[KYUUBI #1086] Add maxHivePartitions Strategy to avoid scanning excessive hive partitions on partitioned table
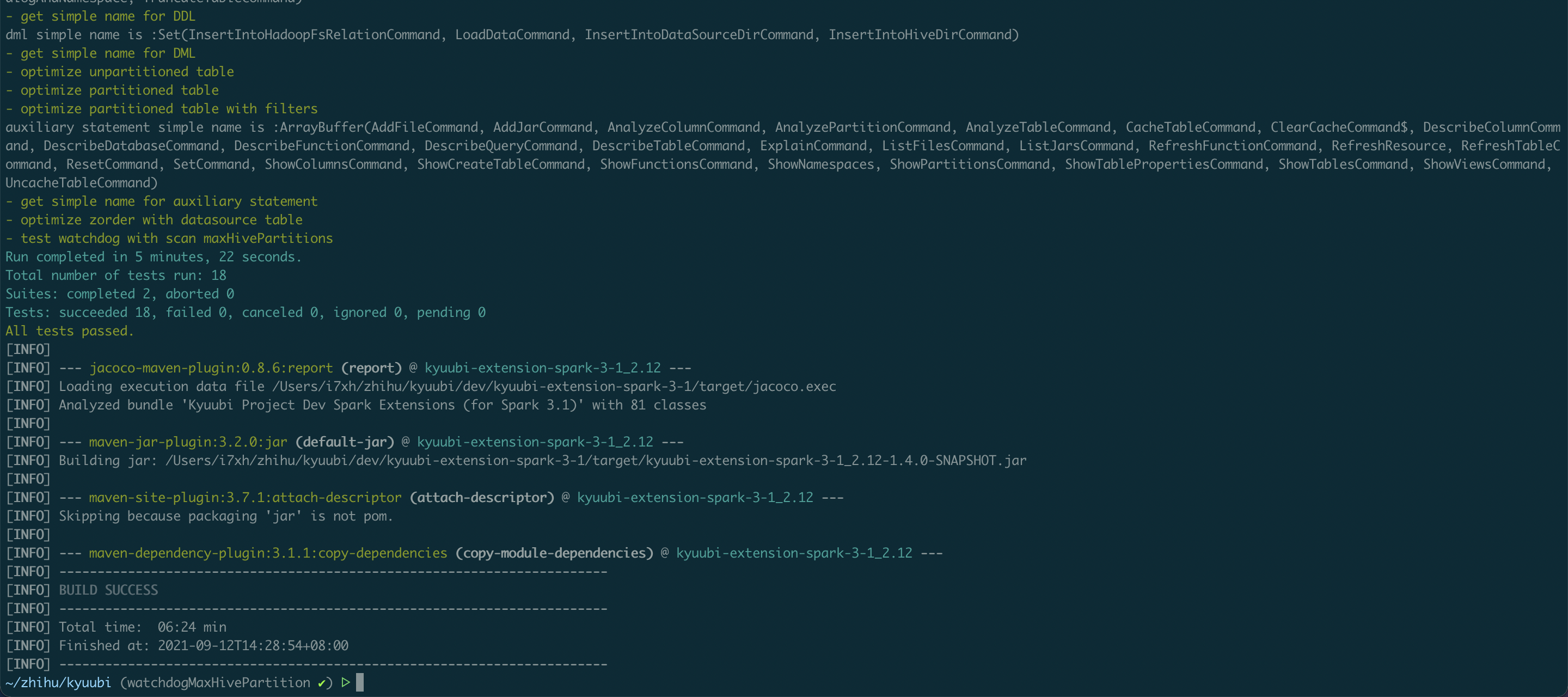
<!-- Thanks for sending a pull request! Here are some tips for you: 1. If this is your first time, please read our contributor guidelines: https://kyuubi.readthedocs.io/en/latest/community/contributions.html 2. If the PR is related to an issue in https://github.com/apache/incubator-kyuubi/issues, add '[KYUUBI #XXXX]' in your PR title, e.g., '[KYUUBI #XXXX] Your PR title ...'. 3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][KYUUBI #XXXX] Your PR title ...'. --> ### _Why are the changes needed?_ <!-- Please clarify why the changes are needed. For instance, 1. If you add a feature, you can talk about the use case of it. 2. If you fix a bug, you can clarify why it is a bug. --> The PR support this Strategy to avoid scan huge hive partitions or unused necessary partition filter on partitioned table,It will abort the SQL query with thrown exception via scan hive table partitions exceed `spark.sql.watchdog.maxHivePartitions`, meanwhile show the related hive table partition struct to assist user to optimize sql according the given suggestion ### _How was this patch tested?_ - [x] Add some test cases that check the changes thoroughly including negative and positive cases if possible - [x] Add screenshots for manual tests if appropriate <img width="1440" alt="截屏2021-09-12 下午2 30 20" src="https://user-images.githubusercontent.com/635169/132974627-7879ee2b-4624-4bb4-bec9-3ed0940c3986.png"> - [x] [Run test](https://kyuubi.readthedocs.io/en/latest/develop_tools/testing.html#running-tests) locally before make a pull request Closes #1086 from i7xh/watchdogMaxHivePartition. Closes #1086 d535b57e [h] Fixed: scala style newline of end 774a486f [h] Resolved isssue: shrink unnesscary test data 0541dcc5 [h] Resovled issue: replace listPartitions with listPartitionNames 5a97c5d0 [h] Resolved issue: unify Exceed maxHivePartitions without partition filter 1581b297 [h] resovled the code review issues d0b0fc46 [h] Add maxHivePartitions Strategy to avoid scan excessive hive partitions on partitioned table Authored-by: h <h@zhihu.com> Signed-off-by: ulysses-you <ulyssesyou@apache.org>
{kind=link}
This commit is contained in:
parent
395c6323cc
commit
9dfbd2b830
@ -86,4 +86,12 @@ object KyuubiSQLConf {
|
||||
.version("1.4.0")
|
||||
.booleanConf
|
||||
.createWithDefault(true)
|
||||
|
||||
val WATCHDOG_MAX_HIVEPARTITION =
|
||||
buildConf("spark.sql.watchdog.maxHivePartitions")
|
||||
.doc("Add maxHivePartitions Strategy to avoid scan excessive " +
|
||||
