### What changes were proposed in this pull request?
This PR fixes performance degradation when Spark's coalescePartitions takes effect caused
by RPC latency.
### Why are the changes needed?
I encountered a performance degradation when testing tpcds 10T q10:
||Time|
|---|---|
|ESS|14s|
|Celeborn| 24s|
After digging into it I found out that q10 triggers partition coalescence:

As I configured `spark.sql.adaptive.coalescePartitions.initialPartitionNum` to 1000, `CelebornShuffleReader`
will call `shuffleClient.readPartition` sequentially 1000 times, causing the delay.
This PR optimizes by calling `shuffleClient.readPartition` in parallel. After this PR q10 time becomes 14s.
### Does this PR introduce _any_ user-facing change?
No, but introduced a new client side configuration `celeborn.client.streamCreatorPool.threads`
which defaults to 32.
### How was this patch tested?
TPCDS 1T and passes GA.
Closes#1876 from waitinfuture/943.
Lead-authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: Keyong Zhou <waitinfuture@gmail.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
In MapPartiitoin, datas are split into regions.
1. Unlike ReducePartition whose partition split can occur on pushing data
to keep MapPartition data ordering, PartitionSplit only be done on the time of sending PushDataHandShake or RegionStart messages (As shown in the following image). That's to say that the partition split only appear at the beginnig of a region but not inner a region.
> Notice: if the client side think that it's failed to push HandShake or RegionStart messages. but the worker side can still receive normal HandShake/RegionStart message. After client revive succss, it don't push any messages to old partition, so the worker having the old partition will create a empty file. After committing files, the worker will return empty commitids. That's to say that empty file will be filterd after committing files and ReduceTask will not read any empty files.

2. PushData/RegioinFinish don't care the following cases:
- Diskfull
- ExceedPartitionSplitThreshold
- Worker ShuttingDown
so if one of the above three conditions appears, PushData and RegionFinish cant still do as normal. Workers should consider the ShuttingDown case and try best to wait all the regions finished before shutting down.
if PushData or RegionFinish failed like network timeout and so on, then MapTask will failed and start another attempte maptask.

3. how shuffle read supports partition split?
ReduceTask should get split paritions by order and open the stream by partition epoc orderly
### Why are the changes needed?
PartiitonSplit is not supported by MapPartition from now.
There still a risk that a partition file'size is too large to store the file on worker disk.
To avoid this risk, this pr introduces partition split in shuffle read and shuffle write.
### Does this PR introduce _any_ user-facing change?
NO.
### How was this patch tested?
UT and manual TPCDS test
Closes#1550 from FMX/CELEBORN-627.
Lead-authored-by: zhongqiang.czq <zhongqiang.czq@alibaba-inc.com>
Co-authored-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
Co-authored-by: Ethan Feng <ethanfeng@apache.org>
Signed-off-by: zhongqiang.czq <zhongqiang.czq@alibaba-inc.com>
### What changes were proposed in this pull request?
For spark clusters, support read local shuffle file if Celeborn is co-deployed with yarn node managers. This PR help to reduce the number of active connections.
### Why are the changes needed?
Ditto.
### Does this PR introduce _any_ user-facing change?
NO.
### How was this patch tested?
GA and cluster. The performance is identical whether you enable local reader, but the active connection number may vary according to your connections per peer.
<img width="951" alt="截屏2023-08-16 20 20 14" src="https://github.com/apache/incubator-celeborn/assets/4150993/9106e731-28fc-4e78-9c05-ae6a269d249a">
The active connection number changed from 3745 to 2894. This PR will help to improve cluster stability.
Closes#1812 from FMX/CELEBORN-752.
Authored-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Adding a flag indicating high load in the worker's heartbeat allows the master to better schedule the workers
### Why are the changes needed?
In our production environment, there is a node with abnormally high load, but the master is not aware of this situation. It assigned numerous jobs to this node, and as a result, the stability of these jobs has been affected.
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
UT
Closes#1840 from JQ-Cao/920.
Lead-authored-by: Keyong Zhou <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: caojiaqing <caojiaqing@bilibili.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title
### Why are the changes needed?
Make `celeborn.shuffle.chunk.size` worker side only config.
Add a new client side config `celeborn.client.fetch.dfsReadChunkSize` for DfsPartitionReader
### Does this PR introduce _any_ user-facing change?
Yes, the chunks size of DfsPartitionReader is changed from client side config `celeborn.shuffle.chunk.size`
to `celeborn.client.fetch.dfsReadChunkSize`
### How was this patch tested?
Passes GA
Closes#1834 from lishiyucn/main.
Lead-authored-by: lishiyucn <675590586@qq.com>
Co-authored-by: shiyu li <675590586@qq.com>
Co-authored-by: Keyong Zhou <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Add a new `backpressure.svg` to replace the out-date one.
