 [](https://github.com/yaooqinn/kyuubi/pull/292)  [❨?❩](https://pullrequestbadge.com/?utm_medium=github&utm_source=yaooqinn&utm_campaign=badge_info)<!-- PR-BADGE: PLEASE DO NOT REMOVE THIS COMMENT --> <!-- Thanks for sending a pull request! Here are some tips for you: 1. If this is your first time, please read our contributor guidelines: https://kyuubi.readthedocs.io/en/latest/community/contributions.html --> <!-- replace ${issue ID} with the actual issue id --> Fixes #280 closes #292 <!-- Please clarify why the changes are needed. For instance, 1. If you add a feature, you can talk about the user case of it. 2. If you fix a bug, you can clarify why it is a bug. --> Before this PR, Kyuubi treat Operation GET_SCHEMAS * as an invalid Operation then cause HUE list databases failed, but HiveServer2 will return all databases on same request. - [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible - [x] Add screenshots for manual tests if appropriate - [x] [Run test](https://kyuubi.readthedocs.io/en/latest/tools/testing.html#running-tests) locally before make a pull request After PR: 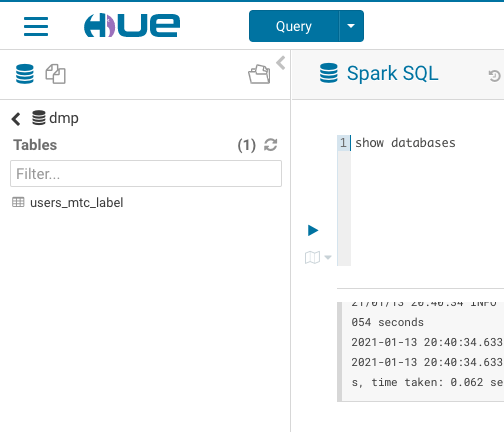 Squashed commit of the following: commit f56fdc3fe35b4aa5a7b6f09cbbaa023ec713e2fe Author: Cheng Pan <379377944@qq.com> Date: Sun Jan 17 23:27:03 2021 +0800 [KYUUBI-280] code style and ut commit ff74dbaf3e6d5606e5a2171e6dcc3628aa631eea Author: Cheng Pan <379377944@qq.com> Date: Sun Jan 17 23:08:59 2021 +0800 [KYUUBI-280] remove comments and handle schema * in other place commit a8bcf98cd70e36903ece654e1c37d08e868b1c5b Author: Cheng Pan <379377944@qq.com> Date: Sun Jan 17 13:47:24 2021 +0800 [KYUUBI-280] Align Operation GET_SCHEMAS * behavior with Hive |
||
|---|---|---|
| .github | ||
| bin | ||
| build | ||
| conf | ||
| dev | ||
| docs | ||
| externals | ||
| kyuubi-assembly | ||
| kyuubi-common | ||
| kyuubi-ha | ||
| kyuubi-main | ||
| _config.yml | ||
| .gitignore | ||
| .readthedocs.yml | ||
| .travis.yml | ||
| CODE_OF_CONDUCT.md | ||
| codecov.yml | ||
| LICENSE | ||
| pom.xml | ||
| README.md | ||
| scalastyle-config.xml | ||
{kind=link}
Kyuubi
![]()


![]()




Kyuubi is a high-performance universal JDBC and SQL execution engine, built on top of Apache Spark. The goal of Kyuubi is to facilitate users to handle big data like ordinary data.
It provides a standardized JDBC interface with easy-to-use data access in big data scenarios. End-users can focus on developing their own business systems and mining data value without having to be aware of the underlying big data platform (compute engines, storage services, metadata management, etc.).
Kyuubi relies on Apache Spark to provide high-performance data query capabilities,
and every improvement in the engine's capabilities can help Kyuubi's performance make a qualitative leap.
In addition, Kyuubi improves ad-hoc responsiveness through the engine caching,
and enhances concurrency through horizontal scaling and load balancing.
It provides complete authentication and authentication services to ensure data and metadata security.
It provides robust high availability and load balancing to help you guarantee the SLA commitment.
It provides a two-level elastic resource management architecture to effectively improve resource utilization while covering the performance and response requirements of all scenarios including interactive,
or batch processing and point queries, or full table scans.
It embraces Spark and builds an ecosystem on top of it,
which allows Kyuubi to quickly expand its existing ecosystem and introduce new features,
such as cloud-native support and Data Lake/Lake House support.
Kyuubi's vision is to build on top of Apache Spark and Data Lake technologies to unify the portal and become an ideal data lake management platform. It can support data processing e.g. ETL, and analytics e.g. BI in a pure SQL way. All workloads can be done on one platform, using one copy of data, with one SQL interface.
Online Documentation
Since Kyuubi 1.0.0, the Kyuubi online documentation is hosted by https://readthedocs.org/. You can find the specific version of Kyuubi documentation as listed below.
For 0.8 and earlier versions, please check the project docs folder directly.
Quick Start
Ready? Getting Started with Kyuubi.
Contributing
All bits of help are welcome. You can make various types of contributions to Kyuubi, including the following but not limited to,
- Help new users in chat channel or share your success stories w/ us -

- Improve Documentation -
- Test releases -
- Improve test coverage -

- Report bugs and better help developers to reproduce
- Review changes
- Make a pull request
- Promote to others
- Click the star button if you like this project
Aside
The project took its name from a character of a popular Japanese manga - Naruto.
The character is named Kyuubi Kitsune/Kurama, which is a nine-tailed fox in mythology.
Kyuubi spread the power and spirit of fire, which is used here to represent the powerful Apache Spark.
It's nine tails stands for end-to end multi-tenancy support of this project.