### Why are the changes needed?
As title.
### How was this patch tested?
UT are modified.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes#7139 from pan3793/rebalance.
Closes#7139
edb070afd [Cheng Pan] fix
4d3984a92 [Cheng Pan] Fix Spark extension rules to support RebalancePartitions
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### Why are the changes needed?
When users switch from Hive to Spark, for sql like INSERT OVERWRITE DIRECTORY AS SELECT, it would be great if small files could be automatically merged through simple configuration, just like in Hive.
### How was this patch tested?
UnitTest
### Was this patch authored or co-authored using generative AI tooling?
No
Closes#6991 from Z1Wu/feat/add_insert_dir_rebalance_support.
Closes#6990
2820bb2d2 [wuziyi] [fix] nit
a69c04191 [wuziyi] [fix] nit
951a7738f [wuziyi] [fix] nit
f75dfcb3a [wuziyi] [Feat] add rebalance before InsertIntoHiveDirCommand and InsertIntoDataSourceDirCommand to align with behaviors of hive
Authored-by: wuziyi <wuziyi02@corp.netease.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### Why are the changes needed?
The feature `spark.sql.watchdog.forcedMaxOutputRows` is a little bit hacky, it's actually a manually implemented "limit pushdown", we already have a simple and more reliable way to achieve that by using `kyuubi.operation.result.max.rows`.
### How was this patch tested?
Pass GHA.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes#6983 from pan3793/rm-forcedMaxOutputRows.
Closes#6983
5e0707955 [Cheng Pan] Remove support for spark.sql.watchdog.forcedMaxOutputRows
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### Why are the changes needed?
Simple refactoring to clean up the code for the Spark 3.5 extension, e.g., remove unnecessary `*Base` `*Helper` abstraction layers, remove code for legacy Spark versions.
Note: I don't touch `ForcedMaxOutputRows*` because I'm going to remove it in the next PR.
Preparation for Spark 4.0 support.
### How was this patch tested?
Pass GHA.
### Was this patch authored or co-authored using generative AI tooling?
No.
Closes#6975 from pan3793/spark-ext-35-cleanup.
Closes#6975
b5a94a680 [Cheng Pan] nit
c729e268c [Cheng Pan] fix
1087ac709 [Cheng Pan] Clean up code for Spark 3.5 extension
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### Why are the changes needed?
Backport https://github.com/apache/kyuubi/pull/5852 to Spark 3.3, to enhance MaxScanStrategy to include support for the datasourcev2 in Spark 3.3
### How was this patch tested?
Add some UTs
### Was this patch authored or co-authored using generative AI tooling?
No
Closes#6862 from zhaohehuhu/dev-1225.
Closes#6862
c745eda14 [zhaohehuhu] MaxScanStrategy supports DSv2 in Spark 3.3
Authored-by: zhaohehuhu <luoyedeyi459@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
## Issue References 🔗
This pull request fixes #
## Describe Your Solution 🔧
Preparing v1.11.0-SNAPSHOT after branch-1.10 cut
```shell
build/mvn versions:set -DgenerateBackupPoms=false -DnewVersion="1.11.0-SNAPSHOT"
(cd kyuubi-server/web-ui && npm version "1.11.0-SNAPSHOT")
```
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
#### Behavior Without This Pull Request ⚰️
#### Behavior With This Pull Request 🎉
#### Related Unit Tests
---
# Checklist 📝
- [ ] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6769 from bowenliang123/bump-1.11.
Closes#6769
6db219d28 [Bowen Liang] get latest_branch by sorting version in branch name
465276204 [Bowen Liang] update package.json
81f2865e5 [Bowen Liang] bump
Authored-by: Bowen Liang <liangbowen@gf.com.cn>
Signed-off-by: Bowen Liang <liangbowen@gf.com.cn>
# 🔍 Description
## Issue References 🔗
This pull request fixes#6581
## Describe Your Solution 🔧
Please include a summary of the change and which issue is fixed. Please also include relevant motivation and context. List any dependencies that are required for this change.