### Why are the changes needed?
After #1811, we refactor celeborn worker back-pressure logic, we should add new flowchart for user to understand.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?

Closes#1829 from zwangsheng/CELEBORN-905.
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Fix typo in CelebornConf
### Why are the changes needed?
Fix typo in CelebornConf
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Passing GA
Closes#1813 from jiaoqingbo/typo-conf.
Authored-by: e <1178404354@qq.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title
### Why are the changes needed?
As title
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manual test
Closes#1795 from cfmcgrady/sbt-docs.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
<!--
Thanks for sending a pull request! Here are some tips for you:
- Make sure the PR title start w/ a JIRA ticket, e.g. '[CELEBORN-XXXX] Your PR title ...'.
- Be sure to keep the PR description updated to reflect all changes.
- Please write your PR title to summarize what this PR proposes.
- If possible, provide a concise example to reproduce the issue for a faster review.
-->
### What changes were proposed in this pull request?
1. Expose the config check logic during `MemoryManager#initialization` in the user configuration doc.
2. Add Preconditions Error Message
3. Add unit test to make sure that part of the logic isn't altered by mistake
### Why are the changes needed?
User-friendly
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Add Unit Test
Closes#1801 from zwangsheng/CELEBORN-883.
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: zwangsheng <2213335496@qq.com>
### What changes were proposed in this pull request?
Add config to limit max workers when offering slots, the config can be set both
in server side and client side. Celeborn will choose the smaller positive configs from client and master.
### Why are the changes needed?
For large Celeborn clusters, users may want to limit the number of workers that
a shuffle can spread, reasons are:
1. One worker failure will not affect all applications
2. One huge shuffle will not affect all applications
3. It's more efficient to limit a shuffle within a restricted number of workers, say 100, than
spreading across a large number of workers, say 1000, because the network connections
in pushing data is `number of ShuffleClient` * `number of allocated Workers`
The recommended number of Workers should depend on workload and Worker hardware,
and this can be configured per application, so it's relatively flexible.
### Does this PR introduce _any_ user-facing change?
No, added a new configuration.
### How was this patch tested?
Added ITs and passes GA.
Closes#1790 from waitinfuture/152.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Support worker recovery if the worker has crashed when workers has enabled graceful shutdown..
1. Persist committed file info to LevelDB.
2. Load levelDB when worker started.
3. Clean expired file infos in LevelDB.
### Why are the changes needed?
Ditto.
### Does this PR introduce _any_ user-facing change?
NO.
### How was this patch tested?
GA and cluster. After testing on a cluster I found that 8k file infos will consume about 2MB of disk space, disk space can be reclaimed if shuffle is expired shortly.
Closes#1779 from FMX/CELEBORN-863.
Authored-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1759 from AngersZhuuuu/CELEBORN-832.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Eliminate `chunksBeingTransferred` calculation when `celeborn.shuffle.io.maxChunksBeingTransferred` is not configured
### Why are the changes needed?
I observed high CPU usage on `ChunkStreamManager#chunksBeingTransferred` calculation. We can eliminate the method call if no threshold is configured, and investigate how to improve the method itself in the future.
<img width="1947" alt="image" src="https://github.com/apache/incubator-celeborn/assets/26535726/412c6a41-c0ce-440c-ae99-4424cb8702d3">
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
CI and Review.
Closes#1749 from pan3793/CELEBORN-827.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Cleans up the pooled send buffers and push tasks if the SendBufferPool has been idle for more than
`celeborn.client.push.sendbufferpool.expireTimeout`.
### Why are the changes needed?
Before this PR the SendBufferPool will cache the send buffers and push tasks forever. If they are large
and will not be reused in the future, it wastes memory and causes GC.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Passes GA and manual tests.
Closes#1735 from waitinfuture/812-1.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Fix some typos and grammar
### Why are the changes needed?
Ditto
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
manually test
Closes#1733 from onebox-li/fix-typo.
Authored-by: onebox-li <lyh-36@163.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title.
### Why are the changes needed?
Timeout of ```RpcEndpointRef.ask``` is controlled by ```celeborn.rpc.askTimeout```,
so we also need to increase ```celeborn.rpc.askTimeout``` to extend the timeout of commit files.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Passes GA and manual test.
Closes#1725 from waitinfuture/803-fu.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title.
### Why are the changes needed?
In 0.2.1-incubating, commit files default timeout is ```NETWORK_TIMEOUT```, which is 240s.
It's more reasonable because commit files costs relatively long time. In my testing with tough disks,
30s timeout with 2 retires is not enough.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Passes GA and manual test.
Closes#1724 from waitinfuture/803.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
…up client
### What changes were proposed in this pull request?
Add heartbeat from client to lifecycle manager. In this PR heartbeat request contains local shuffle ids from
client, lifecycle manager checks with it's local set and returns ids it doesn't know. Upon receiving response,
client calls ```unregisterShuffle``` for cleanup.
