nio.charset.StandardCharsets.UTF_8
|
||||
import java.nio.file.Files
|
||||
|
||||
import org.apache.spark.SparkConf
|
||||
import org.apache.spark.internal.Logging
|
||||
|
||||
object KyuubiPythonGatewayServer extends Logging {
|
||||
|
||||
val CONNECTION_FILE_PATH = Files.createTempDirectory("") + "/connection.info"
|
||||
|
||||
def start(): Unit = {
|
||||
|
||||
val sparkConf = new SparkConf()
|
||||
val gatewayServer: Py4JServer = new Py4JServer(sparkConf)
|
||||
|
||||
gatewayServer.start()
|
||||
val boundPort: Int = gatewayServer.getListeningPort
|
||||
if (boundPort == -1) {
|
||||
logError(s"${gatewayServer.server.getClass} failed to bind; exiting")
|
||||
System.exit(1)
|
||||
} else {
|
||||
logDebug(s"Started PythonGatewayServer on port $boundPort")
|
||||
}
|
||||
|
||||
// Communicate the connection information back to the python process by writing the
|
||||
// information in the requested file. This needs to match the read side in java_gateway.py.
|
||||
val connectionInfoPath = new File(CONNECTION_FILE_PATH)
|
||||
val tmpPath = Files.createTempFile(
|
||||
connectionInfoPath.getParentFile().toPath(),
|
||||
"connection",
|
||||
".info").toFile()
|
||||
|
||||
val dos = new DataOutputStream(new FileOutputStream(tmpPath))
|
||||
dos.writeInt(boundPort)
|
||||
|
||||
val secretBytes = gatewayServer.secret.getBytes(UTF_8)
|
||||
dos.writeInt(secretBytes.length)
|
||||
dos.write(secretBytes, 0, secretBytes.length)
|
||||
dos.close()
|
||||
|
||||
if (!tmpPath.renameTo(connectionInfoPath)) {
|
||||
logError(s"Unable to write connection information to $connectionInfoPath.")
|
||||
System.exit(1)
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -0,0 +1,98 @@
|
||||
/*
|
||||
* Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
* contributor license agreements. See the NOTICE file distributed with
|
||||
* this work for additional information regarding copyright ownership.
|
||||
* The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
* (the "License"); you may not use this file except in compliance with
|
||||
* the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
package org.apache.kyuubi.engine.spark.operation
|
||||
|
||||
import java.io.PrintWriter
|
||||
import java.nio.file.Files
|
||||
|
||||
import scala.sys.process._
|
||||
|
||||
import org.apache.kyuubi.engine.spark.WithSparkSQLEngine
|
||||
import org.apache.kyuubi.operation.HiveJDBCTestHelper
|
||||
|
||||
trait PySparkTests extends WithSparkSQLEngine with HiveJDBCTestHelper {
|
||||
|
||||
test("pyspark support") {
|
||||
val code = "print(1)"
|
||||
val output = "1"
|
||||
runPySparkTest(code, output)
|
||||
}
|
||||
|
||||
test("pyspark support - multi-line") {
|
||||
val code =
|
||||
"""
|
||||
|for i in [1, 2, 3]:
|
||||
| print(i)
|
||||
|""".stripMargin
|
||||
val output = "1\n2\n3"
|
||||
runPySparkTest(code, output)
|
||||
}
|
||||
|
||||
test("pyspark support - call spark.sql") {
|
||||
val code =
|
||||
"""
|
||||
|spark.sql("select 1").show()
|
||||
|""".stripMargin
|
||||
val output =
|
||||
"""|+---+
|
||||
|| 1|
|
||||
|+---+
|
||||
|| 1|
|
||||
|+---+""".stripMargin
|
||||
runPySparkTest(code, output)
|
||||
}
|
||||
|
||||
private def runPySparkTest(
|
||||
pyCode: String,
|
||||
output: String): Unit = {
|
||||
checkPythonRuntimeAndVersion()
|
||||
withMultipleConnectionJdbcStatement()({ statement =>
|
||||
statement.executeQuery("SET kyuubi.operation.language=python")
|
||||
val resultSet = statement.executeQuery(pyCode)
|
||||
assert(resultSet.next())
|
||||
assert(resultSet.getString("output") === output)
|
||||
assert(resultSet.getString("status") === "ok")
|
||||
})
|
||||
}
|
||||
|
||||
private def checkPythonRuntimeAndVersion(): Unit = {
|
||||
val code =
|
||||
"""
|
||||
|import sys
|
||||
|print(".".join(map(str, sys.version_info[:2])))
|
||||
|""".stripMargin
|
||||
withTempPyFile(code) {
|
||||
pyfile: String =>
|
||||
val pythonVersion = s"python3 $pyfile".!!.toDouble
|
||||
assert(pythonVersion > 3.0, "required python version > 3.0")
|
||||
}
|
||||
}
|
||||
|
||||
private def withTempPyFile(code: String)(op: (String) => Unit): Unit = {
|
||||
val tempPyFile = Files.createTempFile("", ".py").toFile
|
||||
try {
|
||||
new PrintWriter(tempPyFile) {
|
||||
write(code)
|
||||
close
|
||||
}
|
||||
op(tempPyFile.getPath)
|
||||
} finally {
|
||||
Files.delete(tempPyFile.toPath)
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -40,7 +40,8 @@ import org.apache.kyuubi.operation.meta.ResultSetSchemaConstant._
|
||||
import org.apache.kyuubi.util.KyuubiHadoopUtils
|
||||
