### What changes were proposed in this pull request?
Change Celeborn Master URL from `rss://<host>:<port>` to `celeborn://<host>:<port>`
### Why are the changes needed?
Respect the project name.
### Does this PR introduce _any_ user-facing change?
Yes, migration guide is updated accordingly.
### How was this patch tested?
Pass GA.
Closes#1624 from pan3793/CELEBORN-715.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
As title
### Why are the changes needed?
before this PR the `liborg_apache_celeborn_shaded_netty_transport_native_epoll_aarch_64.so` can't correctly be loaded.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manually tested
```shell
> tar zxf celeborn-client-spark-3-shaded_2.12-0.4.0-SNAPSHOT.jar
> find * -name "*.so"
META-INF/native/liborg_apache_celeborn_shaded_netty_transport_native_epoll_aarch_64.so
META-INF/native/liborg_apache_celeborn_shaded_netty_transport_native_epoll_x86_64.so
```
Closes#1625 from cfmcgrady/typo.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
1. separated push data timeout tests and push merge data timeout tests in `PushDataTimeoutTest`
2. updated the test results assertion
3. rework `pushdata timeout will add to blacklist`
### Why are the changes needed?
ensure that the timeout behavior is correctly implemented
https://github.com/apache/incubator-celeborn/pull/1613#discussion_r1236423721
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
existing tests
Closes#1620 from cfmcgrady/push-timeout-test.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Add `diskType` in `charts/celeborn/values.yml` to help configuration `celeborn.worker.storage.dirs`
Result like:
```properties
celeborn.worker.storage.dirs=/mnt/disk1:disktype=HDD,/mnt/disk2:disktype=HDD,/mnt/disk3:disktype=HDD,/mnt/disk4:disktype=SSD
```
### Why are the changes needed?
Help user specify local disk type.
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
Local dry-run
```shell
helm install celeborn charts/celeborn --dry-run
```
Closes#1623 from zwangsheng/CELEBORN-714.
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
### What changes were proposed in this pull request?
Make appUniqueId a member of ShuffleClientImpl and remove applicationId from RPC messages across client side, so it won't cause compatibility issues.
### Why are the changes needed?
Currently Celeborn Client is bound to a single application id, so there's no need to pass applicationId around in many RPC messages in client side.
### Does this PR introduce _any_ user-facing change?
In some logs the application id will not be printed, which should not be a problem.
### How was this patch tested?
UTs.
Closes#1621 from waitinfuture/appid.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Remove environment variables `CELEBORN_MASTER_HOST` and `CELEBORN_MASTER_PORT`, and makes `CELEBORN_LOCAL_HOSTNAME` takes effect on both master and worker.
### Why are the changes needed?
There are many different ways to configure the master/worker host and port, which makes the thing complex and inconsistent.
After this change,
#### master
1. cli args `--host` `--port` takes the highest priority
2. then lookup env `CELEBORN_LOCAL_HOSTNAME`
3. things are different when HA enabled and disabled
3.1. when HA is disabled, lookup configurations `celeborn.master.host` and `celeborn.master.port`
3.2. when HA is enabled, each node needs to know the whole cluster info,
```
celeborn.master.ha.node.1.host clb-1
celeborn.master.ha.node.1.port 9097
celeborn.master.ha.node.2.host clb-2
celeborn.master.ha.node.2.port 9097
celeborn.master.ha.node.3.host clb-3
celeborn.master.ha.node.3.port 9097
```
in addition, `celeborn.master.ha.node.id=1` can be used to indicate the node id, otherwise, the master will try to bind each host to match the node id.
#### worker
1. cli args `--host` `--port` takes the highest priority
2. then lookup env `CELEBORN_LOCAL_HOSTNAME`
things are simple than the master case because each worker is not required to know others.
### Does this PR introduce _any_ user-facing change?
Yes.
### How was this patch tested?
UT.
Closes#1616 from pan3793/CELEBORN-707.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
30s for fetch timeout is too short and easy to exceed. This PR increases the default value to 600s.
### Why are the changes needed?
When I was testing 3T TPCDS with three workers, I encountered fetch timeout:
```
23/06/21 16:46:41,771 INFO [fetch-server-11-7] FetchHandler: Sending chunk 28856864163, 1, 0, 2147483647
...
23/06/21 16:47:16,870 INFO [fetch-server-11-7] FetchHandler: Sent chunk 28856864163, 1, 0, 2147483647
```
And I remember from some users' monitoring, the max fetch time can reach several minutes on heavy load without error.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
Closes#1618 from waitinfuture/709.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
- Fix commit metrics in application heartbeat
- Change client side application heartbeat message log level to info
- Improve heartbeat log by unify the word "heartbeat"
### Why are the changes needed?
`commitHandler.commitMetrics()` has side effects, multiple calls to get values independently is incorrect.
```
def commitMetrics(): (Long, Long) = (totalWritten.sumThenReset(), fileCount.sumThenReset())
```
### Does this PR introduce _any_ user-facing change?
Yes, bug fix.
### How was this patch tested?
Review.
Closes#1617 from pan3793/CELEBORN-708.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Upgrade Maven from 3.6.3 to 3.8.8.
### Why are the changes needed?
Maven 3.6.3 is EOL. It was removed from the Apache Mirror site, so users can not benefit from download speedup from the mirror even with
```
export APACHE_MIRROR=https://mirrors.cloud.tencent.com/apache
```
https://mirrors.cloud.tencent.com/apache/maven/maven-3/
<img width="752" alt="image" src="https://github.com/apache/incubator-celeborn/assets/26535726/80e9e472-15c6-419e-a29b-69661615a16f">
There are logs from our CI server, it can not download from the mirror site and have to fallback to the Apache archive server, the latter is extremely slow.
```
$ ./build/mvn $MVN_OPTS $BUILD_PROFILES -version
Falling back to archive.apache.org to download Maven
...
```
Why not 3.9.2?
Maven 3.9 uses native transport-http as default and the default timeout is 10000ms, which is shorter than Wagon's default timeout 60000ms, which causes a lot of network timeout issues
See details at https://github.com/apache/spark/pull/40738
### Does this PR introduce _any_ user-facing change?
Maybe, if the user uses insecure http private repo in their `pom.xml`. Because [Maven 3.8 enforces the https in default](https://maven.apache.org/docs/3.8.1/release-notes.html#cve-2021-26291).