### Why are the changes needed?
Before this PR, client side ```unregisterShuffle``` is never called. When running TPCDS 3T with spark thriftserver
without DRA, I found the Executor's heap contains 1.6 million PartitionLocation objects (and StorageInfo):

After this PR, the number of PartitionLocation objects decreases to 275 thousands

This heartbeat can be extended in the future for other purposes, i.e. reporting client's metrics.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Passes GA and manual test.
Closes#1719 from waitinfuture/798.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
…Flight.total```
### What changes were proposed in this pull request?
Refer to https://github.com/apache/incubator-celeborn/pull/1720#discussion_r1265092164
### Why are the changes needed?
ditto
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Passes GA.
Closes#1723 from waitinfuture/799-fu.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title.
### Why are the changes needed?
In case where worker instances is very large, say 1000, then before this PR total memory consumed
by inflight requests is 64K * 1000 * ```celeborn.client.push.maxReqsInFlight(16)``` = 1G. This PR
limits total inflight push requests, as 0.2.1-incubating does.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Passes GA and manual test.
Closes#1720 from waitinfuture/799.
Lead-authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
1. Decrease writeTime metric sampling frequency to improve perf
2. Set default value of ```celeborn.<module>.push.timeoutCheck.threads``` and ```celeborn.<module>.fetch.timeoutCheck.threads``` to 4
### Why are the changes needed?
Following are test cases
case 1: ```spark.sparkContext.parallelize(1 to 8000, 8000).flatMap( _ => (1 to 15000000).iterator.map(num => num)).repartition(8000).count``` // shuffle 1.1T data
case 2: ```spark.sparkContext.parallelize(1 to 8000, 8000).flatMap( _ => (1 to 30000000).iterator.map(num => num)).repartition(8000).count``` // shuffle 2.2T data
Following are e2e time of shuffle write stage
||Sort pusher before|Sort pusher after|Hash pusher before|Hash pusher after|
|----|----|----|----|-----|
|case1|4.4min|4.1min|4.4min|3.9min|
|case2|9.1min|8.4min|9.7min|8.5min|
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Passes GA and manual test.
Closes#1718 from waitinfuture/797.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Add a configuration `celeborn.worker.shuffle.partitionSplit.max` to ensure that, in soft mode, individual partition files are limited to a size smaller than the configured value
### Why are the changes needed?
In soft mode, there may be situations where individual partition files are exceptionally large, which can result in excessively long sort times in skewed scenarios.
### Does this PR introduce _any_ user-facing change?
`celeborn.worker.shuffle.partitionSplit.max` defalut value 2g
### How was this patch tested?
none
Closes#1701 from JQ-Cao/785.
Authored-by: caojiaqing <caojiaqing@bilibili.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
This PR changes default values of the following configs:
|config|previous default value|new default value|
|----|----|----|
|celeborn.worker.flusher.threads|2|16|
|celeborn.worker.flusher.ssd.threads|8|16|
### Why are the changes needed?
If disk type is not specified, ```celeborn.worker.flusher.threads``` will be used. Recently many users
use SSD for Celeborn workers without specifying disk type, and 2 flush threads is far from leveraging the power of SSD.
### Does this PR introduce _any_ user-facing change?
Yes, default configs are changed.
### How was this patch tested?
Passes GA.
Closes#1703 from waitinfuture/786.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Now slots is not a bottleneck, change SPARK_SHUFFLE_FORCE_FALLBACK_PARTITION_THRESHOLD default value to Int.MaxValue.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1695 from AngersZhuuuu/CELEBORN-780.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Pullout hardcoded `celeborn.rpc.dispatcher.numThreads` to `CelebornConf` and rename it to `celeborn.rpc.dispatcher.threads` to align with existing configuration style
### Why are the changes needed?
Pullout inline configuration to `CelebornConf`, and expose it in configuration docs
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes#1684 from pan3793/CELEBORN-774.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
…Flight to 16
### What changes were proposed in this pull request?
Change default value of celeborn.client.push.maxReqsInFlight to 16.
### Why are the changes needed?
Previous value 4 is too small, 16 is more reasonable.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Pass GA.
Closes#1683 from waitinfuture/769.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Make Celeborn leader clean expired app dirs on HDFS when an application is Lost.
### Why are the changes needed?
If Celeborn is working on HDFS, the storage manager starts and cleans expired app directories, and the newly created worker will want to delete any unknown app directories.
This will cause using app directories to be deleted unexpectedly.
### Does this PR introduce _any_ user-facing change?
NO.
### How was this patch tested?
UT and cluster.
Closes#1678 from FMX/CELEBORN-764.
