### What changes were proposed in this pull request?
Refresh celeborn configurations in doc
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1592 from AngersZhuuuu/CELEBORN-680.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Celeborn fetch chunk also should support check timeout
#### Test case
```
executor instance 20
SQL:
SELECT count(1) from (select /*+ REPARTITION(100) */ * from spark_auxiliary.t50g) tmp;
--conf spark.celeborn.client.spark.shuffle.writer=sort \
--conf spark.celeborn.client.fetch.excludeWorkerOnFailure.enabled=true \
--conf spark.celeborn.client.push.timeout=10s \
--conf spark.celeborn.client.push.replicate.enabled=true \
--conf spark.celeborn.client.push.revive.maxRetries=10 \
--conf spark.celeborn.client.reserveSlots.maxRetries=10 \
--conf spark.celeborn.client.registerShuffle.maxRetries=3 \
--conf spark.celeborn.client.push.blacklist.enabled=true \
--conf spark.celeborn.client.blacklistSlave.enabled=true \
--conf spark.celeborn.client.fetch.timeout=30s \
--conf spark.celeborn.client.push.data.timeout=30s \
--conf spark.celeborn.client.push.limit.inFlight.timeout=600s \
--conf spark.celeborn.client.push.maxReqsInFlight=32 \
--conf spark.celeborn.client.shuffle.compression.codec=ZSTD \
--conf spark.celeborn.rpc.askTimeout=30s \
--conf spark.celeborn.client.rpc.reserveSlots.askTimeout=30s \
