### _Why are the changes needed?_
This PR aims to migrate the vanilla Zookeeper and Curator to the Kyuubi Shaded Zookeeper. It's the first step to adapting JDK 17.
There is a known issue [ZOOKEEPER-3779](https://issues.apache.org/jira/browse/ZOOKEEPER-3779) that Zookeeper 3.4 client can not run on JDK 14 and above, in https://github.com/apache/kyuubi-shaded/pull/5, we fixed this issue by a surgical.
With the above fixing, zk-3.4 and zk-3.6 clients both work well on JDK 17, we just randomly pick some cases to make sure zk-3.6 is tested
zk-3.4 client supports zk-3.4+ server, but zk-3.6 client only supports zk-3.5+ server; in the meanwhile, zk-3.4 is adopted widely, (CDH 5/6, HDP, EMR created before 2023).
We are sticky to zk-3.4 to ensure that Kyuubi can be out-of-box in the most existing Hadoop cluster but also provide zk-3.6 as an alternative(simply replace the kyuubi-shaded-zk-3.4 jar w/ kyuubi-shaded-zk-3.6, or build w/ -Pzookeeper-3.6) for users who concerns that zk-3.4 is EOL.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4852 from pan3793/shaded-zk.
Closes#4852
d960cc945 [Cheng Pan] remove staging repo
1b3622080 [Cheng Pan] Switch to Kyuubi Shaded Zookeeper
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Support Flink session idleness.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4862 from link3280/KYUUBI-4861.
Closes#4861
463d1bf9f [Paul Lin] [KYUUBI #4861] Fix class cast exception
882203157 [Paul Lin] [KYUUBI #4861] Improve code style
451403882 [Paul Lin] [KYUUBI #4861] Support Flink session idleness
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As title.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4832 from turboFei/scala_python_handle.
Closes#4415
a5a44dfa0 [fwang12] ut
eaf7f004f [fwang12] ut
c8d7a5c82 [fwang12] save
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Now we check the sparkContext.hadoopConfiguration to determine whether to apply HIVE_DELEGATION_TOKEN
Here is the method to create sparkContext hadoopConguration.
And it will add `__spark_hadoop_conf__.xml` to hadoop configuration resource.
```
/**
* Return an appropriate (subclass) of Configuration. Creating config can initialize some Hadoop
* subsystems.
*/
def newConfiguration(conf: SparkConf): Configuration = {
val hadoopConf = SparkHadoopUtil.newConfiguration(conf)
hadoopConf.addResource(SparkHadoopUtil.SPARK_HADOOP_CONF_FILE)
hadoopConf
}
```
```
/**
* Name of the file containing the gateway's Hadoop configuration, to be overlayed on top of the
* cluster's Hadoop config. It is up to the Spark code launching the application to create
* this file if it's desired. If the file doesn't exist, it will just be ignored.
*/
private[spark] val SPARK_HADOOP_CONF_FILE = "__spark_hadoop_conf__.xml"
```
<img width="1091" alt="image" src="https://github.com/apache/kyuubi/assets/6757692/f2a87a23-4565-4164-9eaa-5f7e166519de">
Per the code, this file is only created in yarn module.
#### Spark on yarn
after unzip `__spark_conf__.zip` in spark staging dir, there is a file named `__spark_hadoop_conf__.xml`.
```
grep hive.metastore.uris __spark_hadoop_conf__.xml
<property><name>hive.metastore.uris</name><value>thrift://*******:9083</value><source>programatically</source></property>
```
#### Spark on K8S
Seems for spark on k8s, there is no file named `__spark_hadoop_conf__.xml`
<img width="1580" alt="image" src="https://github.com/apache/kyuubi/assets/6757692/99de73d0-3519-4af3-8f0a-90967949ec0e">
<img width="875" alt="image" src="https://github.com/apache/kyuubi/assets/6757692/f7c477a5-23ca-4b25-8638-4b040b78899d">
We need to check the `hiveConf` instead of `hadoopConf`.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4835 from turboFei/hive_token.
Closes#4835
7657cbb11 [fwang12] hive conf
7c0af6789 [fwang12] save
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
As title.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4792 from turboFei/remove_unused.
Closes#4792
fe568af7e [fwang12] server conf
97f510020 [fwang12] save
c44e70a58 [fwang12] remove unused code
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
to adapt Spark 3.5
the signature of function `ArrowUtils#toArrowSchema` is changed in https://github.com/apache/spark/pull/40988 (since Spark3.5)
Spark 3.4 or previous
```scala
def toArrowSchema(schema: StructType, timeZoneId: String): Schema
```
Spark 3.5 or later
```scala
def toArrowSchema(
schema: StructType,
timeZoneId: String,
errorOnDuplicatedFieldNames: Boolean): Schema
```
Kyuubi is not affected by the issue of duplicated nested field names, as it consistently converts struct types to string types in Arrow mode
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4797 from cfmcgrady/arrow-toArrowSchema.