I modified `KyuubiSparkSQLAstBuilder#visitMultipartIdentifier` and implemented `KyuubiSparkSQLAstBuilder#visitQuotedIdentifier` to process the quoted identifiers.
## Types of changes 🔖
- [x] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
#### Behavior Without This Pull Request ⚰️
#### Behavior With This Pull Request 🎉
#### Related Unit Tests
```
extensions/spark/kyuubi-extension-spark-3-3/src/test/scala/org/apache/spark/sql/ZorderSuiteBase.scala
test("optimize sort by backquoted column name")
```
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6582 from XorSum/features/zorder-backquote.
Closes#6582
16ffa1238 [xorsum] zorder by support quote
Authored-by: xorsum <xorsum@outlook.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
## Issue References 🔗
This pull request fixes#6554
## Describe Your Solution 🔧
- Delete `/kyuubi/extensions/spark/kyuubi-extension-spark-3-x/src/main/scala/org/apache/kyuubi/sql/zorder/InsertZorderBeforeWritingBase.scala` file
- Rename `InsertZorderBeforeWriting33.scala` to `InsertZorderBeforeWriting.scala`
- Rename `InsertZorderHelper33, InsertZorderBeforeWritingDatasource33, InsertZorderBeforeWritingHive33, ZorderSuiteSpark33` to `InsertZorderHelper, InsertZorderBeforeWritingDatasource, InsertZorderBeforeWritingHive, ZorderSuiteSpark`
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
#### Behavior Without This Pull Request ⚰️
#### Behavior With This Pull Request 🎉
#### Related Unit Tests
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6555 from huangxiaopingRD/6554.
Closes#6554
26de4fa09 [huangxiaoping] [KYUUBI #6554] Delete redundant code related to zorder
Authored-by: huangxiaoping <1754789345@qq.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
## Issue References 🔗
This pull request fixes#6551
## Describe Your Solution 🔧
Update `canInsertZorder` to allow insert zorder when global sort is `false` and the plan is `Repartition` or `RepartitionByExpression`.
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
#### Behavior Without This Pull Request ⚰️
#### Behavior With This Pull Request 🎉
#### Related Unit Tests
/kyuubi-extension-spark-common/src/test/scala/org/apache/spark/sql/ZorderSuiteBase.scala
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6552 from huangxiaopingRD/6551.
Closes#6551
b597443c3 [huangxiaoping] Fix code style
618594667 [huangxiaoping] [KYUUBI #6551] Allow insert zorder when when the plan is Repartition or RepartitionByExpression
Authored-by: huangxiaoping <1754789345@qq.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
# 🔍 Description
This pull request aims to remove building support for Spark 3.2, while still keeping the engine support for Spark 3.2.
Mailing list discussion: https://lists.apache.org/thread/l74n5zl1w7s0bmr5ovxmxq58yqy8hqzc
- Remove Maven profile `spark-3.2`, and references on docs, release scripts, etc.
- Keep the cross-version verification to ensure that the Spark SQL engine built on the default Spark version (3.5) still works well on Spark 3.2 runtime.
- Merge `kyuubi-extension-spark-common` into `kyuubi-extension-spark-3-3`
- Remove `log4j.properties` as Spark moves to Log4j2 since 3.3 (SPARK-37814)
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [x] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
Pass GHA.
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6545 from pan3793/deprecate-spark-3.2.
Closes#6545
54c172528 [Cheng Pan] fix
f4602e805 [Cheng Pan] Deprecate and remove building support for Spark 3.2
2e083f89f [Cheng Pan] fix style
458a92c53 [Cheng Pan] nit
929e1df36 [Cheng Pan] Deprecate and remove building support for Spark 3.2
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
This PR makes `javax.servlet` and `jakarta.servlet` co-exist, by introducing `javax.servlet-api-4.0.1` and upgrade `jakarta.servlet-api` to 5.0.0. (6.0.0 requires JDK 11)
Spark 4.0 migrated from `javax.servlet` to `jakarta.servlet` in SPARK-47118 while Kyuubi still uses `javax.servlet` in other modules, we should allow them to co-exist for a while.