"hive partitions on partitioned table, it's optional that works with defined")
|
||||
.version("1.4.0")
|
||||
.intConf
|
||||
.createOptional
|
||||
}
|
||||
|
||||
@ -20,7 +20,10 @@ package org.apache.kyuubi.sql
|
||||
import org.apache.spark.sql.SparkSessionExtensions
|
||||
|
||||
import org.apache.kyuubi.sql.sqlclassification.KyuubiSqlClassification
|
||||
import org.apache.kyuubi.sql.watchdog.MaxHivePartitionStrategy
|
||||
import org.apache.kyuubi.sql.zorder.{InsertZorderBeforeWritingDatasource, InsertZorderBeforeWritingHive, ResolveZorder, ZorderSparkSqlExtensionsParser}
|
||||
import org.apache.kyuubi.sql.zorder.ResolveZorder
|
||||
import org.apache.kyuubi.sql.zorder.ZorderSparkSqlExtensionsParser
|
||||
|
||||
// scalastyle:off line.size.limit
|
||||
/**
|
||||
@ -49,5 +52,6 @@ class KyuubiSparkSQLExtension extends (SparkSessionExtensions => Unit) {
|
||||
extensions.injectPostHocResolutionRule(FinalStageConfigIsolationCleanRule)
|
||||
extensions.injectQueryStagePrepRule(_ => InsertShuffleNodeBeforeJoin)
|
||||
extensions.injectQueryStagePrepRule(FinalStageConfigIsolation(_))
|
||||
extensions.injectPlannerStrategy(MaxHivePartitionStrategy)
|
||||
}
|
||||
}
|
||||
|
||||
@ -0,0 +1,25 @@
|
||||
/*
|
||||
* Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
* contributor license agreements. See the NOTICE file distributed with
|
||||
* this work for additional information regarding copyright ownership.
|
||||
* The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
* (the "License"); you may not use this file except in compliance with
|
||||
* the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
package org.apache.kyuubi.sql.watchdog
|
||||
|
||||
import org.apache.kyuubi.sql.KyuubiSQLExtensionException
|
||||
|
||||
final class MaxHivePartitionExceedException(
|
||||
private val reason: String = "",
|
||||
private val cause: Throwable = None.orNull)
|
||||
extends KyuubiSQLExtensionException(reason, cause)
|
||||
@ -0,0 +1,78 @@
|
||||
/*
|
||||
* Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
* contributor license agreements. See the NOTICE file distributed with
|
||||
* this work for additional information regarding copyright ownership.
|
||||
* The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
* (the "License"); you may not use this file except in compliance with
|
||||
* the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing, software
|
||||
* distributed under the License is distributed on an "AS IS" BASIS,
|
||||
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
* See the License for the specific language governing permissions and
|
||||
* limitations under the License.