Closes#4797
2eb881b87 [Fu Chen] auto box
f69e0b395 [Fu Chen] asInstanceOf[Object] -> new JBoolean(errorOnDuplicatedFieldNames)
84c0ed381 [Fu Chen] unnecessarily force conversions
5ca65df8e [Fu Chen] Revert "new JBoolean"
0f7a1b4bd [Fu Chen] new JBoolean
044ba421c [Fu Chen] update comment
989c3caf1 [Fu Chen] reflective call ArrowUtils.toArrowSchema
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- explicitly set `n` to 1 in ChatGPT chat completion request (default to 1, https://platform.openai.com/docs/api-reference/chat/create#chat/create-n)
- use the only one choice of the chat completion response
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4810 from bowenliang123/chat-onechoice.
Closes#4810
f221de4e8 [bowenliang] one message
Authored-by: bowenliang <bowenliang@apache.org>
Signed-off-by: bowenliang <bowenliang@apache.org>
### _Why are the changes needed?_
- set session user when opening instance of ChatProvider
- use session user in ChatGPT request, to identify user of message and better monitor and abuse detection by OpenAI report( https://platform.openai.com/docs/api-reference/chat/create#chat/create-user)
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4809 from bowenliang123/chat-user.
Closes#4809
615d2385a [bowenliang] set session user in chatgpt request
Authored-by: bowenliang <bowenliang@apache.org>
Signed-off-by: bowenliang <bowenliang@apache.org>
### _Why are the changes needed?_
Support Flink job management statements.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4774 from link3280/KYUUBI-4495.
Closes#4495
a4aaebcbb [Paul Lin] [KYUUBI #4495] Adjust the order of tests
225a6cdbd [Paul Lin] [KYUUBI #4495] Increase the number of taskmanagers in the mini cluster
67935ac24 [Paul Lin] [KYUUBI #4495] Wait jobs to get ready for show job statements
9c4ce1d6e [Paul Lin] [KYUUBI #4495] Fix show jobs assertion error
ab3113cab [Paul Lin] [KYUUBI #4495] Support Flink job management statements
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to resolve https://github.com/apache/kyuubi/pull/4710#discussion_r1168600486
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4769 from cfmcgrady/arrow-send-driver-metrics.
Closes#4710
a952d088b [Fu Chen] refactor
a5645de90 [Fu Chen] address comment
6749630ee [Fu Chen] update
2dff41eeb [Fu Chen] add SparkMetricsTestUtils
8c772bca7 [Fu Chen] ut
4e3cd7d11 [Fu Chen] metrics
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [X] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4751 from link3280/KYUUBI-4745.
Closes#4745
e1e900bbe [Paul Lin] [KYUUBI #4745] Replace hive's timestamp format with the kyuubi's
0693d1f15 [Paul Lin] [KYUUBI #4745] Pin time zone in tests
462b39f2f [Paul Lin] [KYUUBI #4745] Improve variable naming
5f9976d81 [Paul Lin] [KYUUBI #4745] Support Flink's LocalZonedTimestamp DataType
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to adapt Spark 3.4
the signature of function `ArrowConveters#toBatchIterator` is changed in https://github.com/apache/spark/pull/38618 (since Spark 3.4)
Before Spark 3.4:
```
private[sql] def toBatchIterator(
rowIter: Iterator[InternalRow],
schema: StructType,
maxRecordsPerBatch: Int,
timeZoneId: String,
context: TaskContext): Iterator[Array[Byte]]
```
Spark 3.4
```
private[sql] def toBatchIterator(
rowIter: Iterator[InternalRow],
schema: StructType,
maxRecordsPerBatch: Long,
timeZoneId: String,
context: TaskContext): ArrowBatchIterator
```
the return type is changed from `Iterator[Array[Byte]]` to `ArrowBatchIterator`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4754 from cfmcgrady/arrow-spark34.
Closes#4754
a3c58d0ad [Fu Chen] fix ci
32704c577 [Fu Chen] Revert "fix ci"
e32311a03 [Fu Chen] fix ci
a76af6209 [Cheng Pan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
453b6a6b8 [Cheng Pan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
74a9f7a9d [Cheng Pan] Update externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
4ce5844af [Fu Chen] adapt Spark 3.4
Lead-authored-by: Fu Chen <cfmcgrady@gmail.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
To fix issue https://github.com/apache/kyuubi/issues/4713, a PR https://github.com/apache/kyuubi/pull/4714 was submitted, but it had Flaky test issues. After 50 local tests, it succeeded 38 times and failed 12 times.