As a workaround, you can leverage `sed` to remove such restrictions.
```
$ build/mvn -version
$ sed -i "s/<mirrorOf>external:http:\*/<mirrorOf>dummy/g" build/apache-maven-*/conf/settings.xml
...
```
### How was this patch tested?
Pass GA.
Closes#1615 from pan3793/CELEBORN-705.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Print host and port on starting Netty RPC Server
### Why are the changes needed?
Sometimes, the Master/Worker may fail on bootstrap because `BindException: Cannot assign requested address`, but there is no clue which addresses it tried.
```
2023-06-21 14:28:12 [INFO] [main] org.apache.celeborn.service.deploy.worker.Worker#51 - Metrics system enabled.
2023-06-21 14:28:12 [ERROR] [main] org.apache.celeborn.service.deploy.worker.Worker#80 - Initialize worker failed.
java.net.BindException: Cannot assign requested address
at sun.nio.ch.Net.bind0(Native Method) ~[?:1.8.0_372]
at sun.nio.ch.Net.bind(Net.java:461) ~[?:1.8.0_372]
at sun.nio.ch.Net.bind(Net.java:453) ~[?:1.8.0_372]
at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:222) ~[?:1.8.0_372]
at io.netty.channel.socket.nio.NioServerSocketChannel.doBind(NioServerSocketChannel.java:141) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.AbstractChannel$AbstractUnsafe.bind(AbstractChannel.java:562) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.DefaultChannelPipeline$HeadContext.bind(DefaultChannelPipeline.java:1334) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeBind(AbstractChannelHandlerContext.java:600) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.AbstractChannelHandlerContext.bind(AbstractChannelHandlerContext.java:579) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.handler.logging.LoggingHandler.bind(LoggingHandler.java:230) ~[netty-handler-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.AbstractChannelHandlerContext.invokeBind(AbstractChannelHandlerContext.java:602) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.AbstractChannelHandlerContext.bind(AbstractChannelHandlerContext.java:579) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.DefaultChannelPipeline.bind(DefaultChannelPipeline.java:973) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.AbstractChannel.bind(AbstractChannel.java:260) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.bootstrap.AbstractBootstrap$2.run(AbstractBootstrap.java:356) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.util.concurrent.AbstractEventExecutor.runTask(AbstractEventExecutor.java:174) ~[netty-common-4.1.93.Final.jar:4.1.93.Final]
at io.netty.util.concurrent.AbstractEventExecutor.safeExecute(AbstractEventExecutor.java:167) ~[netty-common-4.1.93.Final.jar:4.1.93.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor.runAllTasks(SingleThreadEventExecutor.java:470) ~[netty-common-4.1.93.Final.jar:4.1.93.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:569) ~[netty-transport-4.1.93.Final.jar:4.1.93.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997) ~[netty-common-4.1.93.Final.jar:4.1.93.Final]
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) ~[netty-common-4.1.93.Final.jar:4.1.93.Final]
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) ~[netty-common-4.1.93.Final.jar:4.1.93.Final]
at java.lang.Thread.run(Thread.java:750) ~[?:1.8.0_372]
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manually review.
Closes#1614 from pan3793/CELEBORN-704.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Extend doc about migration from 0.2.1 to 0.3.0. Added the following contents:
<img width="1084" alt="image" src="https://github.com/apache/incubator-celeborn/assets/26535726/7a9d172c-09ba-48b6-9f5c-73a8b13d035f">
### Why are the changes needed?
ditto
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
No.
Closes#1612 from waitinfuture/702.
Lead-authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: Cheng Pan <pan3793@gmail.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Fixes compatibility issue introduced by change of WorkerInfo.
### Why are the changes needed?
When testing with branch-0.2 client and main server, I got the following error:
```
Caused by: scala.MatchError: [Ljava.lang.String;414ca35a (of class [Ljava.lang.String;)
at org.apache.celeborn.common.util.PbSerDeUtils$.$anonfun$fromPbWorkerResource$1(PbSerDeUtils.scala:298)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at org.apache.celeborn.common.util.PbSerDeUtils$.fromPbWorkerResource(PbSerDeUtils.scala:297)
at org.apache.celeborn.common.protocol.message.ControlMessages$.fromTransportMessage(ControlMessages.scala:863)
at org.apache.celeborn.common.util.Utils$.fromTransportMessage(Utils.scala:828)
at org.apache.celeborn.common.serializer.JavaSerializerInstance.deserialize(JavaSerializer.scala:110)
at org.apache.celeborn.common.rpc.netty.NettyRpcEnv.$anonfun$deserialize$2(NettyRpcEnv.scala:276)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at org.apache.celeborn.common.rpc.netty.NettyRpcEnv.deserialize(NettyRpcEnv.scala:323)
at org.apache.celeborn.common.rpc.netty.NettyRpcEnv.$anonfun$deserialize$1(NettyRpcEnv.scala:275)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at org.apache.celeborn.common.rpc.netty.NettyRpcEnv.deserialize(NettyRpcEnv.scala:275)
at org.apache.celeborn.common.rpc.netty.NettyRpcEnv.$anonfun$ask$6(NettyRpcEnv.scala:235)
at org.apache.celeborn.common.rpc.netty.NettyRpcEnv.$anonfun$ask$6$adapted(NettyRpcEnv.scala:235)
at org.apache.celeborn.common.rpc.netty.RpcOutboxMessage.onSuccess(Outbox.scala:82)
at org.apache.celeborn.common.network.client.TransportResponseHandler.handle(TransportResponseHandler.java:180)
at org.apache.celeborn.common.network.server.TransportChannelHandler.channelRead(TransportChannelHandler.java:119)
at org.apache.celeborn.shaded.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379)
at org.apache.celeborn.shaded.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365)
at org.apache.celeborn.shaded.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357)
at org.apache.celeborn.shaded.io.netty.handler.timeout.IdleStateHandler.channelRead(IdleStateHandler.java:286)
at org.apache.celeborn.shaded.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:379)
at org.apache.celeborn.shaded.io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:365)
at org.apache.celeborn.shaded.io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:357)
at org.apache.celeborn.common.network.util.TransportFrameDecoder.channelRead(TransportFrameDecoder.java:74)
```
And this is introduced by 811e192bbd (diff-b61712c3683306f65cd2ca051b54075952897a899951f3e37ec3968e7ba75710)
### Does this PR introduce _any_ user-facing change?
Yes, it fixes compatibility error when using branch-0.2 client and main server.