|
||||
*/
|
||||
|
||||
package org.apache.kyuubi.sql.watchdog
|
||||
|
||||
import org.apache.spark.sql.{SparkSession, Strategy}
|
||||
import org.apache.spark.sql.catalyst.SQLConfHelper
|
||||
import org.apache.spark.sql.catalyst.catalog.HiveTableRelation
|
||||
import org.apache.spark.sql.catalyst.planning.ScanOperation
|
||||
import org.apache.spark.sql.catalyst.plans.logical.LogicalPlan
|
||||
import org.apache.spark.sql.execution.SparkPlan
|
||||
|
||||
import org.apache.kyuubi.sql.KyuubiSQLConf
|
||||
|
||||
/**
|
||||
* Add maxHivePartitions Strategy to avoid scan excessive hive partitions on partitioned table
|
||||
* 1 Check if scan exceed maxHivePartition
|
||||
* 2 Check if Using partitionFilter on partitioned table
|
||||
* This Strategy Add Planner Strategy after LogicalOptimizer
|
||||
*/
|
||||
case class MaxHivePartitionStrategy(session: SparkSession)
|
||||
extends Strategy with SQLConfHelper {
|
||||
override def apply(plan: LogicalPlan): Seq[SparkPlan] = {
|
||||
conf.getConf(KyuubiSQLConf.WATCHDOG_MAX_HIVEPARTITION) match {
|
||||
case Some(maxHivePartition) => plan match {
|
||||
case ScanOperation(_, _, relation: HiveTableRelation) if relation.isPartitioned =>
|
||||
relation.prunedPartitions match {
|
||||
case Some(prunedPartitions) => if (prunedPartitions.size > maxHivePartition) {
|
||||
throw new MaxHivePartitionExceedException(
|
||||
s"""
|
||||
|SQL job scan hive partition: ${prunedPartitions.size}
|
||||
|exceed restrict of hive scan maxPartition $maxHivePartition
|
||||
|You should optimize your SQL logical according partition structure
|
||||
|or shorten query scope such as p_date, detail as below:
|
||||
|Table: ${relation.tableMeta.qualifiedName}
|
||||
|Owner: ${relation.tableMeta.owner}
|
||||
|Partition Structure: ${relation.partitionCols.map(_.name).mkString(" -> ")}
|
||||
|""".stripMargin)
|
||||
} else {
|
||||
Nil
|
||||
}
|
||||
case _ => val totalPartitions = session
|
||||
.sessionState.catalog.externalCatalog.listPartitionNames(
|
||||
relation.tableMeta.database, relation.tableMeta.identifier.table)
|
||||
if (totalPartitions.size > maxHivePartition) {
|
||||
throw new MaxHivePartitionExceedException(
|
||||
s"""
|
||||
|Your SQL job scan a whole huge table without any partition filter,
|
||||
|You should optimize your SQL logical according partition structure
|
||||
|or shorten query scope such as p_date, detail as below:
|
||||
|Table: ${relation.tableMeta.qualifiedName}
|
||||
|Owner: ${relation.tableMeta.owner}
|
||||
|Partition Structure: ${relation.partitionCols.map(_.name).mkString(" -> ")}
|
||||
|""".stripMargin)
|
||||
} else {
|
||||
Nil
|
||||
}
|
||||
}
|
||||
case _ => Nil
|
||||
}
|
||||
case _ => Nil
|
||||
}
|
||||
}
|
||||
}
|
||||
@ -31,8 +31,8 @@ import org.apache.spark.sql.internal.{SQLConf, StaticSQLConf}
|
||||
import org.apache.spark.sql.test.SQLTestData.TestData
|
||||
import org.apache.spark.sql.test.SQLTestUtils
|
||||
|
||||
import org.apache.kyuubi.sql.{FinalStageConfigIsolation, KyuubiSQLConf}
|
||||
import org.apache.kyuubi.sql.KyuubiSQLExtensionException
|
||||
import org.apache.kyuubi.sql.{FinalStageConfigIsolation, KyuubiSQLConf, KyuubiSQLExtensionException}
|
||||
import org.apache.kyuubi.sql.watchdog.MaxHivePartitionExceedException
|
||||
import org.apache.kyuubi.sql.zorder.Zorder
|
||||
|
||||
class KyuubiExtensionSuite extends QueryTest with SQLTestUtils with AdaptiveSparkPlanHelper {
|
||||
@ -1584,4 +1584,40 @@ class KyuubiExtensionSuite extends QueryTest with SQLTestUtils with AdaptiveSpar
|
||||
checkZorderTable(true, "c4, c2, c1, c3", false, true)
|
||||
}
|
||||
}
|
||||
|
||||
test("test watchdog with scan maxHivePartitions") {
|
||||
withTable("test", "temp") {
|
||||
sql(
|
||||
s"""
|
||||
|CREATE TABLE test(i int)
|
||||
|PARTITIONED BY (p int)
|
||||
|STORED AS textfile""".stripMargin)
|
||||
spark.range(0, 10, 1).selectExpr("id as col")
|
||||
.createOrReplaceTempView("temp")
|
||||
|
||||
for (part <- Range(0, 10)) {
|
||||
sql(
|
||||
s"""
|
||||
|INSERT OVERWRITE TABLE test PARTITION (p='$part')
|
||||
|select col from temp""".stripMargin)
|
||||
}
|
||||
|
||||
withSQLConf(KyuubiSQLConf.WATCHDOG_MAX_HIVEPARTITION.key -> "5") {
|
||||
|
||||
sql("SELECT * FROM test where p=1").queryExecution.sparkPlan
|
||||
|
||||
sql(
|
||||
s"SELECT * FROM test WHERE p in (${Range(0, 5).toList.mkString(",")})")
|
||||
.queryExecution.sparkPlan
|
||||
|
||||
intercept[MaxHivePartitionExceedException](
|
||||
sql("SELECT * FROM test").queryExecution.sparkPlan)
|
||||
|
||||
intercept[MaxHivePartitionExceedException](sql(
|
||||
s"SELECT * FROM test WHERE p in (${Range(0, 6).toList.mkString(",")})")
|
||||
.queryExecution.sparkPlan)
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
Loading…
Reference in New Issue
Block a user