This PR addresses the issue of flaky tests.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4749 from huangzhir/fixtest-schedulerpool.
Closes#4749
2d2e14069 [huangzhir] call KyuubiSparkContextHelper.waitListenerBus() to make sure there are no more events in the spark event queue
52a34d287 [fwang12] [KYUUBI #4746] Do not recreate async request executor if has been shutdown
d4558ea82 [huangzhir] Merge branch 'master' into fixtest-schedulerpool
44c4cefff [huangzhir] make sure the SparkListener has received the finished events for job1 and job2.
8a753e924 [huangzhir] make sure job1 started before job2
e66ede214 [huangzhir] fixbug TEST SchedulerPoolSuite a false positive result
Lead-authored-by: huangzhir <306824224@qq.com>
Co-authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
We meet an issue that cause all the operation stuck when closing operation.
Because now all the operations try to lock a Scala Enumeration val.
And if one of them stuck, all the others will be keep stuck.
In this pr, I add a lock for each operation.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4739 from turboFei/op_lock.
Closes#4739
535400a42 [fwang12] revert
a93438927 [fwang12] lockInterruptibly
274abc9db [fwang12] utils
ceda7314f [fwang12] op lock
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
This PR aims to remove Hudi integration tests from the Kyuubi project.
Actually, there is no obvious benefit to running Hudi tests w/ Kyuubi, since the real work happens on the compute engine and Hudi integration. Besides, Hudi's horrible dependency management brings significant maintenance efforts to the Kyuubi community.
This change only affects tests, does not affect any functionality.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4744 from pan3793/remove-hudi.
Closes#4744
ea99f747e [Cheng Pan] Remove Hudi integration tests
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
fix issuse https://github.com/apache/kyuubi/issues/4713
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4714 from huangzhir/fixtest-schedulerpool.
Closes#4713
Authored-by: huangzhir <306824224@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
`IpcOption.DEFAULT` was introduced in [ARROW-11081](https://github.com/apache/arrow/pull/9053)(ARROW-4.0.0), add `ARROW_IPC_OPTION_DEFAULT` for adapt Spark-3.1/3.2
```
Caused by: java.lang.NoSuchFieldError: DEFAULT
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.$anonfun$next$1(KyuubiArrowConverters.scala:304)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1491)
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.next(KyuubiArrowConverters.scala:308)
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.next(KyuubiArrowConverters.scala:231)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at org.apache.spark.sql.execution.arrow.KyuubiArrowConverters$ArrowBatchIterator.foreach(KyuubiArrowConverters.scala:231)
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4720 from cfmcgrady/arrow-ipc-option.
Closes#4720
2c80e670e [Fu Chen] fix style
a8294f637 [Fu Chen] add ARROW_IPC_OPTION_DEFAULT
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Fu Chen <cfmcgrady@gmail.com>
### _Why are the changes needed?_
fix issuse https://github.com/apache/kyuubi/issues/4713
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4714 from huangzhir/fixtest-schedulerpool.
Closes#4713
e66ede214 [huangzhir] fixbug TEST SchedulerPoolSuite a false positive result
Authored-by: huangzhir <306824224@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Since the job was lazily submitted in the incremental mode, the engine should not catch the task failed exception even though the operation is in the terminal state.
Before this PR:
```
0: jdbc:hive2://0.0.0.0:10009/> set kyuubi.operation.incremental.collect=true;
+---------------------------------------+--------+
| key | value |
+---------------------------------------+--------+
| kyuubi.operation.incremental.collect | true |
+---------------------------------------+--------+
0: jdbc:hive2://0.0.0.0:10009/> SELECT raise_error('custom error message');
Error: (state=,code=0)
0: jdbc:hive2://0.0.0.0:10009/>
```
kyuubi server log
```
2023-04-14 18:47:50.185 ERROR org.apache.kyuubi.server.KyuubiTBinaryFrontendService: Error fetching results:
java.lang.NullPointerException: null
at org.apache.kyuubi.server.BackendServiceMetric.$anonfun$fetchResults$1(BackendServiceMetric.scala:191) ~[classes/:?]
at org.apache.kyuubi.metrics.MetricsSystem$.timerTracing(MetricsSystem.scala:111) ~[classes/:?]
at org.apache.kyuubi.server.BackendServiceMetric.fetchResults(BackendServiceMetric.scala:187) ~[classes/:?]
at org.apache.kyuubi.server.BackendServiceMetric.fetchResults$(BackendServiceMetric.scala:182) ~[classes/:?]
at org.apache.kyuubi.server.KyuubiServer$$anon$1.fetchResults(KyuubiServer.scala:147) ~[classes/:?]
at org.apache.kyuubi.service.TFrontendService.FetchResults(TFrontendService.scala:530) [classes/:?]