### How was this patch tested?
Manual test.
Closes#1610 from waitinfuture/700.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Fixes compatibility issue caused by change of push data timeout.
### Why are the changes needed?
When I test with branch-0.2 client with main server side, I got the following error:
```
23/06/20 17:42:34,538 ERROR [push-timeout-checker-12] PushDataHandler: PushData replication failed for partitionLocation: PartitionLocation[
id-epoch:767-0
host-rpcPort-pushPort-fetchPort-replicatePort:192.168.1.17-37687-42605-42891-41319
mode:MASTER
peer:(host-rpcPort-pushPort-fetchPort-replicatePort:192.168.1.18-45201-35749-41831-46853)
storage hint:StorageInfo{type=MEMORY, mountPoint='/mnt/disk4', finalResult=false, filePath=}
mapIdBitMap:null]
org.apache.celeborn.common.exception.CelebornIOException: PUSH_DATA_TIMEOUT_SLAVE
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredPushRequest(TransportResponseHandler.java:125)
at org.apache.celeborn.common.network.client.TransportResponseHandler.lambda$new$0(TransportResponseHandler.java:96)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
```
The error is because in main branch ReserveSlots added a new field ```pushDataTimeout```, so when client is branch-0.2, the default value will be 0, and always trigger timeout.
### Does this PR introduce _any_ user-facing change?
Yes, this PR fixes a bug when client is branch-0.2 and server is main.
### How was this patch tested?
Manual test.
Closes#1611 from waitinfuture/701.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
### What changes were proposed in this pull request?
1. Foreach PartitionLocation returned from Register Shuffle, remove from worker's local excluded list to refresh the local information.
2. ChangeLocationResponse will also return whether oldPartition is excluded in LifecycleManager. If so, remove it from Executor's excluded list.
3. Always trigger commit files for shutting down workers returned from HeartbeatFromApplicationResponse.
4. HeartbeatFromWorker sends the correct disk infos regardless of shutting down or not.
After this PR, the priority of excluded list is Master > LifecycleManager > Executor.
### Why are the changes needed?
During test with graceful turned on(workers have static rpc/push/fetch/replicate ports) and consistently restart one out of three workers, I encountered several bugs.
1. First I killed worker A, then Executor's client's local excluded list will contain A, after A stopped, I started it again, then master will offer slots on A, so we should remove from the executor's excluded list then.
2. When I kill-and-start a worker twice in a short time smaller than the app heartbeat interval, the second time WorkerStatusTracker will not trigger commit files because the local cache for the worker has not been refreshed.
3. When a worker is shutting down, in its heartbeat it passes empty diskInfos, and master blindly added to excluded list. We want a worker be either in the excluded list, or in the shutting down list, exclusively. If a worker is in excluded list, then LIfecycleManager will not trigger commit files when handle heartbeat response; on the other hand, if a worker is in the shutting down list, LifecycleManager will trigger commit files on it. So we must make it correct that a shutting down worker be in the shutting down list.
### Does this PR introduce _any_ user-facing change?
Yes, it fixes several bugs described above.
### How was this patch tested?
Manual test.
Closes#1606 from waitinfuture/696.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: Shuang <lvshuang.tb@gmail.com>
### What changes were proposed in this pull request?
DeviceInfo `deviceStatAvailable` 's variable name and assignment does not match
### Why are the changes needed?
ditto
### Does this PR introduce _any_ user-facing change?
NO
### How was this patch tested?
Cluster test
Closes#1607 from onebox-li/fix-deviceStatAvailable.
Authored-by: onebox-li <lyh-36@163.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
If dataDir does not exists, it will skip check in DeviceMonitor::readWriteError.
It will cause that a disk found READ_OR_WRITE_FAILURE when creating FileWriter error, may change to be healthy in the subsequent disk checker.
```
23/06/19 19:09:52,718 ERROR [dispatcher-event-loop-16] StorageManager: Create FileWriter for /data7/rss_storage/rss-worker/shuffle_data/application_1684305681931_1943199/180/79-0-0 of mount /data7 failed, report to DeviceMonitor
java.io.IOException: No such file or directory
at java.io.UnixFileSystem.createFileExclusively(Native Method)
at java.io.File.createNewFile(File.java:1012)
at org.apache.celeborn.service.deploy.worker.storage.StorageManager.createWriter(StorageManager.scala:330)
...
at java.lang.Thread.run(Thread.java:745)
23/06/19 19:09:52,718 ERROR [dispatcher-event-loop-16] LocalDeviceMonitor: Receive non-critical exception, disk: /data7, java.io.IOException: java.io.IOException: No such file or directory
updated state
DiskInfo(maxSlots: 0, committed shuffles 0 shuffleAllocations: Map(), mountPoint: /data7, usableSpace: 536870912000, avgFlushTime: 0, avgFetchTime: 0, activeSlots: 0) status: READ_OR_WRITE_FAILURE dirs /data7/rss_storage/rss-worker/shuffle_data
after disk checker, updated stated
DiskInfo(maxSlots: 0, committed shuffles 0 shuffleAllocations: Map(), mountPoint: /data7, usableSpace: 536870912000, avgFlushTime: 0, avgFetchTime: 0, activeSlots: 0) status: HEALTHY dirs /data7/rss_storage/rss-worker/shuffle_data
```
### Why are the changes needed?
ditto
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Cluster test
Closes#1608 from onebox-li/fix-disk-check.
Authored-by: onebox-li <lyh-36@163.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Correct the FsPermission 755.
### Why are the changes needed?
We should use octal 0755 or "755" instead of decimal to represent UNIX permission. String is chosen because octal is deprecated in Scala.