Lead-authored-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Co-authored-by: Ethan Feng <fengmingxiao.fmx@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
…memory allocator
### What changes were proposed in this pull request?
Changes the following configs' default values
| config | previous value | current value |
| ------------- | ------------- | ------------- |
| celeborn.network.memory.allocator.share | false | true |
| celeborn.client.shuffle.batchHandleChangePartition.enabled | false | true |
| celeborn.client.shuffle.batchHandleCommitPartition.enabled | false | true |
### Why are the changes needed?
In my test, when graceful shutdown is enabled but ```celeborn.client.shuffle.batchHandleChangePartition.enabled``` and ```celeborn.client.shuffle.batchHandleCommitPartition.enabled``` disabled, the worker takes much longer to stop than the two configs enabled.
In another test where worker size is quite small(2 cores 4 G) and replication is on, if shared allocator is disabled, the netty's onTrim fails to release memory, and further causes push data timeout.
### Does this PR introduce _any_ user-facing change?
No, these conifgs are introduces from 0.3.0.
### How was this patch tested?
Passes GA.
Closes#1682 from waitinfuture/768.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title
### Why are the changes needed?
To clarify the usage of conf `celeborn.client.spark.push.sort.memory.threshold`
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Pass GA
Closes#1680 from cfmcgrady/docs.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Rename remain rss related class name and filenames etc...
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1664 from AngersZhuuuu/CELEBORN-751.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Support to decide whether to compress shuffle data through configuration.
### Why are the changes needed?
Currently, Celeborn compresses all shuffle data, but for example, the shuffle data of Gluten has already been compressed. In this case, no additional compression is required. Therefore, configuration needs to be provided for users to decide whether to use Celeborn’s compression according to the actual situation.
### Does this PR introduce _any_ user-facing change?
no.
Closes#1669 from kerwin-zk/celeborn-755.
Authored-by: xiyu.zk <xiyu.zk@alibaba-inc.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
As title
### Why are the changes needed?
In order to distinguish it from the existing master/worker, refactor data replication terminology to 'primary/replica' for improved clarity and inclusivity in the codebase
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing tests
Closes#1639 from cfmcgrady/primary-replica.
Lead-authored-by: Fu Chen <cfmcgrady@gmail.com>
Co-authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
This pull PR is an integral component of #1639 . It primarily focuses on updating configuration settings and metrics terminology, while ensuring compatibility with older client versions by refraining from introducing changes related to RPC.
### Why are the changes needed?
In order to distinguish it from the existing master/worker, refactor data replication terminology to 'primary/replica' for improved clarity and inclusivity in the codebase
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing tests.
Closes#1650 from cfmcgrady/primary-replica-metrics.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Refine the congestion relevant code/log/comments
### Why are the changes needed?
ditto
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
manually test
Closes#1637 from onebox-li/improve-congestion.
Authored-by: onebox-li <lyh-36@163.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Unify exclude and blacklist related configuration
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1633 from AngersZhuuuu/CELEBORN-666-NEW.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
This PR batches revive requests and periodically send to LifecycleManager to reduce number or RPC requests.
To be more detailed. This PR changes Revive message to support multiple unique partitions, and also passes a set unique mapIds for checking MapEnd. Each time ShuffleClientImpl wants to revive, it adds a ReviveRquest to ReviveManager and wait for result. ReviveManager batches revive requests and periodically send to LifecycleManager (deduplicated by partitionId). LifecycleManager constructs ChangeLocationsCallContext and after all locations are notified, it replies to ShuffleClientImpl.
### Why are the changes needed?
In my test 3T TPCDS q23a with 3 Celeborn workers, when kill a worker, the LifecycleManger will receive 4.8w Revive requests:
```
[emr-usermaster-1-1 logs]$ cat spark-emr-user-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-master-1-1.c-fa08904e94c028d1.out.1 |grep -i revive |wc -l
64364
```
After this PR, number of ReviveBatch requests reduces to 708:
```
[emr-usermaster-1-1 logs]$ cat spark-emr-user-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-master-1-1.c-fa08904e94c028d1.out |grep -i revive |wc -l
2573
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test. I have tested:
1. Disable graceful shutdown, kill one worker, job succeeds
2. Disable graceful shutdown, kill two workers successively, job fails as expected
3. Enable graceful shutdown, restart two workers successively, job succeeds
4. Enable graceful shutdown, restart two workers successively, then kill the third one, job succeeds
Closes#1588 from waitinfuture/656-2.
Lead-authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: Keyong Zhou <zhouky@apache.org>
Co-authored-by: Keyong Zhou <waitinfuture@gmail.com>
Signed-off-by: Shuang <lvshuang.tb@gmail.com>
### What changes were proposed in this pull request?
1. Celeborn supports storage type selection. HDD, SSD, and HDFS are available for now.
2. Add new buffer size for HDFS file writers.
3. Worker support empty working dirs.
### Why are the changes needed?
Support HDFS only scenario.
### Does this PR introduce _any_ user-facing change?
NO.
### How was this patch tested?
UT and cluster.
Closes#1619 from FMX/CELEBORN-568.