```
After this PR:
```
0: jdbc:hive2://0.0.0.0:10009/> set kyuubi.operation.incremental.collect=true;
+---------------------------------------+--------+
| key | value |
+---------------------------------------+--------+
| kyuubi.operation.incremental.collect | true |
+---------------------------------------+--------+
0: jdbc:hive2://0.0.0.0:10009/> SELECT raise_error('custom error message');
Error: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 3.0 failed 1 times, most recent failure: Lost task 0.0 in stage 3.0 (TID 3) (0.0.0.0 executor driver): java.lang.RuntimeException: custom error message
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.project_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:364)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:890)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:890)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2672)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2608)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2607)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2607)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1182)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2860)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2802)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2791)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:952)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2228)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2249)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2268)
at org.apache.spark.rdd.RDD.collectPartition$1(RDD.scala:1036)
at org.apache.spark.rdd.RDD.$anonfun$toLocalIterator$3(RDD.scala:1038)
at org.apache.spark.rdd.RDD.$anonfun$toLocalIterator$3$adapted(RDD.scala:1038)
at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:486)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:492)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:491)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.kyuubi.operation.IterableFetchIterator.hasNext(FetchIterator.scala:97)
at scala.collection.Iterator$SliceIterator.hasNext(Iterator.scala:268)
at scala.collection.Iterator.toStream(Iterator.scala:1417)
at scala.collection.Iterator.toStream$(Iterator.scala:1416)
at scala.collection.AbstractIterator.toStream(Iterator.scala:1431)
at scala.collection.TraversableOnce.toSeq(TraversableOnce.scala:354)
at scala.collection.TraversableOnce.toSeq$(TraversableOnce.scala:354)
at scala.collection.AbstractIterator.toSeq(Iterator.scala:1431)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.$anonfun$getNextRowSet$1(SparkOperation.scala:265)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.$anonfun$withLocalProperties$1(SparkOperation.scala:155)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:169)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.withLocalProperties(SparkOperation.scala:139)
at org.apache.kyuubi.engine.spark.operation.SparkOperation.getNextRowSet(SparkOperation.scala:243)
at org.apache.kyuubi.operation.OperationManager.getOperationNextRowSet(OperationManager.scala:141)
at org.apache.kyuubi.session.AbstractSession.fetchResults(AbstractSession.scala:240)
at org.apache.kyuubi.service.AbstractBackendService.fetchResults(AbstractBackendService.scala:214)
at org.apache.kyuubi.service.TFrontendService.FetchResults(TFrontendService.scala:530)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1837)
at org.apache.hive.service.rpc.thrift.TCLIService$Processor$FetchResults.getResult(TCLIService.java:1822)
at org.apache.thrift.ProcessFunction.process(ProcessFunction.java:39)
at org.apache.thrift.TBaseProcessor.process(TBaseProcessor.java:39)
at org.apache.kyuubi.service.authentication.TSetIpAddressProcessor.process(TSetIpAddressProcessor.scala:36)
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:286)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.RuntimeException: custom error message
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.project_doConsume_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:760)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:364)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:890)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:890)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
... 3 more (state=,code=0)
0: jdbc:hive2://0.0.0.0:10009/>
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4711 from cfmcgrady/incremental-show-error-msg.
Closes#4711
66bb527ce [Fu Chen] JDBC client should catch task failed exception in the incremental mode
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Close#4681
Set `CreateSparkTimeoutChecker` in `SparkSQLEngine` daemon.
Exit when spark session initialize fail.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4682 from zwangsheng/KYUUBI_4681.
Closes#4681
1928a67ec [zwangsheng] Add thread name
57f1914e4 [zwangsheng] Add thread name
71ff31a2b [zwangsheng] revert
4e8a619b2 [zwangsheng] DEBUG
ea23fae11 [zwangsheng] Change Init Timeout => 10M
3a89acc64 [zwangsheng] fix comments
565d1c90a [zwangsheng] [KYUUBI #4681][Engine] Set thread daemon
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Now `GetCurrentCatalog`/`GetCurrentDatabase`/`SetCurrentCatalog`/`SetCurrentDatabase`is executed through the statement, and the jdbc client will try to obtain the operation log corresponding to the statement.
At present, these operations do not generate operation logs, so the engine log will be throw exception(`failed to generate operation log`).