### Does this PR introduce _any_ user-facing change?
Yes, it's a bug fix.
### How was this patch tested?
Manually review.
Closes#1597 from pan3793/CELEBORN-685.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: mingji <fengmingxiao.fmx@alibaba-inc.com>
### What changes were proposed in this pull request?
Refactor WorkerInfo
1. make ```diskInfos```, ```userResourceConsumption``` new maps instead of using the passed in reference
2. remove ```endpoint``` from the constructor
### Why are the changes needed?
When manually test stop-worker.sh with graceful turned on, I got the following Exception
```
23/06/19 11:04:25,665 INFO [worker-forward-message-scheduler] RssHARetryClient: connect to master master-1-1:9097.
23/06/19 11:04:27,168 ERROR [worker-forward-message-scheduler] RssHARetryClient: Send rpc with failure, has tried 15, max try 15!
org.apache.celeborn.common.exception.CelebornException: Exception thrown in awaitResult:
at org.apache.celeborn.common.util.ThreadUtils$.awaitResult(ThreadUtils.scala:231)
at org.apache.celeborn.common.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:74)
at org.apache.celeborn.common.haclient.RssHARetryClient.sendMessageInner(RssHARetryClient.java:150)
at org.apache.celeborn.common.haclient.RssHARetryClient.askSync(RssHARetryClient.java:118)
at org.apache.celeborn.service.deploy.worker.Worker.org$apache$celeborn$service$deploy$worker$Worker$$heartBeatToMaster(Worker.scala:306)
at org.apache.celeborn.service.deploy.worker.Worker$$anon$1.$anonfun$run$1(Worker.scala:332)
at org.apache.celeborn.common.util.Utils$.tryLogNonFatalError(Utils.scala:186)
at org.apache.celeborn.service.deploy.worker.Worker$$anon$1.run(Worker.scala:332)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: org.apache.celeborn.common.exception.CelebornIOException: remove
at org.apache.celeborn.service.deploy.master.clustermeta.ha.HAHelper.sendFailure(HAHelper.java:65)
at org.apache.celeborn.service.deploy.master.Master.executeWithLeaderChecker(Master.scala:210)
at org.apache.celeborn.service.deploy.master.Master$$anonfun$receiveAndReply$1.applyOrElse(Master.scala:315)
at org.apache.celeborn.common.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115)
at org.apache.celeborn.common.rpc.netty.Inbox.safelyCall(Inbox.scala:222)
at org.apache.celeborn.common.rpc.netty.Inbox.process(Inbox.scala:110)
at org.apache.celeborn.common.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:229)
... 3 more
Caused by: java.lang.UnsupportedOperationException: remove
at scala.collection.convert.Wrappers$MapWrapper$$anon$2$$anon$3.remove(Wrappers.scala:236)
at java.util.AbstractMap.remove(AbstractMap.java:254)
at org.apache.celeborn.common.meta.WorkerInfo.$anonfun$updateThenGetDiskInfos$2(WorkerInfo.scala:225)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at org.apache.celeborn.common.meta.WorkerInfo.updateThenGetDiskInfos(WorkerInfo.scala:224)
at org.apache.celeborn.service.deploy.master.clustermeta.AbstractMetaManager.lambda$updateWorkerHeartbeatMeta$5(AbstractMetaManager.java:205)
at java.util.Optional.ifPresent(Optional.java:159)
at org.apache.celeborn.service.deploy.master.clustermeta.AbstractMetaManager.updateWorkerHeartbeatMeta(AbstractMetaManager.java:203)
at org.apache.celeborn.service.deploy.master.clustermeta.SingleMasterMetaManager.handleWorkerHeartbeat(SingleMasterMetaManager.java:105)
at org.apache.celeborn.service.deploy.master.Master.org$apache$celeborn$service$deploy$master$Master$$handleHeartbeatFromWorker(Master.scala:428)
at org.apache.celeborn.service.deploy.master.Master$$anonfun$receiveAndReply$1.$anonfun$applyOrElse$20(Master.scala:326)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.celeborn.service.deploy.master.Master.executeWithLeaderChecker(Master.scala:207)
... 8 more
```
According to the suggestion from https://github.com/apache/incubator-celeborn/pull/1602#issuecomment-1596722991
### Does this PR introduce _any_ user-facing change?
Yes, it fixes bug described in https://github.com/apache/incubator-celeborn/pull/1602
### How was this patch tested?
UTs and manual test.
Closes#1605 from waitinfuture/695.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
This PR put workers with WORKER_SHUTDOWN status into shuttingWorkers instead of blacklist.
### Why are the changes needed?
If WORKER_SHUTDOWN workers are put into blacklist, it will not trigger commit files, see ```CommitHandler::commitFiles```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
Closes#1603 from waitinfuture/692.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
As title.
### Why are the changes needed?
https://github.com/apache/incubator-celeborn/pull/1585#issuecomment-1589164128
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
tested locally.
Closes#1604 from cfmcgrady/hash-based-writer-metrics.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
1. Use `<arg>-Ywarn-unused-import</arg>` to remove some unused imports
There is no way to use `<arg>-Ywarn-unused-import</arg>` at this stage
Because we have the following code
```
// Can Remove this if celeborn don't support scala211 in future
import org.apache.celeborn.common.util.FunctionConverter._
```
2. Fix scala case match not fully covered, avoid `scala.MatchError`
3. Fixed some scala compilation warnings
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1600 from cxzl25/cleanup_code.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1601 from cxzl25/CELEBORN-689.
Authored-by: sychen <sychen@ctrip.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
After `Netty` release `4.1.39.Final` for 3 weeks ago, we should update netty version.
[Change List](https://github.com/netty/netty/compare/netty-4.1.92.Final...netty-4.1.93.Final)
### Why are the changes needed?
Catch up with the Netty version
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
CI
Closes#1596 from zwangsheng/CELEBORN-684.
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1594 from AngersZhuuuu/CELEBORN-682.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
It was discussed during the last meeting, but abandoned due to the complication.
### Why are the changes needed?
Make the configuration unified.