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
Pass GHA.
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6392 from pan3793/servlet.
Closes#6392
27d412599 [Cheng Pan] fix
9f1e72272 [Cheng Pan] other spark modules
f4545dc76 [Cheng Pan] fix
313826fa7 [Cheng Pan] exclude
7d5028154 [Cheng Pan] Support javax.servlet and jakarta.servlet co-exist
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
This pull request
- improves comments for SPARK-33832
- removes unused `spark.sql.analyzer.classification.enabled` (I didn't update the migration rules because this configuration seems never to work properly)
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
Review
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6260 from pan3793/nit.
Closes#6260
d762d30e9 [Cheng Pan] update comment
4ebaa04ea [Cheng Pan] nit
b303f05bb [Cheng Pan] remove spark.sql.analyzer.classification.enabled
b021cbc0a [Cheng Pan] Improve docs for SPARK-33832
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
## Issue References 🔗
This pull request fixes #
## Describe Your Solution 🔧
We should check `spark.memory.offHeap.enabled` when applying for `executorOffHeapMemory`.
## Types of changes 🔖
- [X] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
#### Behavior Without This Pull Request ⚰️
#### Behavior With This Pull Request 🎉
#### Related Unit Tests
---
# Checklist 📝
- [X] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6211 from wForget/hotfix.
Closes#6211
1c7c8cd75 [wforget] Check memory offHeap enabled for CustomResourceProfileExec
Authored-by: wforget <643348094@qq.com>
Signed-off-by: wforget <643348094@qq.com>
# 🔍 Description
## Issue References 🔗
SPARK-33212 (fixed in 3.2.0) moves from `hadoop-client` to shaded hadoop client, to simplify the dependency management, previously , we add some workaround to handle Spark 3.1 dependency issues. As we removed building support for Spark 3.1 now, we can remove those workaround to simplify `pom.xml`
## Describe Your Solution 🔧
As above.
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
Pass GA.
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6131 from pan3793/3-1-cleanup.
Closes#6131
1341065a7 [Cheng Pan] nit
1d7323f6e [Cheng Pan] fix
9e2e3b747 [Cheng Pan] nit
271166b58 [Cheng Pan] test
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
## Issue References 🔗
This pull request is the next step of deprecating and removing support of Spark 3.1
VOTE: https://lists.apache.org/thread/670fx1qx7rm0vpvk8k8094q2d0fthw5b
VOTE RESULT: https://lists.apache.org/thread/0zdxg5zjnc1wpxmw9mgtsxp1ywqt6qvb
## Describe Your Solution 🔧
Drop module `kyuubi-extension-spark-3-1` and delete Spark 3.1 specific codes.
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
Pass GA.
---
# Checklist 📝
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
**Be nice. Be informative.**
Closes#6125 from pan3793/drop-spark-ext-3-1.
Closes#6125
212012f18 [Cheng Pan] fix style
021532ccd [Cheng Pan] doc
329f69ab9 [Cheng Pan] address comments
43fac4201 [Cheng Pan] fix
a12c8062c [Cheng Pan] fix
dcf51c1a1 [Cheng Pan] minor
814a187a6 [Cheng Pan] Drop Kyuubi extension for Spark 3.1
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
# 🔍 Description
## Issue References 🔗
This pull request fixes#5816
## Describe Your Solution 🔧
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
#### Behavior Without This Pull Request ⚰️
#### Behavior With This Pull Request 🎉
#### Related Unit Tests
---
# Checklists
## 📝 Author Self Checklist
- [ ] My code follows the [style guidelines](https://kyuubi.readthedocs.io/en/master/contributing/code/style.html) of this project
- [ ] I have performed a self-review
- [ ] I have commented my code, particularly in hard-to-understand areas
- [ ] I have made corresponding changes to the documentation
- [ ] My changes generate no new warnings
- [ ] I have added tests that prove my fix is effective or that my feature works
- [ ] New and existing unit tests pass locally with my changes
- [ ] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
## 📝 Committer Pre-Merge Checklist
- [ ] Pull request title is okay.