```java
23/04/10 20:25:23 INFO GetCurrentCatalog: Processing anonymous's query[8218e7ed-b4a4-41ad-a1cc-6f82bf3d55bb]: INITIALIZED_STATE -> RUNNING_STATE, statement:
GetCurrentCatalog
23/04/10 20:25:23 INFO GetCurrentCatalog: Processing anonymous's query[8218e7ed-b4a4-41ad-a1cc-6f82bf3d55bb]: RUNNING_STATE -> FINISHED_STATE, time taken: 0.002 seconds
23/04/10 20:25:23 ERROR SparkTBinaryFrontendService: Error fetching results:
org.apache.kyuubi.KyuubiSQLException: OperationHandle [8218e7ed-b4a4-41ad-a1cc-6f82bf3d55bb] failed to generate operation log
at org.apache.kyuubi.KyuubiSQLException$.apply(KyuubiSQLException.scala:69)
at org.apache.kyuubi.operation.OperationManager.$anonfun$getOperationLogRowSet$2(OperationManager.scala:146)
at scala.Option.getOrElse(Option.scala:189)
```
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4688 from cxzl25/op_log_catalog.
Closes#4688
8ebc0f570 [sychen] Fix the failure to read the operation log after executing Catalog and database operation
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
closed#1770
Support flink `varbinary` type in query operation
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4666 from yuruguo/support-flink-varbinary-type.
Closes#4666
e05675e03 [Ruguo Yu] Support flink varbinary type in query operation
Authored-by: Ruguo Yu <jiang7chengzitc@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
close#4522
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4648 from lsm1/fix/kyuubi_4522.
Closes#4522
e06046899 [senmiaoliu] use foreach
bd83d6623 [senmiaoliu] spilt narmalizedConf
4d8445aac [senmiaoliu] avoid sort
eda34d480 [senmiaoliu] use catalog first
Authored-by: senmiaoliu <senmiaoliu@trip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Due to the Py4JServer initiating with a non-daemon thread, there is a possibility of it impeding the engine's termination. Therefore, it is imperative to manually terminate the Py4JServer during engine shutdown.
```
"Thread-23" #96 prio=5 os_prio=0 cpu=7.93ms elapsed=187532.67s tid=0x00007fee840cf000 nid=0x8f runnable [0x00007fedca6bf000]
java.lang.Thread.State: RUNNABLE
at java.net.PlainSocketImpl.socketAccept(java.base11.0.16/Native Method)
at java.net.AbstractPlainSocketImpl.accept(java.base11.0.16/Unknown Source)
at java.net.ServerSocket.implAccept(java.base11.0.16/Unknown Source)
at java.net.ServerSocket.accept(java.base11.0.16/Unknown Source)
at py4j.GatewayServer.run(GatewayServer.java:685)
at java.lang.Thread.run(java.base11.0.16/Unknown Source)
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4644 from cfmcgrady/pyserver-non-daemon.
Closes#4644
d4f1a57a6 [Fu Chen] synchronized
cdc9630a7 [Fu Chen] shutdown Py4JServer
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
Followup #1704, support flink `time` type in query operation
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4635 from yuruguo/support-flink-time-type.
Closes#4635
9f9a3e72d [Ruguo Yu] [Kyuubi #1704] Support flink time type in query operation
Authored-by: Ruguo Yu <jiang7chengzitc@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
As discussed before, Kyuubi is going to support the latest 3 Flink versions, and to reduce the complexity of supporting Flink 1.17 https://github.com/apache/kyuubi/pull/4368, we are going to remove support Flink 1.14 first.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4588 from pan3793/rm-flink-1.14.
Closes#4387
97d263324 [Cheng Pan] Remove support for Flink 1.14
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4541 from turboFei/expose.
Closes#4541
f882b4dda [fwang12] engine register attributes
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
- Make ChatGPT model ID configurable
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4558 from bowenliang123/chatgpt-model.
Closes#4558
63f8ee30d [liangbowen] nit
3012ccaaa [liangbowen] make chatgpt model configurable
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
### _Why are the changes needed?_
- use Java SDK `openai-java` for ChatGPT which is popular and listed in official website, https://github.com/TheoKanning/openai-java
- Focus on lifecycle in ChatGPTProvider, and prevent handling lower-level concepts in details, like POJO mapping, HTTP request handling.
- follow the changes from upstream changes from OpenAI
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4556 from bowenliang123/chatgpt-third.
Closes#4556
ecf1e2cf6 [liangbowen] manually add `openai-gpt3-java:*` and its dependency to LICENSE-binary
53b8375a5 [liangbowen] refactor ChatGPTProvider to use `openai-java` SDK
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: liangbowen <liangbowen@gf.com.cn>
Fix bug in flink 1.14 version, multiple executions lead to abnormal results
### _Why are the changes needed?_
Fix bug in flink 1.14 version, multiple executions lead to abnormal results
### _How was this patch tested?_
- [X] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [X] Add screenshots for manual tests if appropriate
- [X] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4517 from waywtdcc/flink1.14_result_ok_error.