### Does this PR introduce _any_ user-facing change?
Yes, but the legacy configurations still take effect.
### How was this patch tested?
New UTs.
Closes#1549 from pan3793/CELEBORN-638.
Authored-by: Cheng Pan <chengpan@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Support service type `NodePort` in `values.yaml`
### Why are the changes needed?
For Kubernetes IT, should start celeborn cluster in minikube with nodePort for discover
### Does this PR introduce _any_ user-facing change?
Yes
### How was this patch tested?
CI Test & Local Test
Closes#1554 from zwangsheng/CELEBORN-644.
Authored-by: zwangsheng <2213335496@qq.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Now worker will send WorkLost too, master should also reply WorkerLostResponse when it's unknown worker
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1584 from AngersZhuuuu/CELEBORN-668-FOLLOWUP.
Lead-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: Keyong Zhou <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Include ConnectException when exclude worker for fetch
### Why are the changes needed?
Currently RssInputStream.isCriticalCause does not include ConnectException
```
java.io.IOException: Failed to connect to /192.168.1.17:46197
at org.apache.celeborn.common.network.client.TransportClientFactory.internalCreateClient(TransportClientFactory.java:232)
at org.apache.celeborn.common.network.client.TransportClientFactory.createClient(TransportClientFactory.java:176)
at org.apache.celeborn.common.network.client.TransportClientFactory.createClient(TransportClientFactory.java:114)
at org.apache.celeborn.common.network.client.TransportClientFactory.createClient(TransportClientFactory.java:183)
at org.apache.celeborn.client.read.WorkerPartitionReader.<init>(WorkerPartitionReader.java:103)
at org.apache.celeborn.client.read.RssInputStream$RssInputStreamImpl.createReader(RssInputStream.java:399)
at org.apache.celeborn.client.read.RssInputStream$RssInputStreamImpl.createReaderWithRetry(RssInputStream.java:301)
at org.apache.celeborn.client.read.RssInputStream$RssInputStreamImpl.moveToNextReader(RssInputStream.java:229)
at org.apache.celeborn.client.read.RssInputStream$RssInputStreamImpl.<init>(RssInputStream.java:178)
at org.apache.celeborn.client.read.RssInputStream.create(RssInputStream.java:63)
at org.apache.celeborn.client.ShuffleClientImpl.readPartition(ShuffleClientImpl.java:1599)
at org.apache.spark.shuffle.celeborn.RssShuffleReader.$anonfun$read$1(RssShuffleReader.scala:88)
at org.apache.spark.shuffle.celeborn.RssShuffleReader.$anonfun$read$1$adapted(RssShuffleReader.scala:79)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:461)
at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:486)
at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:492)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31)
at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage17.sort_addToSorter_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage17.sort_doSort_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage17.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:35)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage17.hasNext(Unknown Source)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:954)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage18.smj_findNextJoinRows_0$(Unknown Source)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage18.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:35)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage18.hasNext(Unknown Source)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$2.hasNext(WholeStageCodegenExec.scala:973)
at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:460)
at org.apache.spark.shuffle.celeborn.HashBasedShuffleWriter.fastWrite0(HashBasedShuffleWriter.java:251)
at org.apache.spark.shuffle.celeborn.HashBasedShuffleWriter.write(HashBasedShuffleWriter.java:180)
at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52)
