2675e9a80d
4 Commits
| Author | SHA1 | Message | Date | |
|---|---|---|---|---|
|
|
0ecf8fbc7e
|
[KYUUBI #939] z-order performance_test
### What is the purpose of the pull request pr for KYUUBI #939:Add Z-Order extensions to optimize table with zorder.Z-order is a technique that allows you to map multidimensional data to a single dimension. We did a performance test for this test ,we used aliyun Databricks Delta test case https://help.aliyun.com/document_detail/168137.html?spm=a2c4g.11186623.6.563.10d758ccclYtVb Prepare data for the three scenarios: 1. 10 billion data and 2 hundred files(parquet files): for big file(1G) 2. 10 billion data and 1 thousand files(parquet files): for medium file(200m) 3. one billion data and 10 hundred files(parquet files): for smaller file(200k) test env: spark-3.1.2 hadoop-2.7.2 kyubbi-1.4.0 test step: Step1: create hive tables ```scala spark.sql(s"drop database if exists $dbName cascade") spark.sql(s"create database if not exists $dbName") spark.sql(s"use $dbName") spark.sql(s"create table $connRandomParquet (src_ip string, src_port int, dst_ip string, dst_port int) stored as parquet") spark.sql(s"create table $connZorderOnlyIp (src_ip string, src_port int, dst_ip string, dst_port int) stored as parquet") spark.sql(s"create table $connZorder (src_ip string, src_port int, dst_ip string, dst_port int) stored as parquet") spark.sql(s"show tables").show(false) ``` Step2: prepare data for parquet table with three scenarios we use the following code ```scala def randomIPv4(r: Random) = Seq.fill(4)(r.nextInt(256)).mkString(".") def randomPort(r: Random) = r.nextInt(65536) def randomConnRecord(r: Random) = ConnRecord( src_ip = randomIPv4(r), src_port = randomPort(r), dst_ip = randomIPv4(r), dst_port = randomPort(r)) ``` Step3: do optimize with z-order only ip, sort column: src_ip, dst_ip and shuffle partition just as file numbers . execute 'OPTIMIZE conn_zorder_only_ip ZORDER BY src_ip, dst_ip;' by kyuubi. Step4: do optimize with z-order only ip, sort column: src_ip, dst_ip and shuffle partition just as file numbers . execute 'OPTIMIZE conn_zorder ZORDER BY src_ip, src_port, dst_ip, dst_port;' by kyuubi. --------------------- # benchmark result by querying the tables before and after optimization, we find that **10 billion data and 200 files and Query resource:200 core 600G memory** | Table | Average File Size | Scan row count | Average query time | row count Skipping ratio | | ------------------- | ----------------- | -------------- | ------------------ | ------------------------ | | conn_random_parquet | 1.2 G | 10,000,000,000 | 27.554 s | 0.0% | | conn_zorder_only_ip | 890 M | 43,170,600 | 2.459 s | 99.568% | | conn_zorder | 890 M | 54,841,302 | 3.185 s | 99.451% | **10 billion data and 2000 files and Query resource:200 core 600G memory** | Table | Average File Size | Scan row count | Average query time | row count Skipping ratio | | ------------------- | ----------------- | -------------- | ------------------ | ------------------------ | | conn_random_parquet | 234.8 M | 10,000,000,000 | 27.031 s | 0.0% | | conn_zorder_only_ip | 173.9 M | 43,170,600 | 2.668 s | 99.568% | | conn_zorder | 174.0 M | 54,841,302 | 3.207 s | 99.451% | **1 billion data and 10000 files and Query resource:10 core 40G memory** | Table | Average File Size | Scan row count | Average query time | row count Skipping ratio | | ------------------- | ----------------- | -------------- | ------------------ | ------------------------ | | conn_random_parquet | 2.7 M | 1,000,000,000 | 76.772 s | 0.0% | | conn_zorder_only_ip | 2.1 M | 406,572 | 3.963 s | 99.959% | | conn_zorder | 2.2 M | 387,942 | 3.621s | 99.961% | Closes #1178 from hzxiongyinke/zorder_performance_test. Closes #939 369a9b41 [hzxiongyinke] remove set spark.sql.extensions=org.apache.kyuubi.sql.KyuubiSparkSQLExtension; 8c8ae458 [hzxiongyinke] add index z-order-benchmark 66bd20fd [hzxiongyinke] change tables to three scenarios cc80f4e7 [hzxiongyinke] add License 70c29daa [hzxiongyinke] z-order performance_test 6f1892be [hzxiongyinke] Merge pull request #1 from apache/master Lead-authored-by: hzxiongyinke <1062376716@qq.com> Co-authored-by: hzxiongyinke <75288351+hzxiongyinke@users.noreply.github.com> Signed-off-by: ulysses-you <ulyssesyou@apache.org> |
||
|
|
a76c344042
|
[KYUUBI #951] [LICENSE] Add license header on all docs
<!-- Thanks for sending a pull request! Here are some tips for you: 1. If this is your first time, please read our contributor guidelines: https://kyuubi.readthedocs.io/en/latest/community/contributions.html 2. If the PR is related to an issue in https://github.com/apache/incubator-kyuubi/issues, add '[KYUUBI #XXXX]' in your PR title, e.g., '[KYUUBI #XXXX] Your PR title ...'. 3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][KYUUBI #XXXX] Your PR title ...'. --> ### _Why are the changes needed?_ <!-- Please clarify why the changes are needed. For instance, 1. If you add a feature, you can talk about the use case of it. 2. If you fix a bug, you can clarify why it is a bug. --> ### _How was this patch tested?_ - [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible - [ ] Add screenshots for manual tests if appropriate - [ ] [Run test](https://kyuubi.readthedocs.io/en/latest/develop_tools/testing.html#running-tests) locally before make a pull request Closes #951 from pan3793/license. Closes #951 4629eecd [Cheng Pan] Fix c45a0784 [Cheng Pan] nit b9a46b42 [Cheng Pan] pin license header at first line 80d1a71b [Cheng Pan] nit b2a46e4c [Cheng Pan] Update f6acaaf8 [Cheng Pan] minor ef99183f [Cheng Pan] Add license header on all docs Authored-by: Cheng Pan <chengpan@apache.org> Signed-off-by: Cheng Pan <chengpan@apache.org> |