Closes#4517
96ce6129c [Cheng Pan] ut
1bd9d1e2f [Cheng Pan] nit
5e5bccc91 [Cheng Pan] Migrate Flink engine Java code to Scala
4afb02064 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
3d5dc64c5 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
c084864bd [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
954d76062 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
d63ec55f2 [chenchao4] Fix bug in flink 1.14 version, multiple executions lead to abnormal results
Lead-authored-by: Chao Chen <chenchao4@grgbanking.com>
Co-authored-by: chenchao4 <Chenchao123>
Co-authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- set authentication as default header in client construction instead of request construction
- handle response's status code in scala style
- transforming config's long value to int with `.intValue` instead of `asInstanceOf` casting
- fix var name to `response`
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4554 from bowenliang123/chatgpt-http.
Closes#4554
114484a4d [liangbowen] httpclient improvement in ChatGPTProvider
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Support Chinese question
- Support proxy settings
- Support setting timeout
<img width="1228" alt="image" src="https://user-images.githubusercontent.com/3898450/225851246-8762a451-9743-4c1d-8a33-cc49a926dfec.png">
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4548 from cxzl25/chatgpt_followup.
Closes#4548
1d5715442 [Cheng Pan] Update externals/kyuubi-chat-engine/src/main/scala/org/apache/kyuubi/engine/chat/provider/ChatGPTProvider.scala
7add6a733 [Cheng Pan] Update externals/kyuubi-chat-engine/src/main/scala/org/apache/kyuubi/engine/chat/provider/ChatGPTProvider.scala
55974f298 [sychen] fix
2d360e102 [sychen] typo
19b5d0814 [sychen] doc
bdf8e29b6 [sychen] 1.utf8;2.proxy;timeout
Lead-authored-by: sychen <sychen@ctrip.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Introduce a brand new CHAT engine, it's supposed to support different backends, e.g. ChatGPT, 文心一言, etc.
This PR implements the following providers:
- ECHO, simply replies a welcome message.
- GPT: a.k.a ChatGPT, powered by OpenAI, which requires a API key for authentication. https://platform.openai.com/account/api-keys
Add the following configurations in `kyuubi-defaults.conf`
```
kyuubi.engine.chat.provider=[ECHO|GPT]
kyuubi.engine.chat.gpt.apiKey=<chat-gpt-api-key>
```
Open an ECHO beeline chat engine.
```
beeline -u 'jdbc:hive2://localhost:10009/?kyuubi.engine.type=CHAT;kyuubi.engine.chat.provider=ECHO'
```
```
Connecting to jdbc:hive2://localhost:10009/
Connected to: Kyuubi Chat Engine (version 1.8.0-SNAPSHOT)
Driver: Kyuubi Project Hive JDBC Client (version 1.7.0)
Beeline version 1.7.0 by Apache Kyuubi
0: jdbc:hive2://localhost:10009/> Hello, Kyuubi!;
+----------------------------------------+
| reply |
+----------------------------------------+
| This is ChatKyuubi, nice to meet you! |
+----------------------------------------+
1 row selected (0.397 seconds)
```
Open a ChatGPT beeline chat engine. (make sure your network can connect the open API and configure the API key)
```
beeline -u 'jdbc:hive2://localhost:10009/?kyuubi.engine.type=CHAT;kyuubi.engine.chat.provider=GPT'
```
<img width="1109" alt="image" src="https://user-images.githubusercontent.com/26535726/225813625-a002e6e2-3b0d-4194-b061-2e215d58ba94.png">
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [x] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4544 from pan3793/chatgpt.
Closes#4544
87bdebb6d [Cheng Pan] nit
f7dee18f3 [Cheng Pan] Update docs
9beb55162 [cxzl25] chat api (#1)
af38bdc7c [Cheng Pan] update docs
9aa6d83a6 [Cheng Pan] Initial implement Kyuubi Chat Engine
Lead-authored-by: Cheng Pan <chengpan@apache.org>
Co-authored-by: cxzl25 <cxzl25@users.noreply.github.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
see detail in KYUUBI #3436
Splitting it out of a giant PR https://github.com/apache/kyuubi/pull/4002 to perfect
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4459 from zwangsheng/3420.
Closes#3420
2fd9b3131 [zwangsheng] [KYUUBI #3420]Fouce on spark web ui
3fbee02b7 [zwangsheng] [KYUUBI #3420] With inter config and expose explicit conf
09841d17b [zwangsheng] [KYUUBI #3420] Fix style
b47c3e5d1 [zwangsheng] [KYUUBI #3420] Fix unit test
b3ab3e23b [zwangsheng] [KYUUBI #3420] Expose more spark engine info
69292abf4 [zwangsheng] [KYUUBI #3420] Using common test case
cf889b09b [zwangsheng] [KYUUBI #3420] Fix unit test
1a0ac582f [zwangsheng] [KYUUBI #3420] Fix style
daf41de2d [zwangsheng] [KYUUBI #4453] Add etcd test
ab1038369 [zwangsheng] [KYUUBI #3420 Add Spark Web UI Url in zk node]
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Flink 1.15 refactors the result fetching of insert statements and now `TableResult.await()` would block till the insert finishes. We could remove this line because the insert results are immediately available as other non-job statements.