- [ ] No license issues.
- [ ] Milestone correctly set?
- [ ] Test coverage is ok
- [ ] Assignees are selected.
- [ ] Minimum number of approvals
- [ ] No changes are requested
**Be nice. Be informative.**
Closes#5817 from zml1206/KYUUBI-5816.
Closes#5816
437dd1f27 [zml1206] Change spark rule class to object or case class
Authored-by: zml1206 <zhuml1206@gmail.com>
Signed-off-by: wforget <643348094@qq.com>
# 🔍 Description
## Issue References 🔗
This pull request fixes#5786.
## Describe Your Solution 🔧
Add spark check rule.
## Types of changes 🔖
- [ ] Bugfix (non-breaking change which fixes an issue)
- [x] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
## Test Plan 🧪
#### Behavior Without This Pull Request ⚰️
#### Behavior With This Pull Request 🎉
#### Related Unit Tests
org.apache.kyuubi.plugin.spark.authz.rule.AuthzUnsupportedOperationsCheckSuite.test("disable script transformation")
---
# Checklists
## 📝 Author Self Checklist
- [x] My code follows the [style guidelines](https://kyuubi.readthedocs.io/en/master/contributing/code/style.html) of this project
- [x] I have performed a self-review
- [ ] I have commented my code, particularly in hard-to-understand areas
- [ ] I have made corresponding changes to the documentation
- [x] My changes generate no new warnings
- [x] I have added tests that prove my fix is effective or that my feature works
- [ ] New and existing unit tests pass locally with my changes
- [x] This patch was not authored or co-authored using [Generative Tooling](https://www.apache.org/legal/generative-tooling.html)
## 📝 Committer Pre-Merge Checklist
- [ ] Pull request title is okay.
- [ ] No license issues.
- [ ] Milestone correctly set?
- [ ] Test coverage is ok
- [ ] Assignees are selected.
- [ ] Minimum number of approvals
- [ ] No changes are requested
**Be nice. Be informative.**
Closes#5788 from zml1206/KYUUBI-5786.
Closes#5786
06c0098be [zml1206] fix
e2c3fee22 [zml1206] fix
37744f4c3 [zml1206] move to spark extentions
deb09fb30 [zml1206] add configuration
cfea4845a [zml1206] Disable spark script transformation in Authz
Authored-by: zml1206 <zhuml1206@gmail.com>
Signed-off-by: wforget <643348094@qq.com>
### _Why are the changes needed?_
The Apache Spark Community found a performance regression with log4j2. See https://github.com/apache/spark/pull/36747.
This PR to fix the performance issue on our side.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5400 from ITzhangqiang/KYUUBI_5365.
Closes#5365
dbb9d8b32 [ITzhangqiang] [KYUUBI #5365] Don't use Log4j2's extended throwable conversion pattern in default logging configurations
Authored-by: ITzhangqiang <itzhangqiang@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- Change hardcoded Scala's version 2.12 in Maven module's `artifactId` to placeholder `scala.binary.version` which is defined in project parent pom as 2.12
- Preparation for Scala 2.13/3.x support in the future
- No impact on using or building Maven modules
- Some ignorable warning messages for unstable artifactId will be thrown by Maven.
```
Warning: Some problems were encountered while building the effective model for org.apache.kyuubi:kyuubi-server_2.12🫙1.8.0-SNAPSHOT
Warning: 'artifactId' contains an expression but should be a constant
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/contributing/code/testing.html#running-tests) locally before make a pull request
### _Was this patch authored or co-authored using generative AI tooling?_
No.