||
|
|
2a05326c1b |
[KYUUBI #699][DOCS] Add document for kyuubi-extension-spark_3.1 module
<!-- Thanks for sending a pull request! Here are some tips for you: 1. If this is your first time, please read our contributor guidelines: https://kyuubi.readthedocs.io/en/latest/community/contributions.html 2. If the PR is related to an issue in https://github.com/NetEase/kyuubi/issues, add '[KYUUBI #XXXX]' in your PR title, e.g., '[KYUUBI #XXXX] Your PR title ...'. 3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][KYUUBI #XXXX] Your PR title ...'. --> ### _Why are the changes needed?_ <!-- Please clarify why the changes are needed. For instance, 1. If you add a feature, you can talk about the use case of it. 2. If you fix a bug, you can clarify why it is a bug. --> Make Kyuubi SQL extension readable. ### _How was this patch tested?_ The screen snapshot is: 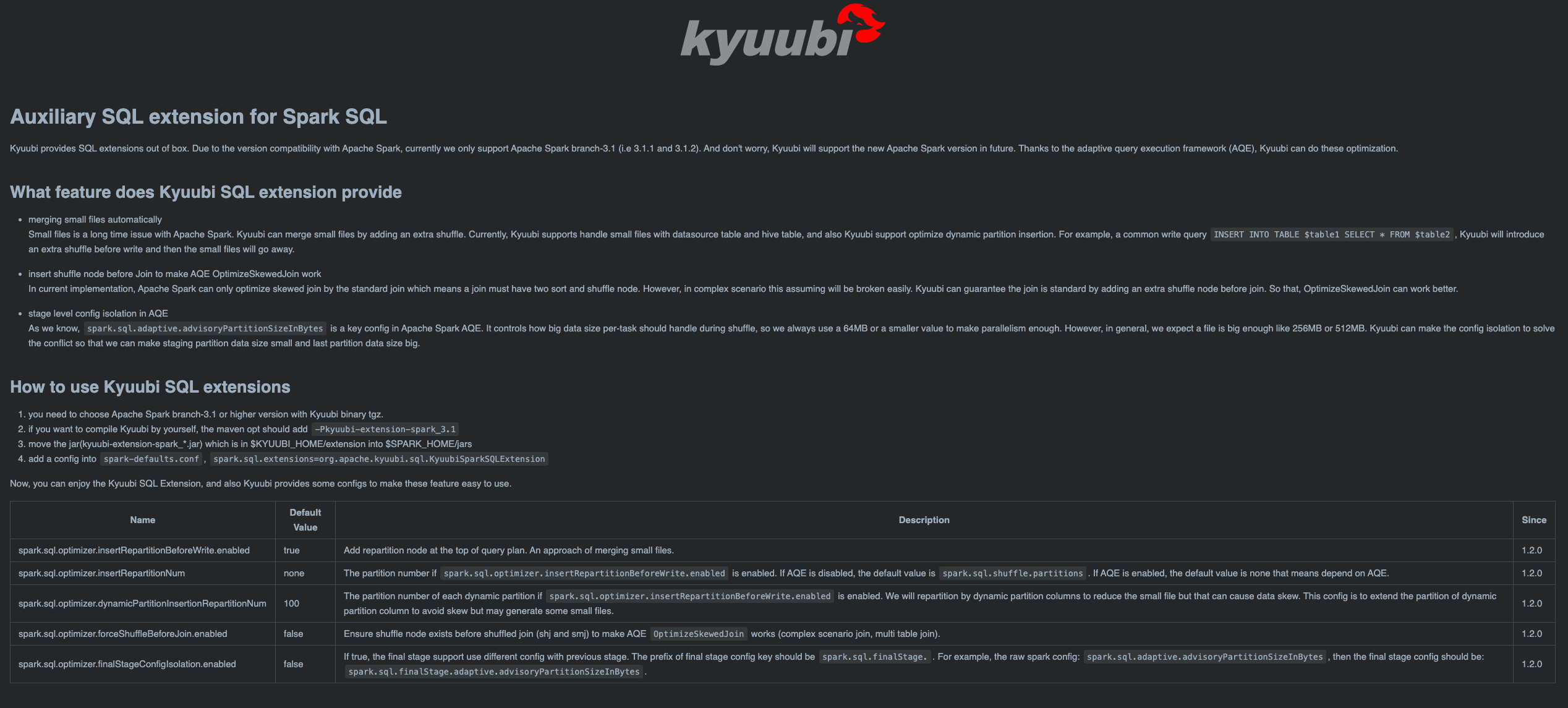 Closes #702 from ulysses-you/docs. Closes #699 d9d63604 [ulysses-you] nit 21d9cf75 [ulysses-you] docs b034421d [ulysses-you] docs Authored-by: ulysses-you <ulyssesyou18@gmail.com> Signed-off-by: ulysses-you <ulyssesyou18@gmail.com> |
||
|
|
a2f1e22361 |
[KYUUBI #657] Add udf kyuubi_version
<!-- Thanks for sending a pull request! Here are some tips for you: 1. If this is your first time, please read our contributor guidelines: https://kyuubi.readthedocs.io/en/latest/community/contributions.html 2. If the PR is related to an issue in https://github.com/NetEase/kyuubi/issues, add '[KYUUBI #XXXX]' in your PR title, e.g., '[KYUUBI #XXXX] Your PR title ...'. 3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][KYUUBI #XXXX] Your PR title ...'. --> ### _Why are the changes needed?_ In this PR, I propose to add kyuubi_version as a user-defined function. This is also a good example to add other new functions that needed in the Kyuubi system. ### _How was this patch tested?_ - [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible - [ ] Add screenshots for manual tests if appropriate - [x] [Run test](https://kyuubi.readthedocs.io/en/latest/tools/testing.html#running-tests) locally before make a pull request Closes #686 from yaooqinn/657. Closes #657 d30ac8f6 [Kent Yao] [KYUUBI #657] Add udf kyuubi_version e1e585e9 [Kent Yao] [KYUUBI #657] Add udf kyuubi_version Authored-by: Kent Yao <yao@apache.org> Signed-off-by: Cheng Pan <379377944@qq.com> |
{kind=link}