import org.apache.kyuubi.util.SparkVersionUtil.isSparkVersionAtLeast
|
||||
|
||||
class SparkOperationSuite extends WithSparkSQLEngine with HiveMetadataTests with SparkQueryTests {
|
||||
class SparkOperationSuite extends WithSparkSQLEngine with HiveMetadataTests with SparkQueryTests
|
||||
with PySparkTests {
|
||||
|
||||
override protected def jdbcUrl: String = getJdbcUrl
|
||||
override def withKyuubiConf: Map[String, String] = Map.empty
|
||||
|
||||
@ -1867,9 +1867,10 @@ object KyuubiConf {
|
||||
|
||||
object OperationLanguages extends Enumeration with Logging {
|
||||
type OperationLanguage = Value
|
||||
val SQL, SCALA, UNKNOWN = Value
|
||||
val PYTHON, SQL, SCALA, UNKNOWN = Value
|
||||
def apply(language: String): OperationLanguage = {
|
||||
language.toUpperCase(Locale.ROOT) match {
|
||||
case "PYTHON" => PYTHON
|
||||
case "SQL" => SQL
|
||||
case "SCALA" => SCALA
|
||||
case other =>
|
||||
|
||||
@ -21,7 +21,6 @@ import java.io.*;
|
||||
import java.sql.*;
|
||||
import java.util.*;
|
||||
import org.apache.hive.beeline.logs.KyuubiBeelineInPlaceUpdateStream;
|
||||
import org.apache.hive.common.util.HiveStringUtils;
|
||||
import org.apache.kyuubi.jdbc.hive.JdbcConnectionParams;
|
||||
import org.apache.kyuubi.jdbc.hive.KyuubiStatement;
|
||||
import org.apache.kyuubi.jdbc.hive.Utils;
|
||||
@ -45,7 +44,7 @@ public class KyuubiCommands extends Commands {
|
||||
|
||||
/** Extract and clean up the first command in the input. */
|
||||
private String getFirstCmd(String cmd, int length) {
|
||||
return cmd.substring(length).trim();
|
||||
return cmd.substring(length);
|
||||
}
|
||||
|
||||
private String[] tokenizeCmd(String cmd) {
|
||||
@ -97,7 +96,6 @@ public class KyuubiCommands extends Commands {
|
||||
}
|
||||
String[] cmds = lines.split(";");
|
||||
for (String c : cmds) {
|
||||
c = c.trim();
|
||||
if (!executeInternal(c, false)) {
|
||||
return false;
|
||||
}
|
||||
@ -261,10 +259,9 @@ public class KyuubiCommands extends Commands {
|
||||
beeLine.handleException(e);
|
||||
}
|
||||
|
||||
line = line.trim();
|
||||
List<String> cmdList = getCmdList(line, entireLineAsCommand);
|
||||
for (int i = 0; i < cmdList.size(); i++) {
|
||||
String sql = cmdList.get(i).trim();
|
||||
String sql = cmdList.get(i);
|
||||
if (sql.length() != 0) {
|
||||
if (!executeInternal(sql, call)) {
|
||||
return false;
|
||||
@ -511,7 +508,6 @@ public class KyuubiCommands extends Commands {
|
||||
@Override
|
||||
public String handleMultiLineCmd(String line) throws IOException {
|
||||
int[] startQuote = {-1};
|
||||
line = HiveStringUtils.removeComments(line, startQuote);
|
||||
Character mask =
|
||||
(System.getProperty("jline.terminal", "").equals("jline.UnsupportedTerminal"))
|
||||
? null
|
||||
@ -542,7 +538,6 @@ public class KyuubiCommands extends Commands {
|
||||
if (extra == null) { // it happens when using -f and the line of cmds does not end with ;
|
||||
break;
|
||||
}
|
||||
extra = HiveStringUtils.removeComments(extra, startQuote);
|
||||
if (!extra.isEmpty()) {
|
||||
line += "\n" + extra;
|
||||
}
|
||||
@ -554,13 +549,12 @@ public class KyuubiCommands extends Commands {
|
||||
// console. Used in handleMultiLineCmd method assumes line would never be null when this method is
|
||||
// called
|
||||
private boolean isMultiLine(String line) {
|
||||
line = line.trim();
|
||||
if (line.endsWith(beeLine.getOpts().getDelimiter()) || beeLine.isComment(line)) {
|
||||
return false;
|
||||
}
|
||||
// handles the case like line = show tables; --test comment
|
||||
List<String> cmds = getCmdList(line, false);
|
||||
return cmds.isEmpty() || !cmds.get(cmds.size() - 1).trim().startsWith("--");
|
||||
return cmds.isEmpty() || !cmds.get(cmds.size() - 1).startsWith("--");
|
||||
}
|
||||
|
||||
static class KyuubiLogRunnable implements Runnable {
|
||||
|
||||
6
pom.xml
6
pom.xml
@ -159,6 +159,7 @@
|
||||
<netty.version>4.1.73.Final</netty.version>
|
||||
<parquet.version>1.10.1</parquet.version>
|
||||
<prometheus.version>0.16.0</prometheus.version>
|
||||
<py4j.version>0.10.7</py4j.version>
|
||||
<ranger.version>2.3.0</ranger.version>
|
||||
<scalacheck.version>3.2.9.0</scalacheck.version>
|
||||
<scalatest.version>3.2.9</scalatest.version>
|
||||
@ -1621,6 +1622,11 @@
|
||||
<artifactId>kudu-client</artifactId>
|
||||
<version>${kudu.version}</version>
|
||||
</dependency>
|
||||
<dependency>
|
||||
<groupId>net.sf.py4j</groupId>
|
||||
<artifactId>py4j</artifactId>
|
||||
<version>${py4j.version}</version>
|
||||
</dependency>
|
||||
</dependencies>
|
||||
</dependencyManagement>
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user