Closes#5175 from bowenliang123/artifactId-scala.
Closes#5177
2eba29cfa [liangbowen] use placeholder of scala binary version for artifactId
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
In minor cases, Spark Stage hangs forever when spark.sql.finalWriteStage.eagerlyKillExecutors.enabled is true.
The bug occurs if two conditions are met in the same time:
1. All executors are either removed because of idle time out or killed by FinalStageResourceManager.
Target executor num in YarnAllocator will be set to 0 and no more executor will be launched.
2. Target executor num in ExecutorAllocationManager equals to the executor num needed by final stage.
Then ExecutorAllocationManager will not sync target executor num to YarnAllocator.
### _How was this patch tested?_
- [x] Add a new test suite `FinalStageResourceManagerSuite`
Closes#5141 from zhouyifan279/adjust-executors.
Closes#5136
c4403eefa [zhouyifan279] assert adjustedTargetExecutors == 1
ea8f24733 [zhouyifan279] Add comment
5f3ca1d9c [zhouyifan279] [KYUUBI #5136][Bug] Spark App may hang forever if FinalStageResourceManager killed all executors
12687eee7 [zhouyifan279] [KYUUBI #5136][Bug] Spark App may hang forever if FinalStageResourceManager killed all executors
9dcbc780d [zhouyifan279] [KYUUBI #5136][Bug] Spark App may hang forever if FinalStageResourceManager killed all executors
Authored-by: zhouyifan279 <zhouyifan279@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
to close#1265
After this PR, the following case will work
```sql
CREATE TABLE p (c1 INT, c2 INT, c3 INT) PARTITIONED BY (event_date DATE);
OPTIMIZE p where event_date = current_date() ZORDER BY c1, c2;
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#2893 from cfmcgrady/where-expression-support.
Closes#1265
97ac710f0 [Fu Chen] Merge remote-tracking branch 'apache/master' into where-expression-support
c188f0b3d [Fu Chen] fix style
e5f7409d6 [Fu Chen] move verifyPartitionPredicates to KyuubiSparkSQLAstBuilder
f7234abba [Fu Chen] fix style
95d314122 [Fu Chen] fork PredicateHelper.isLikelySelective
1e596e3dd [Fu Chen] partition predicates constraint
541e373cc [Fu Chen] fix
06d9efdf0 [Fu Chen] adapt to spark-3.1/spark-3.2 suite
867263673 [Fu Chen] fix style
b6801b279 [Fu Chen] add test case
79ab60554 [Fu Chen] fix suite bug
cf1b16ee7 [Fu Chen] fix style
dc0ebd908 [Fu Chen] add ut
286d94cc6 [Fu Chen] fix style
1736d18f6 [Fu Chen] adapt to spark-3.1/spark-3.2
04e88a5aa [Fu Chen] fix nep
59103095b [Fu Chen] simplify logical
59fba01e4 [Fu Chen] adapt to spark-3.1
e6477a9c5 [Fu Chen] remove unused
855283e20 [Fu Chen] where clause expression support
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Fu Chen <cfmcgrady@gmail.com>
### _Why are the changes needed?_
When FinalStageResourceManager chooses executors to be killed, it may add dead executors to the kill list.
This will leave more than target num of executors survived and cause resource waste.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4936 from zhouyifan279/kill-executor.
Closes#4936
2aaa84cb1 [zhouyifan279] [KYUUBI#4935][Improvement] More than target num of executors may survive after FinalStageResourceManager did kill
Authored-by: zhouyifan279 <zhouyifan279@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Close#4870
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4872 from pan3793/util.
Closes#4870
0b9fe3cba [Cheng Pan] nit
ecc5ee4f2 [Cheng Pan] fix
63be7a20c [Cheng Pan] test
85363c187 [Cheng Pan] style
2227247dd [Cheng Pan] fix package
11d10a081 [Cheng Pan] Add kyuubi-util and kyuubi-util-scala modules
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Add MaxFileSizeStrategy to limit max scan file size.
close#4641
### _How was this patch tested?_
- [X] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4642 from wForget/KYUUBI-4641.