Lead-authored-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
Co-authored-by: Ethan Feng <fengmingxiao.fmx@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
This PR aims to make network local address binding support both IP and FQDN strategy.
Additional, it refactors the `ShuffleClientImpl#genAddressPair`, from `${hostAndPort}-${hostAndPort}` to `Pair<String, String>`, which works properly when using IP but may not on FQDN because FQDN may contain `-`
### Why are the changes needed?
Currently, when the bind hostname is not set explicitly, Celeborn will find the first non-loopback address and always uses the IP to bind, this is not suitable for K8s cases, as the STS has a stable FQDN but Pod IP will be changed once Pod restarting.
For `ShuffleClientImpl#genAddressPair`, it must be changed otherwise may cause
```
java.lang.RuntimeException: org.apache.spark.SparkException: Job aborted due to stage failure: Task 11657 in stage 0.0 failed 4 times, most recent failure: Lost task 11657.3 in stage 0.0 (TID 12747) (10.153.253.198 executor 157): java.lang.ArrayIndexOutOfBoundsException: 1
at org.apache.celeborn.client.ShuffleClientImpl.doPushMergedData(ShuffleClientImpl.java:874)
at org.apache.celeborn.client.ShuffleClientImpl.pushOrMergeData(ShuffleClientImpl.java:735)
at org.apache.celeborn.client.ShuffleClientImpl.mergeData(ShuffleClientImpl.java:827)
at org.apache.spark.shuffle.celeborn.SortBasedPusher.pushData(SortBasedPusher.java:140)
at org.apache.spark.shuffle.celeborn.SortBasedPusher.insertRecord(SortBasedPusher.java:192)
at org.apache.spark.shuffle.celeborn.SortBasedShuffleWriter.fastWrite0(SortBasedShuffleWriter.java:192)
at org.apache.spark.shuffle.celeborn.SortBasedShuffleWriter.write(SortBasedShuffleWriter.java:145)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1508)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
```
### Does this PR introduce _any_ user-facing change?
Yes, a new configuration `celeborn.network.bind.preferIpAddress` is introduced, and the default value is `true` to preserve the existing behavior.
### How was this patch tested?
Manually testing with `celeborn.network.bind.preferIpAddress=false`
```
Server: 10.178.96.64
Address: 10.178.96.64#53
Name: celeborn-master-0.celeborn-master-svc.spark.svc.cluster.local
Address: 10.153.143.252
Server: 10.178.96.64
Address: 10.178.96.64#53
Name: celeborn-master-1.celeborn-master-svc.spark.svc.cluster.local
Address: 10.153.173.94
Server: 10.178.96.64
Address: 10.178.96.64#53
Name: celeborn-master-2.celeborn-master-svc.spark.svc.cluster.local
Address: 10.153.149.42
starting org.apache.celeborn.service.deploy.worker.Worker, logging to /opt/celeborn/logs/celeborn--org.apache.celeborn.service.deploy.worker.Worker-1-celeborn-worker-4.out
2023-06-25 23:49:52 [INFO] [main] org.apache.celeborn.common.rpc.netty.Dispatcher#51 - Dispatcher numThreads: 4
2023-06-25 23:49:52 [INFO] [main] org.apache.celeborn.common.network.client.TransportClientFactory#91 - mode NIO threads 64
2023-06-25 23:49:52 [INFO] [main] org.apache.celeborn.common.rpc.netty.NettyRpcEnvFactory#51 - Starting RPC Server [WorkerSys] on celeborn-worker-4.celeborn-worker-svc.spark.svc.cluster.local:0 with advisor endpoint celeborn-worker-4.celeborn-worker-svc.spark.svc.cluster.local:0
2023-06-25 23:49:52 [INFO] [main] org.apache.celeborn.common.util.Utils#51 - Successfully started service 'WorkerSys' on port 38303.
```
Closes#1622 from pan3793/CELEBORN-713.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
30s for fetch timeout is too short and easy to exceed. This PR increases the default value to 600s.
### Why are the changes needed?
When I was testing 3T TPCDS with three workers, I encountered fetch timeout:
```
23/06/21 16:46:41,771 INFO [fetch-server-11-7] FetchHandler: Sending chunk 28856864163, 1, 0, 2147483647
...
23/06/21 16:47:16,870 INFO [fetch-server-11-7] FetchHandler: Sent chunk 28856864163, 1, 0, 2147483647
```
And I remember from some users' monitoring, the max fetch time can reach several minutes on heavy load without error.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
Closes#1618 from waitinfuture/709.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
It was discussed during the last meeting, but abandoned due to the complication.
### Why are the changes needed?
Make the configuration unified.
### Does this PR introduce _any_ user-facing change?
Yes, but the legacy configurations still take effect.
### How was this patch tested?
New UTs.