at org.apache.spark.scheduler.Task.run(Task.scala:133)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:506)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1474)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:509)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:750)
Caused by: org.apache.celeborn.shaded.io.netty.channel.AbstractChannel$AnnotatedConnectException: Connection refused: /192.168.1.17:46197
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:716)
at org.apache.celeborn.shaded.io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:337)
at org.apache.celeborn.shaded.io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:334)
at org.apache.celeborn.shaded.io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:776)
at org.apache.celeborn.shaded.io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:724)
at org.apache.celeborn.shaded.io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:650)
at org.apache.celeborn.shaded.io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:562)
at org.apache.celeborn.shaded.io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)
at org.apache.celeborn.shaded.io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at org.apache.celeborn.shaded.io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.lang.Thread.run(Thread.java:750)
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test
Closes#1598 from waitinfuture/686.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Refresh celeborn configurations in doc
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1592 from AngersZhuuuu/CELEBORN-680.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
Celeborn fetch chunk also should support check timeout
#### Test case
```
executor instance 20
SQL:
SELECT count(1) from (select /*+ REPARTITION(100) */ * from spark_auxiliary.t50g) tmp;
--conf spark.celeborn.client.spark.shuffle.writer=sort \
--conf spark.celeborn.client.fetch.excludeWorkerOnFailure.enabled=true \
--conf spark.celeborn.client.push.timeout=10s \
--conf spark.celeborn.client.push.replicate.enabled=true \
--conf spark.celeborn.client.push.revive.maxRetries=10 \
--conf spark.celeborn.client.reserveSlots.maxRetries=10 \
--conf spark.celeborn.client.registerShuffle.maxRetries=3 \
--conf spark.celeborn.client.push.blacklist.enabled=true \
--conf spark.celeborn.client.blacklistSlave.enabled=true \
--conf spark.celeborn.client.fetch.timeout=30s \
--conf spark.celeborn.client.push.data.timeout=30s \
--conf spark.celeborn.client.push.limit.inFlight.timeout=600s \
--conf spark.celeborn.client.push.maxReqsInFlight=32 \
--conf spark.celeborn.client.shuffle.compression.codec=ZSTD \
--conf spark.celeborn.rpc.askTimeout=30s \
--conf spark.celeborn.client.rpc.reserveSlots.askTimeout=30s \
--conf spark.celeborn.client.shuffle.batchHandleChangePartition.enabled=true \
--conf spark.celeborn.client.shuffle.batchHandleCommitPartition.enabled=true \
--conf spark.celeborn.client.shuffle.batchHandleReleasePartition.enabled=true
```
Test with 3 worker and add a `Thread.sleep(100s)` before worker handle `ChunkFetchRequest`
Before patch
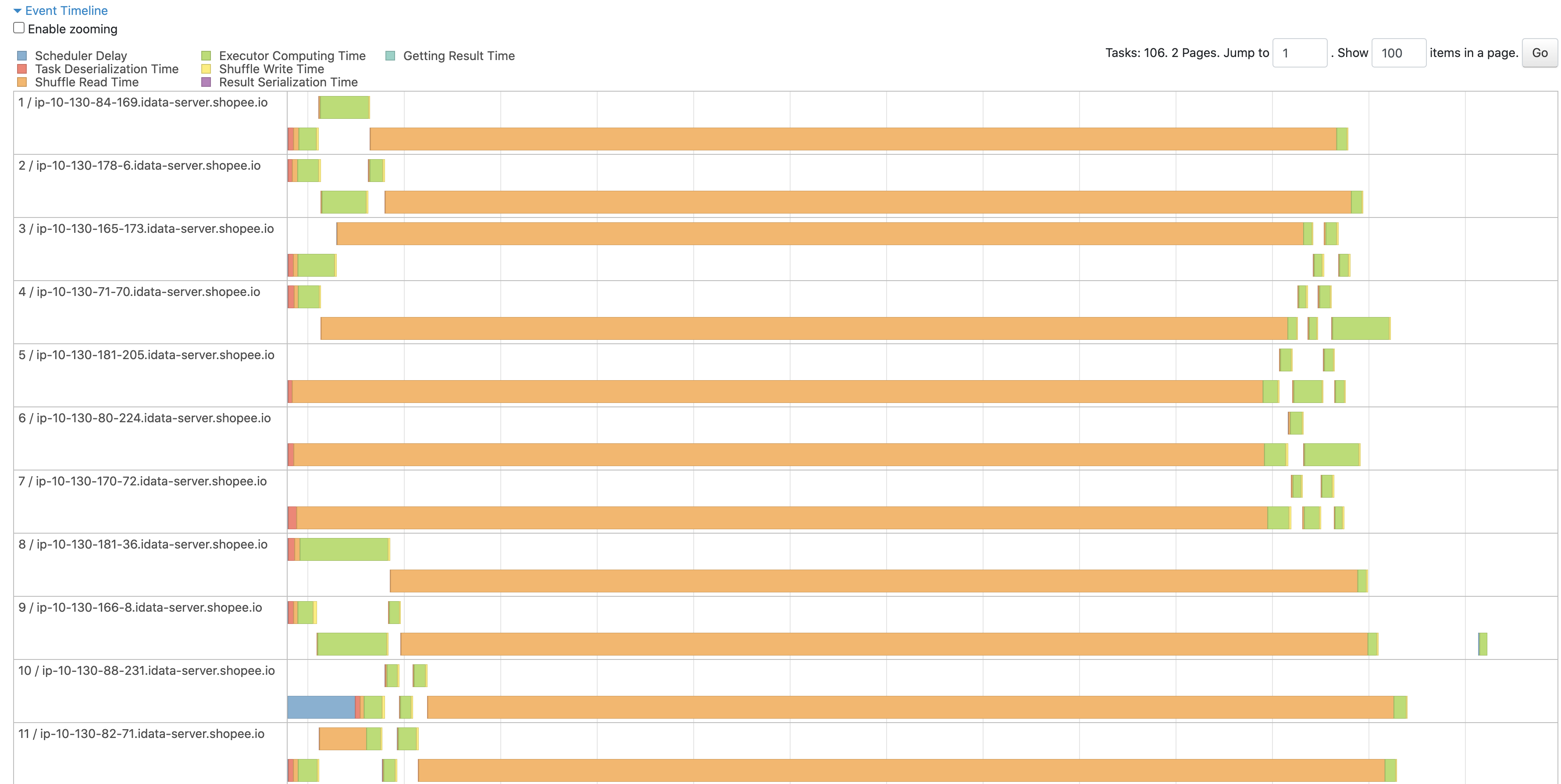
<img width="1783" alt="截屏2023-06-14 上午11 20 55" src="https://github.com/apache/incubator-celeborn/assets/46485123/182dff7d-a057-4077-8368-d1552104d206">
After patch
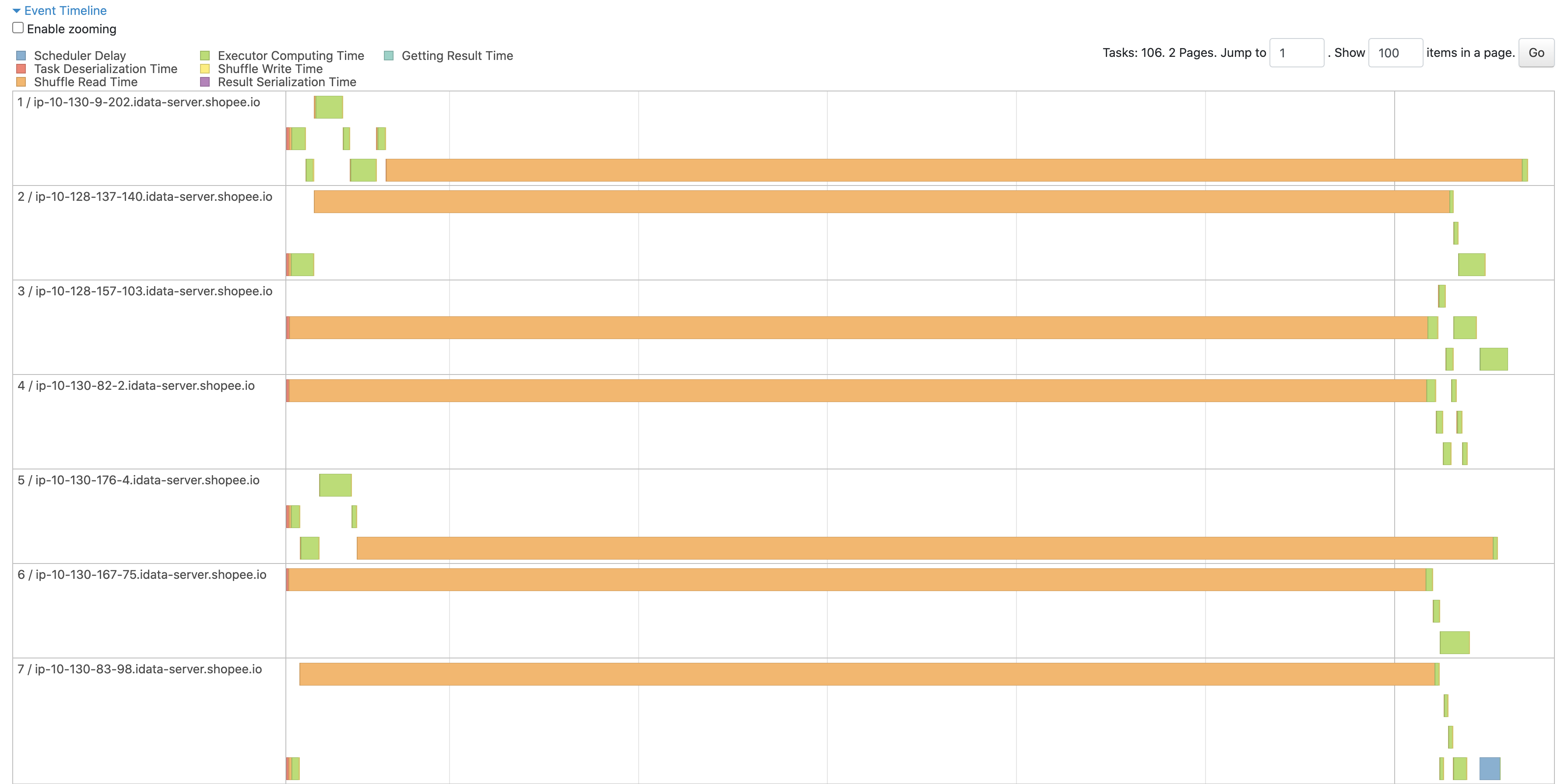
<img width="1792" alt="image" src="https://github.com/apache/incubator-celeborn/assets/46485123/3c8b7933-8ace-426d-8e9f-04e0aabfac8e">
The log shows the fetch timeout checker workers
```
23/06/14 11:14:54 ERROR WorkerPartitionReader: Fetch chunk 0 failed.
org.apache.celeborn.common.exception.CelebornIOException: FETCH_DATA_TIMEOUT
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:147)
at org.apache.celeborn.common.network.client.TransportResponseHandler.lambda$new$1(TransportResponseHandler.java:103)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
23/06/14 11:14:54 WARN RssInputStream: Fetch chunk failed 1/6 times for location PartitionLocation[