Flink JIRA: https://issues.apache.org/jira/browse/FLINK-24461
Critical changes: https://github.com/apache/flink/pull/17441/files#diff-ec88f0e06d880b53e2f152113ab1a4240a820cbb7248815c5f9ecf9ab4fce4caR108
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4485 from link3280/KYUUBI-4446.
Closes#4446
256176c3b [Paul Lin] [KYUUBI #4446] Update comments
3cb982ca4 [Paul Lin] [KYUUBI #4446] Add comments
d4c194ee5 [Paul Lin] [KYUUBI #4446] Fix connections blocked by Flink insert statements
Authored-by: Paul Lin <paullin3280@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
`GetTables` operation is too slow because it queries table details info one by one, but then only a table comment is used to construct a result row, which i think could be optional.
This PR add an optional config which can control this operation. By default, `GetTables` operation queries all message. Otherwise, `GetTables` operation just return table identifiers.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4444 from liaoyt/master.
Closes#4171
af5e60e36 [yeatsliao] rename config
0c9985e32 [yeatsliao] add doc
5e8687cb3 [yeatsliao] Supports ignore table comment when list all tables.
Authored-by: yeatsliao <liaoyt66066@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
#4412 follow up
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4422 from turboFei/align_session_id.
Closes#4412
319373296 [fwang12] save
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
1. get spark engine runtime version instead of compile version
2. moved `PySparkTests` from the module `kyuubi-spark-sql-engine` to `kyuubi-server` to ensure that the python progress loading library PYSPARK has the same version as the launched Spark engine. see https://github.com/apache/kyuubi/pull/4381#issuecomment-1442871106
### _How was this patch tested?_
Pass Github Action.
Closes#4381 from cfmcgrady/spark-3.4.0.
Closes#4381
2711f51b3 [Fu Chen] remove verify spark-3.4 binary
a93b6d13e [Fu Chen] mv PySparkTests and enabled
6d5aad537 [Fu Chen] fix style
2da641561 [Fu Chen] fix style
3c9e300ce [Fu Chen] spark compile version -> runtime version
a8e7b7481 [Fu Chen] unused import
6be502ca6 [Fu Chen] fix ut
c1a1e1a8e [Fu Chen] skip pyspark tests
0049c23b7 [Fu Chen] verify spark-3.4.0 binary
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4415 from turboFei/operation_handle_align.
Closes#4415
71721797a [fwang12] refactor
c8b667a89 [fwang12] refactor
d3fbf05f3 [fwang12] stmt handle
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4414 from turboFei/get_or_else.
Closes#4412
e7d45ef24 [fwang12] refactor
f8583ec94 [fwang12] use different handle for alive probe
33a776cf0 [fwang12] launch sync
967ae41fa [fwang12] [KYUUBI #4412][FOLLOWUP] Fallback to new engine session handle for UT
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
Align the server session handle and engine session handle for Spark engine.
It make it easy to recovery the engine session in any kyuubi instance easy.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4412 from turboFei/server_engine_handle_align.