Closes#1549 from pan3793/CELEBORN-638.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Refresh celeborn configurations in doc
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1592 from AngersZhuuuu/CELEBORN-680.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Celeborn fetch chunk also should support check timeout
#### Test case
```
executor instance 20
SQL:
SELECT count(1) from (select /*+ REPARTITION(100) */ * from spark_auxiliary.t50g) tmp;
--conf spark.celeborn.client.spark.shuffle.writer=sort \
--conf spark.celeborn.client.fetch.excludeWorkerOnFailure.enabled=true \
--conf spark.celeborn.client.push.timeout=10s \
--conf spark.celeborn.client.push.replicate.enabled=true \
--conf spark.celeborn.client.push.revive.maxRetries=10 \
--conf spark.celeborn.client.reserveSlots.maxRetries=10 \
--conf spark.celeborn.client.registerShuffle.maxRetries=3 \
--conf spark.celeborn.client.push.blacklist.enabled=true \
--conf spark.celeborn.client.blacklistSlave.enabled=true \
--conf spark.celeborn.client.fetch.timeout=30s \
--conf spark.celeborn.client.push.data.timeout=30s \
--conf spark.celeborn.client.push.limit.inFlight.timeout=600s \
--conf spark.celeborn.client.push.maxReqsInFlight=32 \
--conf spark.celeborn.client.shuffle.compression.codec=ZSTD \
--conf spark.celeborn.rpc.askTimeout=30s \
--conf spark.celeborn.client.rpc.reserveSlots.askTimeout=30s \
--conf spark.celeborn.client.shuffle.batchHandleChangePartition.enabled=true \
--conf spark.celeborn.client.shuffle.batchHandleCommitPartition.enabled=true \
--conf spark.celeborn.client.shuffle.batchHandleReleasePartition.enabled=true
```
Test with 3 worker and add a `Thread.sleep(100s)` before worker handle `ChunkFetchRequest`
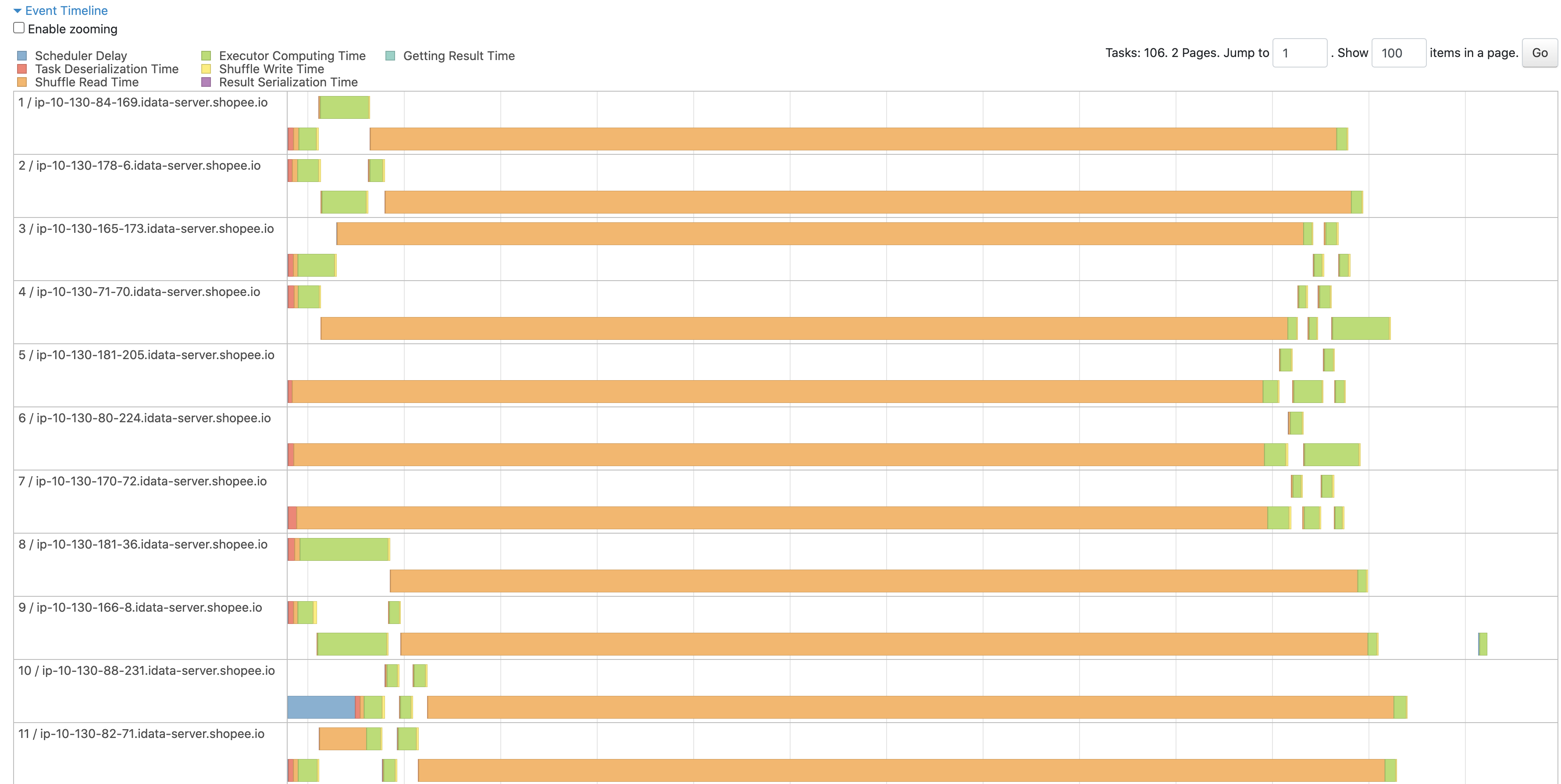
Before patch
<img width="1783" alt="截屏2023-06-14 上午11 20 55" src="https://github.com/apache/incubator-celeborn/assets/46485123/182dff7d-a057-4077-8368-d1552104d206">
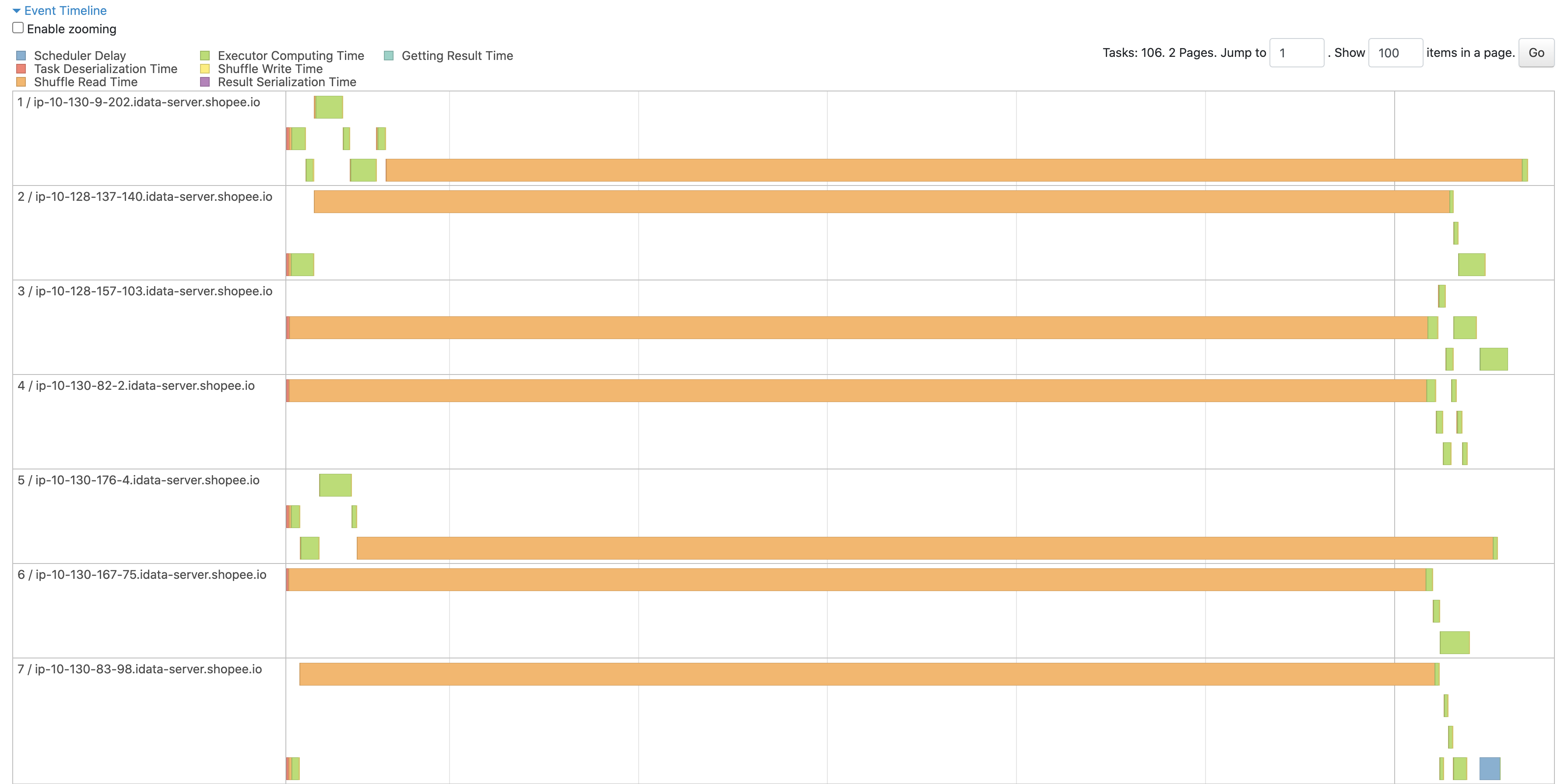
After patch
<img width="1792" alt="image" src="https://github.com/apache/incubator-celeborn/assets/46485123/3c8b7933-8ace-426d-8e9f-04e0aabfac8e">
The log shows the fetch timeout checker workers
```
23/06/14 11:14:54 ERROR WorkerPartitionReader: Fetch chunk 0 failed.