--conf spark.celeborn.client.shuffle.batchHandleChangePartition.enabled=true \
--conf spark.celeborn.client.shuffle.batchHandleCommitPartition.enabled=true \
--conf spark.celeborn.client.shuffle.batchHandleReleasePartition.enabled=true
```
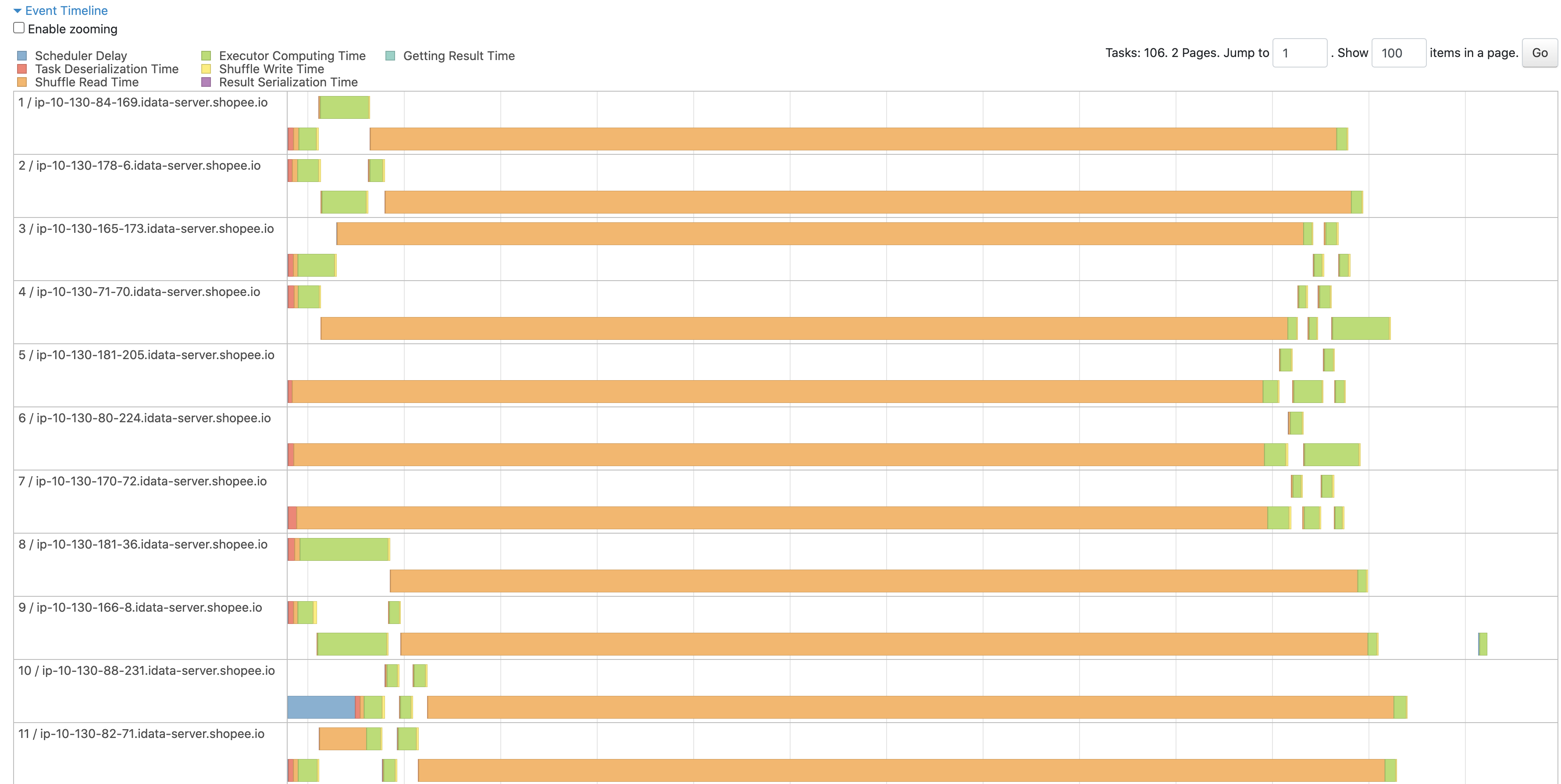
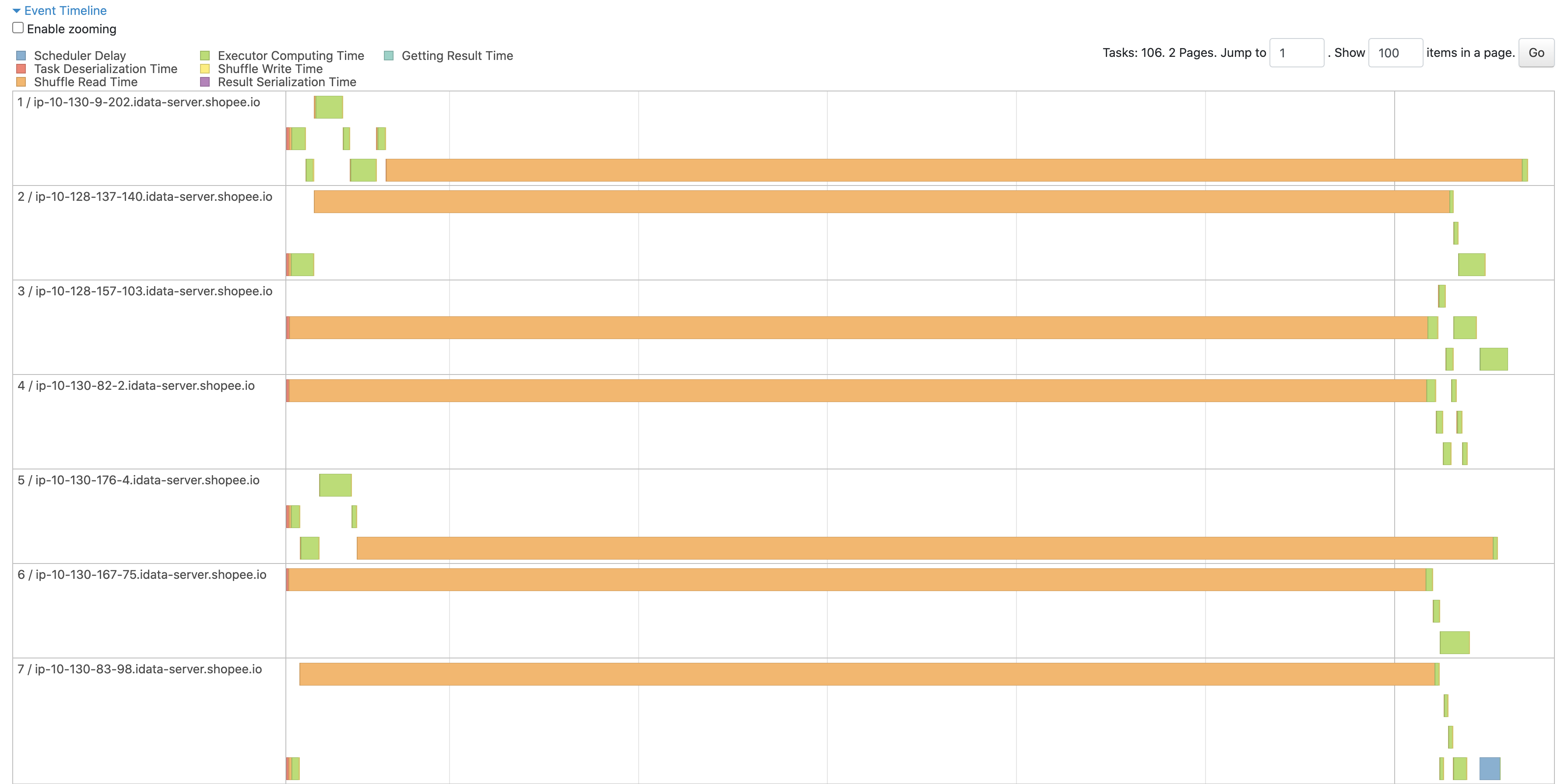
Test with 3 worker and add a `Thread.sleep(100s)` before worker handle `ChunkFetchRequest`
Before patch
<img width="1783" alt="截屏2023-06-14 上午11 20 55" src="https://github.com/apache/incubator-celeborn/assets/46485123/182dff7d-a057-4077-8368-d1552104d206">
After patch
<img width="1792" alt="image" src="https://github.com/apache/incubator-celeborn/assets/46485123/3c8b7933-8ace-426d-8e9f-04e0aabfac8e">
The log shows the fetch timeout checker workers
```
23/06/14 11:14:54 ERROR WorkerPartitionReader: Fetch chunk 0 failed.
org.apache.celeborn.common.exception.CelebornIOException: FETCH_DATA_TIMEOUT
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:147)
at org.apache.celeborn.common.network.client.TransportResponseHandler.lambda$new$1(TransportResponseHandler.java:103)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
23/06/14 11:14:54 WARN RssInputStream: Fetch chunk failed 1/6 times for location PartitionLocation[
id-epoch:35-0
host-rpcPort-pushPort-fetchPort-replicatePort:10.169.48.203-9092-9094-9093-9095
mode:MASTER
peer:(host-rpcPort-pushPort-fetchPort-replicatePort:10.169.48.202-9092-9094-9093-9095)
storage hint:StorageInfo{type=HDD, mountPoint='/mnt/ssd/0', finalResult=true, filePath=}
mapIdBitMap:null], change to peer
org.apache.celeborn.common.exception.CelebornIOException: Fetch chunk 0 failed.
at org.apache.celeborn.client.read.WorkerPartitionReader$1.onFailure(WorkerPartitionReader.java:98)
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:146)
at org.apache.celeborn.common.network.client.TransportResponseHandler.lambda$new$1(TransportResponseHandler.java:103)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.celeborn.common.exception.CelebornIOException: FETCH_DATA_TIMEOUT
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:147)
... 8 more
23/06/14 11:14:54 INFO SortBasedShuffleWriter: Memory used 72.0 MB
```
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1587 from AngersZhuuuu/CELEBORN-676.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Add celeborn.metrics.conf to conf entity
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1593 from AngersZhuuuu/CELEBORN-681.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
refer to https://github.com/apache/spark/pull/40301
1. Optimize `Utils.bytesToString`. Arithmetic ops on BigInt and BigDecimal are order(s) of magnitude slower than the ops on primitive types. Division is an especially slow operation and it is used en masse here.