Closes#4641
14a680f8e [wforget] comment
d2a393d97 [wforget] comment
b1ef4c52c [wforget] fix
d9e94bd8e [wforget] fix style
8a9121131 [wforget] use optional value
094eb61e3 [wforget] combine
89e2cb4d0 [wforget] [KYUUBI-4641] Add MaxFileSizeStrategy to limit max scan file size
Authored-by: wforget <643348094@qq.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
This pr change two things:
1. add a config to kill executors if the plan contains table caches. It's not always safe to kill executors if the cache is referenced by two write-like plan.
2. force adjustTargetNumExecutors when killing executors. YarnAllocator` might re-request original target executors if DRA has not updated target executors yet. Note, DRA would re-adjust executors if there are more tasks to be executed, so we are safe. It's better to adjuest target num executor once we kill executors.
### _How was this patch tested?_
These issues are found during my POC
Closes#4678 from ulysses-you/skip-cache.
Closes#4678
b12620954 [ulysses-you] Improve kill executors
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
This pr fixes a corner case when repartition on a local relation. e.g.,
```
Repartition
|
LocalRelation
```
it would throw exception since there is no a actually shuffle happen
```
java.util.NoSuchElementException: key not found: 3
at scala.collection.MapLike.default(MapLike.scala:235)
at scala.collection.MapLike.default$(MapLike.scala:234)
at scala.collection.AbstractMap.default(Map.scala:63)
at scala.collection.MapLike.apply(MapLike.scala:144)
at scala.collection.MapLike.apply$(MapLike.scala:143)
at scala.collection.AbstractMap.apply(Map.scala:63)
at org.apache.spark.sql.FinalStageResourceManager.findExecutorToKill(FinalStageResourceManager.scala:122)
at org.apache.spark.sql.FinalStageResourceManager.killExecutors(FinalStageResourceManager.scala:175)
```
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#4664 from ulysses-you/kill-executors-followup.
Closes#4664
3811eaee9 [ulysses-you] Fix empty relation
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
This pr improves the behavoir of kill redundant executors.
1. support kill executors even if AQE can not optimize shuffle read. e.g., people call `.repartition(2)`
2. fix a issue that avoid always kill executors which holds shuffle data
### _How was this patch tested?_
test manually
Closes#4636 from ulysses-you/kill-executors.
Closes#4636
19ac808d3 [ulysses-you] Improve eagerly kill redundant executors
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
Add a new rule `InjectCustomResourceProfile` to support custom resource profile for final write stage.
It now supports executor configs:
```
executor core
executor memory
executor memory overhead
executor off heap memory
```
### _How was this patch tested?_
add test and manully test
<img width="778" alt="image" src="https://user-images.githubusercontent.com/12025282/226606147-82a29b8c-1a31-4842-97a7-fe702d80e190.png">
Closes#4615 from ulysses-you/resource-profile.