Closes#4412
a20e0f155 [fwang12] fix
9d590e38b [fwang12] fix
94267e583 [fwang12] save
7012c2bef [fwang12] align
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: fwang12 <fwang12@ebay.com>
### _Why are the changes needed?_
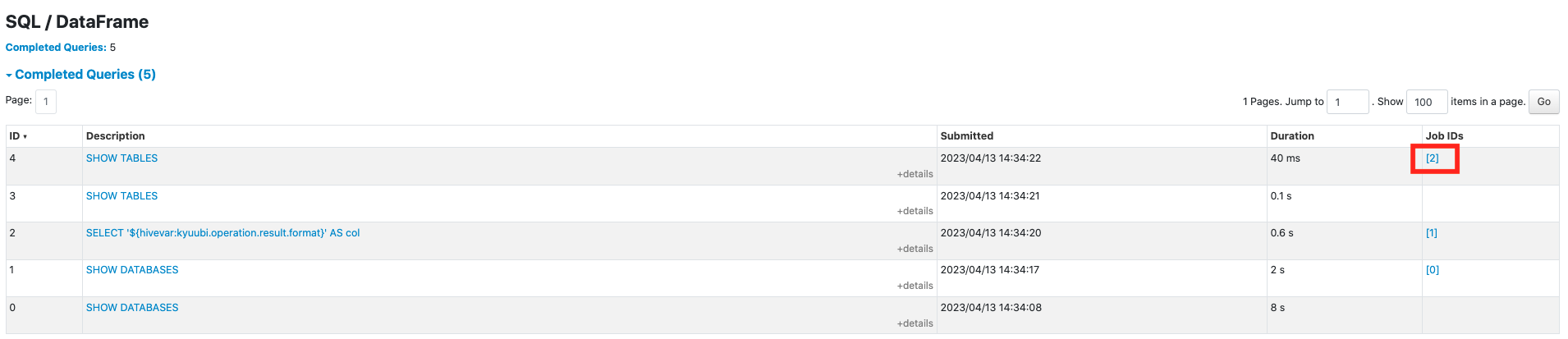
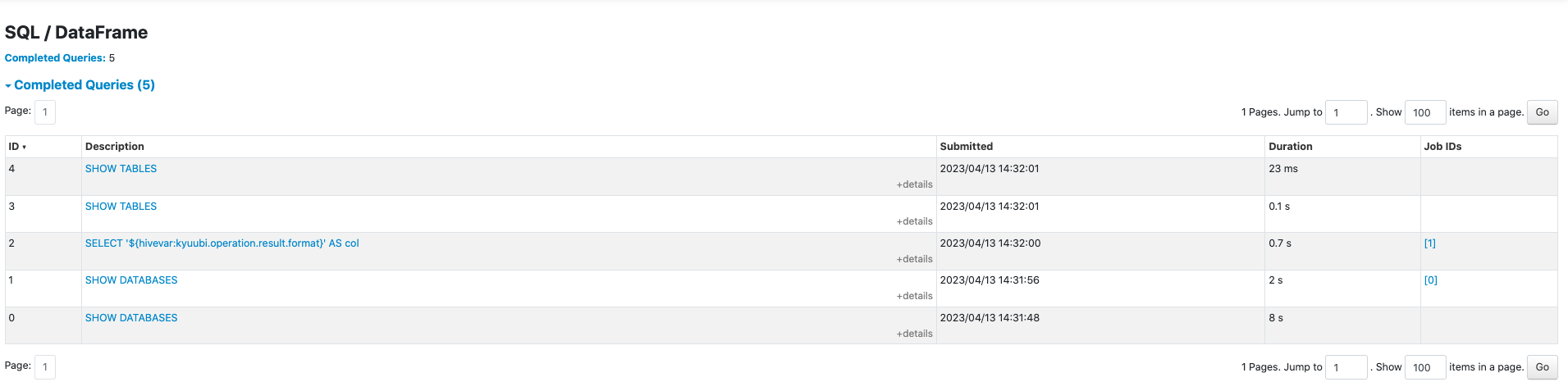
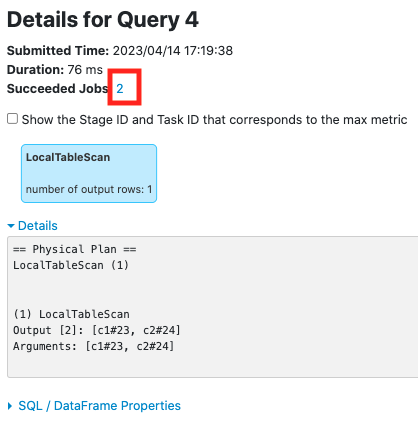
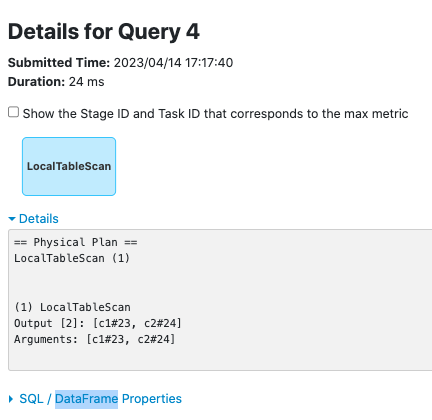
Currently, the SQL metrics are missing from the SQL UI tab, this is because we mistakenly bound QueryExecution in [PR-4392](https://github.com/apache/kyuubi/pull/4392), before this PR, it was `resultDF.queryExecution` that was bound to `SQLExecution.withNewExecutionId()`, But the executed Dataset is `resultDF.select(cols: _*)`, this PR passed the correct QueryExecution `resultDF.select(cols: _*).queryExecution` to solve this problem.
```sql
set kyuubi.operation.result.format=arrow;
select 1;
```
Before this PR:

After this PR:

### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4402 from cfmcgrady/arrow-metrics.
Closes#4402
e0cde3b1 [Fu Chen] fix style
b35cbfdc [Fu Chen] fix
542414ef [Fu Chen] make arrow-based query metrics trackable in SQL UI
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}