org.apache.celeborn.common.exception.CelebornIOException: FETCH_DATA_TIMEOUT
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:147)
at org.apache.celeborn.common.network.client.TransportResponseHandler.lambda$new$1(TransportResponseHandler.java:103)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
23/06/14 11:14:54 WARN RssInputStream: Fetch chunk failed 1/6 times for location PartitionLocation[
id-epoch:35-0
host-rpcPort-pushPort-fetchPort-replicatePort:10.169.48.203-9092-9094-9093-9095
mode:MASTER
peer:(host-rpcPort-pushPort-fetchPort-replicatePort:10.169.48.202-9092-9094-9093-9095)
storage hint:StorageInfo{type=HDD, mountPoint='/mnt/ssd/0', finalResult=true, filePath=}
mapIdBitMap:null], change to peer
org.apache.celeborn.common.exception.CelebornIOException: Fetch chunk 0 failed.
at org.apache.celeborn.client.read.WorkerPartitionReader$1.onFailure(WorkerPartitionReader.java:98)
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:146)
at org.apache.celeborn.common.network.client.TransportResponseHandler.lambda$new$1(TransportResponseHandler.java:103)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.celeborn.common.exception.CelebornIOException: FETCH_DATA_TIMEOUT
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:147)
... 8 more
23/06/14 11:14:54 INFO SortBasedShuffleWriter: Memory used 72.0 MB
```
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1587 from AngersZhuuuu/CELEBORN-676.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Add celeborn.metrics.conf to conf entity
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1593 from AngersZhuuuu/CELEBORN-681.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
refer to https://github.com/apache/spark/pull/40301
1. Optimize `Utils.bytesToString`. Arithmetic ops on BigInt and BigDecimal are order(s) of magnitude slower than the ops on primitive types. Division is an especially slow operation and it is used en masse here.
2. According to the information sourced from [Wikipedia](https://en.wikipedia.org/wiki/Kilobyte), it is established that 1000 is the appropriate factor for representing kilobytes (KB), while 1024 is the correct factor for kibibytes (KiB). In alignment with this understanding, changing the size unit from "KB" to "KiB".
### Why are the changes needed?
the Utils#bytesToString method is frequently employed in memory-related log messages.
### Does this PR introduce _any_ user-facing change?
No, only perf improvement.
### How was this patch tested?
existing UT and manually tested.
Closes#1590 from cfmcgrady/bytesToString.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Give Heartbeat one byte message and skip this byte when decode.
### Why are the changes needed?
Heartbeat message may split in to two netty buffer, then the `empty buffer` (which don't need actually, but need keep) be wrong removed, then decodeNext would throw NPE. see
``` java
while (headerBuf.readableBytes() < HEADER_SIZE) {
ByteBuf next = buffers.getFirst();
int toRead = Math.min(next.readableBytes(), HEADER_SIZE - headerBuf.readableBytes());
headerBuf.writeBytes(next, toRead);
if (!next.isReadable()) {
buffers.removeFirst().release();
}
}
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
UT & MANUAL
Closes#1589 from RexXiong/CELEBORN-675.
Authored-by: Shuang <lvshuang.tb@gmail.com>
Signed-off-by: zhongqiang.czq <zhongqiang.czq@alibaba-inc.com>
### What changes were proposed in this pull request?
CommitHandler will check whether the target worker is in WorkerStatusTracker's excluded list. If so, skip calling commit files on it.
### Why are the changes needed?
Avoid unnecessary commit files to excluded worker.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
Closes#1581 from waitinfuture/669.
Lead-authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: Keyong Zhou <zhouky@apache.org>
Signed-off-by: Shuang <lvshuang.tb@gmail.com>
### What changes were proposed in this pull request?
In our prod meet many times of push queue stuck caused by PushState's status was not being removed.
Caused DataPushQueue to keep waiting for taking task.
Although have resolved some bugs, here we'd better add a max wait time for taking tasks since we already have the `PUSH_DATA_TIMEOUT` check method. If the target worker is really stuck, we can retry our task finally.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1552 from AngersZhuuuu/CELEBORN-640.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Pluginconf might be hard to understand why Celeborn needs to config class.
### Why are the changes needed?
Ditto.
### Does this PR introduce _any_ user-facing change?
NO.
### How was this patch tested?
UT.
Closes#1524 from FMX/CELEBORN-610.
Authored-by: Ethan Feng <ethanfeng@apache.org>
Signed-off-by: Ethan Feng <ethanfeng@apache.org>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}