Closes#4615
852b207cd [ulysses-you] Support stage level schedule for final write stag
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
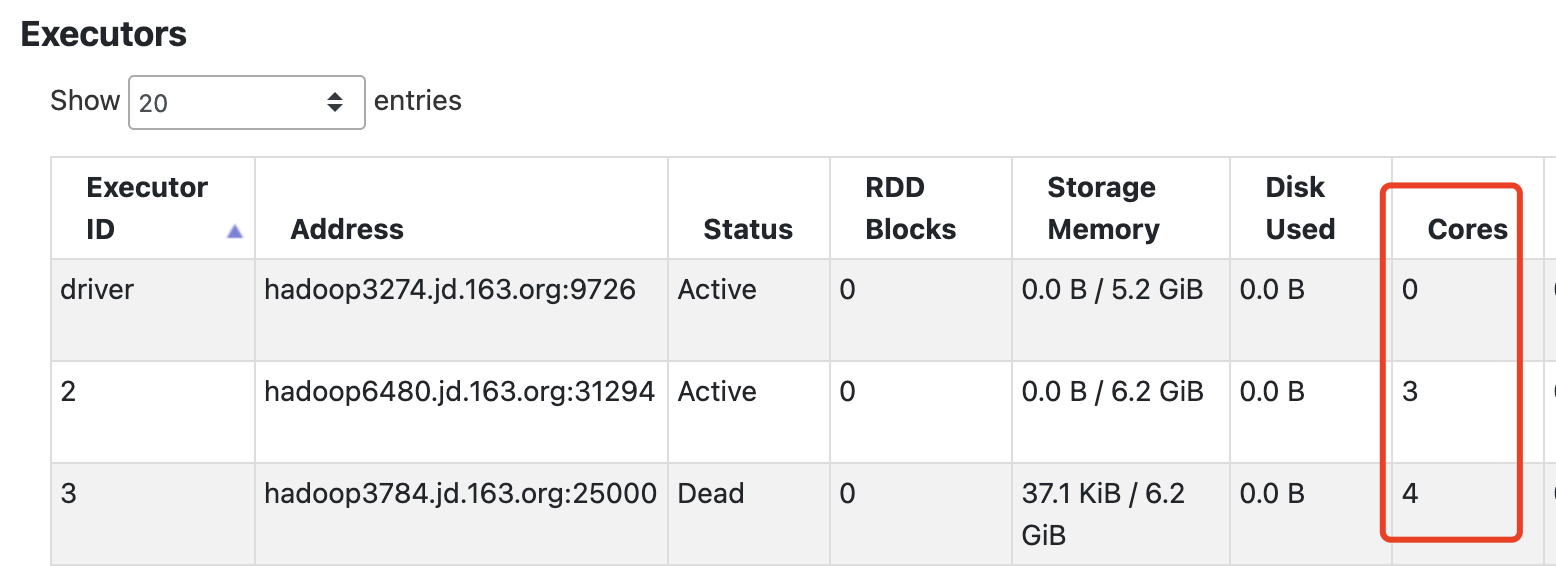
### _Why are the changes needed?_
This pr adds a new rule `FinalStageResourceManager` to eagerly kill redundant executors
We first get the final stage partition which is the actually required cores, then kill the redundant executors. The priority of kill executors follow:
1. kill executor who is younger than other (The older the JIT works better)
2. kill executor who produces less shuffle data first
The reason why add this feature is that, if the previous stage contains lots executors but final stage has less, then the tasks of final stage would be scheduled randomly in all exists executors which may cause resource waste. e.g., each executor only run 1 or 2 tasks but holds 4 or 5 cores.
### _How was this patch tested?_
test manually
- test for the kill executor
<img width="755" alt="image" src="https://user-images.githubusercontent.com/12025282/227203809-9fe0731c-f97f-40d2-ac7f-b892a2a35289.png">
Closes#4592 from ulysses-you/eagerly-kill-executors.
Closes#4592
f35208bfd [ulysses-you] nit
ec627ee4f [ulysses-you] nit
28d4230f8 [ulysses-you] address comments
f2492cec6 [ulysses-you] nit
f44e48451 [ulysses-you] Support eagerly kill redundant executors
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulyssesyou <ulyssesyou@apache.org>
### _Why are the changes needed?_
Detect and inject a tag if plan is for writing, then skip doing final stage isolation at query preparation phase.
To make final stage config more flexible with complex Spark application.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3988 from ulysses-you/final-stage.
Closes#3988
d0f2b622 [ulysses-you] fix
e5351fd5 [ulysses-you] nit
39082b20 [ulysses-you] Final stage config isolation support write only
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulysses-you <ulyssesyou@apache.org>
### _Why are the changes needed?_
add two conditions to decide if we should add shuffle.