id-epoch:35-0
host-rpcPort-pushPort-fetchPort-replicatePort:10.169.48.203-9092-9094-9093-9095
mode:MASTER
peer:(host-rpcPort-pushPort-fetchPort-replicatePort:10.169.48.202-9092-9094-9093-9095)
storage hint:StorageInfo{type=HDD, mountPoint='/mnt/ssd/0', finalResult=true, filePath=}
mapIdBitMap:null], change to peer
org.apache.celeborn.common.exception.CelebornIOException: Fetch chunk 0 failed.
at org.apache.celeborn.client.read.WorkerPartitionReader$1.onFailure(WorkerPartitionReader.java:98)
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:146)
at org.apache.celeborn.common.network.client.TransportResponseHandler.lambda$new$1(TransportResponseHandler.java:103)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.celeborn.common.exception.CelebornIOException: FETCH_DATA_TIMEOUT
at org.apache.celeborn.common.network.client.TransportResponseHandler.failExpiredFetchRequest(TransportResponseHandler.java:147)
... 8 more
23/06/14 11:14:54 INFO SortBasedShuffleWriter: Memory used 72.0 MB
```
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1587 from AngersZhuuuu/CELEBORN-676.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
ShuffleClientImpl::mapperEnded should not consider attemptId, speculation tasks will update attemptId.
### Why are the changes needed?
ditto
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Cluster test
Closes#1591 from onebox-li/fix-mapend.
Authored-by: onebox-li <lyh-36@163.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Add celeborn.metrics.conf to conf entity
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1593 from AngersZhuuuu/CELEBORN-681.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
refer to https://github.com/apache/spark/pull/40301
1. Optimize `Utils.bytesToString`. Arithmetic ops on BigInt and BigDecimal are order(s) of magnitude slower than the ops on primitive types. Division is an especially slow operation and it is used en masse here.
2. According to the information sourced from [Wikipedia](https://en.wikipedia.org/wiki/Kilobyte), it is established that 1000 is the appropriate factor for representing kilobytes (KB), while 1024 is the correct factor for kibibytes (KiB). In alignment with this understanding, changing the size unit from "KB" to "KiB".
### Why are the changes needed?
the Utils#bytesToString method is frequently employed in memory-related log messages.
### Does this PR introduce _any_ user-facing change?
No, only perf improvement.
### How was this patch tested?
existing UT and manually tested.
Closes#1590 from cfmcgrady/bytesToString.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Give Heartbeat one byte message and skip this byte when decode.
### Why are the changes needed?
Heartbeat message may split in to two netty buffer, then the `empty buffer` (which don't need actually, but need keep) be wrong removed, then decodeNext would throw NPE. see
``` java
while (headerBuf.readableBytes() < HEADER_SIZE) {
ByteBuf next = buffers.getFirst();
int toRead = Math.min(next.readableBytes(), HEADER_SIZE - headerBuf.readableBytes());
headerBuf.writeBytes(next, toRead);
if (!next.isReadable()) {
buffers.removeFirst().release();
}
}
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
UT & MANUAL
Closes#1589 from RexXiong/CELEBORN-675.
Authored-by: Shuang <lvshuang.tb@gmail.com>
Signed-off-by: zhongqiang.czq <zhongqiang.czq@alibaba-inc.com>
### What changes were proposed in this pull request?
Add hasPeer method to PartitionLocation
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1583 from AngersZhuuuu/CELEBORN-671.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
CommitHandler will check whether the target worker is in WorkerStatusTracker's excluded list. If so, skip calling commit files on it.
### Why are the changes needed?
Avoid unnecessary commit files to excluded worker.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Manual test.
Closes#1581 from waitinfuture/669.