2. According to the information sourced from [Wikipedia](https://en.wikipedia.org/wiki/Kilobyte), it is established that 1000 is the appropriate factor for representing kilobytes (KB), while 1024 is the correct factor for kibibytes (KiB). In alignment with this understanding, changing the size unit from "KB" to "KiB".
### Why are the changes needed?
the Utils#bytesToString method is frequently employed in memory-related log messages.
### Does this PR introduce _any_ user-facing change?
No, only perf improvement.
### How was this patch tested?
existing UT and manually tested.
Closes#1590 from cfmcgrady/bytesToString.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Give Heartbeat one byte message and skip this byte when decode.
### Why are the changes needed?
Heartbeat message may split in to two netty buffer, then the `empty buffer` (which don't need actually, but need keep) be wrong removed, then decodeNext would throw NPE. see
``` java
while (headerBuf.readableBytes() < HEADER_SIZE) {
ByteBuf next = buffers.getFirst();
int toRead = Math.min(next.readableBytes(), HEADER_SIZE - headerBuf.readableBytes());
headerBuf.writeBytes(next, toRead);
if (!next.isReadable()) {
buffers.removeFirst().release();
}
}
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
UT & MANUAL
Closes#1589 from RexXiong/CELEBORN-675.
Authored-by: Shuang <lvshuang.tb@gmail.com>
Signed-off-by: zhongqiang.czq <zhongqiang.czq@alibaba-inc.com>
### What changes were proposed in this pull request?
CommitHandler will check whether the target worker is in WorkerStatusTracker's excluded list. If so, skip calling commit files on it.
### Why are the changes needed?
Avoid unnecessary commit files to excluded worker.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
Closes#1581 from waitinfuture/669.
Lead-authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: Keyong Zhou <zhouky@apache.org>
Signed-off-by: Shuang <lvshuang.tb@gmail.com>
### What changes were proposed in this pull request?
In our prod meet many times of push queue stuck caused by PushState's status was not being removed.
Caused DataPushQueue to keep waiting for taking task.
Although have resolved some bugs, here we'd better add a max wait time for taking tasks since we already have the `PUSH_DATA_TIMEOUT` check method. If the target worker is really stuck, we can retry our task finally.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1552 from AngersZhuuuu/CELEBORN-640.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Pluginconf might be hard to understand why Celeborn needs to config class.
### Why are the changes needed?
Ditto.
### Does this PR introduce _any_ user-facing change?
NO.
### How was this patch tested?
UT.
Closes#1524 from FMX/CELEBORN-610.
Authored-by: Ethan Feng <ethanfeng@apache.org>
Signed-off-by: Ethan Feng <ethanfeng@apache.org>
### What changes were proposed in this pull request?
Add doc about enabling rac-awareness
### Why are the changes needed?
Document new features.
### Does this PR introduce _any_ user-facing change?
Yes, the docs are updated.
### How was this patch tested?
<img width="1085" alt="截屏2023-06-02 下午3 19 10" src="https://github.com/apache/incubator-celeborn/assets/46485123/c8c51a4c-40be-40ea-befd-3c369b9f7600">
Closes#1536 from AngersZhuuuu/CELEBORN-629.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Refine this doc since:
1. It didn't mention our cluster default RPC type is `NETTY`
2. If the user use the ratis shell with `GRPC` but didn't know the ratis cluster is `NETTY`, the error is not clear and hard to debug.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1542 from AngersZhuuuu/CELEBORN-623-FOLLOWUP.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Ratis-shell use GRPC by default. Celeborn support Netty for ratis, if `raft.rpc.type` is not specified, commands may fail.
e.g.
```
org.apache.ratis.thirdparty.io.grpc.StatusRuntimeException: DEADLINE_EXCEEDED: deadline exceeded after 14.947369960s. [closed=[], open=[[buffered_nanos=14962358255, waiting_for_connection]]]
```
So I think we should update the document to mention how to change the RPC type to in `celeborn-ratis`.
### Why are the changes needed?
Improve user experience
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually test
Closes#1530 from onebox-li/ratis-shell-default-rpc.
Lead-authored-by: liyihe <liyihe@bigo.sg>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}