1. make sure AQE is enabled, otherwise it is no meaning to add a shuffle
2. try to reduce the performance regression if add a shuffle
for condition 2: we do not add shuffle if the original plan does not have shuffle
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3962 from ulysses-you/no-shuffle.
Closes#3962
a084cccc [ulysses-you] address comment
9d0aab1b [ulysses-you] address comment
09fc9b21 [ulysses-you] fix ut
06f249a2 [ulysses-you] Reduce the performance regression
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulysses-you <ulyssesyou@apache.org>
### _Why are the changes needed?_
1. to fix#3893
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3894 from FireFoxAhri/master.
Closes#3893
da15a000 [firefox] [KYUUBI #3893] [BUG] Fix spark extension: UnspecifiedDistribution does not have default partitioning.
Authored-by: firefox <309637962@qq.com>
Signed-off-by: ulysses-you <ulyssesyou@apache.org>
### _Why are the changes needed?_
Introduce code style check support for Maven's pom.xml with sortPom in spotless maven plugin.
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3843 from bowenliang123/spotless-pom.
Closes#3842
3c654597 [liangbowen] apply to pom.xml
fd1536f7 [liangbowen] set expandEmptyElements to true
e498423f [liangbowen] apply spotless:apply to all pom.xml
e46bcfec [liangbowen] add pom style check support in spotless
Authored-by: liangbowen <liangbowen@gf.com.cn>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
Improve the rebalance before writing rule.
The rebalance before writing rule adds a rebalance at the top of query for data writing command, however the default partitioning of rebalance uses RoundRobinPartitioning which would break the original partitioning of data. It may cause the the output data size bigger than before.
This pr supports infer the columns from join and aggregate for rebalance and sort to improve the compression ratio.
Note that, this improvement only works for static partition writing.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3601 from ulysses-you/smart-order.
Closes#3601
c190dc1a [ulysses-you] docs
995969b5 [ulysses-you] view
ea23c417 [ulysses-you] Support infer columns for rebalance and sort
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulysses-you <ulyssesyou@apache.org>
### _Why are the changes needed?_
Preparing v1.7.0-SNAPSHOT with branch-1.6 cut
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#3264 from SteNicholas/prepare-1.7.0-snapshot.
Closes#3264
374d56bf [SteNicholas] preparing v1.7.0-SNAPSHOT with branch-1.6 cut
Authored-by: SteNicholas <programgeek@163.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
- change log4j2-test.properties to log4j2-test.xml
- add the unit test log4j2.xml for spark relative submodule, and remove the log4j.properties
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#2850 from cfmcgrady/kyuubi-2247.
Closes#2247
a33d4d80 [Fu Chen] style
f99dadac [Fu Chen] fix style
49c99dea [Fu Chen] add log4j2.xml for spark relative submodule
a8a38561 [Fu Chen] change log4j2-test.properties to log4j2-test.xml
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### _Why are the changes needed?_
We can inject rebalance before Z-Order to avoid data skew.
### _How was this patch tested?_
- [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [ ] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#2830 from ulysses-you/improve-zorder.
Closes#2830
789aba45 [ulysses-you] cleanup
e169a202 [ulysses-you] resolver
9134496c [ulysses-you] style
048fe294 [ulysses-you] docs
e06f1ef8 [ulysses-you] imporve zorder
Authored-by: ulysses-you <ulyssesyou18@gmail.com>
Signed-off-by: ulysses-you <ulyssesyou@apache.org>
### _Why are the changes needed?_
to close#2706
Spark extensions support Spark-3.3, part of #2620
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run test](https://kyuubi.apache.org/docs/latest/develop_tools/testing.html#running-tests) locally before make a pull request
Closes#2707 from cfmcgrady/kyuubi-2706.
Closes#2706
0b07b6e4 [Fu Chen] spark extensions support spark 3.3
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
{kind=link}
{kind=link}