Lead-authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Co-authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Co-authored-by: Keyong Zhou <zhouky@apache.org>
Signed-off-by: Shuang <lvshuang.tb@gmail.com>
### What changes were proposed in this pull request?
If some task retry or scheduled by speculation, the executors will keep failing because revive does not support old partition is empty.
Celeborn will trigger stage end if all mapper task calls mapper end, this is not what spark thinks a stage ends. So in this moment, kill spark executors will cause the spark task to rerun the current stage. Shuffle client will need to register shuffle first but get empty partition locations, and it will need to revive to get the latest location with empty locations.
Here are logs example
```
23/06/13 08:32:11 ERROR ShuffleClientImpl: Exception raised while reviving for shuffle 12 map 970 attempt 27 partition 152 epoch -1.
java.lang.NullPointerException
at org.apache.celeborn.common.util.PbSerDeUtils$.toPbPartitionLocation(PbSerDeUtils.scala:258)
at org.apache.celeborn.common.protocol.message.ControlMessages$Revive$.apply(ControlMessages.scala:207)
at org.apache.celeborn.client.ShuffleClientImpl.revive(ShuffleClientImpl.java:573)
at org.apache.celeborn.client.ShuffleClientImpl.pushOrMergeData(ShuffleClientImpl.java:656)
at org.apache.celeborn.client.ShuffleClientImpl.pushData(ShuffleClientImpl.java:984)
at org.apache.celeborn.client.write.DataPusher.pushData(DataPusher.java:197)
at org.apache.celeborn.client.write.DataPusher.access$500(DataPusher.java:38)
at org.apache.celeborn.client.write.DataPusher$1.run(DataPusher.java:123)
23/06/13 08:32:11 ERROR Executor: Exception in task 21.27 in stage 54.1 (TID 17255)
org.apache.celeborn.common.exception.CelebornIOException: Revive for shuffle spark-3df9647407f14c39868a17b7950899c5-12 partition 152 failed.
at org.apache.celeborn.client.ShuffleClientImpl.pushOrMergeData(ShuffleClientImpl.java:666)
at org.apache.celeborn.client.ShuffleClientImpl.pushData(ShuffleClientImpl.java:984)
at org.apache.celeborn.client.write.DataPusher.pushData(DataPusher.java:197)
at org.apache.celeborn.client.write.DataPusher.access$500(DataPusher.java:38)
at org.apache.celeborn.client.write.DataPusher$1.run(DataPusher.java:123)
23/06/13 08:32:11 INFO CoarseGrainedExecutorBackend: Got assigned task 17309
```
### Why are the changes needed?
To make shuffle client able to revive with empty locations.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
K8S cluster.
Closes#1586 from FMX/CELEBORN-674.
Authored-by: Ethan Feng <ethanfeng@apache.org>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Fix wrong method name
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1582 from AngersZhuuuu/CELEBORN-547-FOLLOWUP.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
…eful is disabled
### What changes were proposed in this pull request?
Worker should report WorkerLost instead of WorkerUnavailable in it's shutdown hook if graceful shutdown is disabled.
### Why are the changes needed?
To avoid unnecessary commit file requests from lifecycle manager since it's not graceful shutdown.
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
Closes#1580 from waitinfuture/668.
Authored-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
### What changes were proposed in this pull request?
Use System.currentTimeMillis() + JobID.generate() as CelebornAppId.
### Why are the changes needed?
Flink Application mode with HA may use fixed id(00000000000000000000000000000000) as jobId. see [FLINK-19358](https://issues.apache.org/jira/browse/FLINK-19358).
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Manual
Closes#1572 from RexXiong/CELEBORN-660.
Authored-by: Shuang <lvshuang.tb@gmail.com>
Signed-off-by: zhongqiang.czq <zhongqiang.czq@alibaba-inc.com>
### What changes were proposed in this pull request?
Throw exception when raft client request not success.
### Why are the changes needed?
Ratis client may not throw exception when submit request not success. Current only LeaderNotReadyException,NotLeaderException throw out exception this may cause some inconsistent.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
UT
Closes#1556 from RexXiong/CELEBORN-646.
Authored-by: Shuang <lvshuang.tb@gmail.com>
Signed-off-by: Shuang <lvshuang.tb@gmail.com>
### What changes were proposed in this pull request?
Define `protobuf-maven-plugin` in the root pom.xml
### Why are the changes needed?
to fix
```bash
build/mvn protobuf:compile -am -pl common
```
```
[ERROR] No plugin found for prefix 'protobuf' in the current project and in the plugin groups [org.apache.maven.plugins, org.codehaus.mojo] available from the repositories [local (/Users/fchen/.m2/repository), apache.snapshots (https://repository.apache.org/snapshots), central (https://repo.maven.apache.org/maven2)] -> [Help 1]
org.apache.maven.plugin.prefix.NoPluginFoundForPrefixException: No plugin found for prefix 'protobuf' in the current project and in the plugin groups [org.apache.maven.plugins, org.codehaus.mojo] available from the repositories [local (/Users/fchen/.m2/repository), apache.snapshots (https://repository.apache.org/snapshots), central (https://repo.maven.apache.org/maven2)]
at org.apache.maven.plugin.prefix.internal.DefaultPluginPrefixResolver.resolve (DefaultPluginPrefixResolver.java:95)
at org.apache.maven.lifecycle.internal.MojoDescriptorCreator.findPluginForPrefix (MojoDescriptorCreator.java:266)
at org.apache.maven.lifecycle.internal.MojoDescriptorCreator.getMojoDescriptor (MojoDescriptorCreator.java:220)
at org.apache.maven.lifecycle.internal.DefaultLifecycleTaskSegmentCalculator.calculateTaskSegments (DefaultLifecycleTaskSegmentCalculator.java:104)
at org.apache.maven.lifecycle.internal.DefaultLifecycleTaskSegmentCalculator.calculateTaskSegments (DefaultLifecycleTaskSegmentCalculator.java:83)
at org.apache.maven.lifecycle.internal.LifecycleStarter.execute (LifecycleStarter.java:89)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:298)
at org.apache.maven.DefaultMaven.doExecute (DefaultMaven.java:192)
at org.apache.maven.DefaultMaven.execute (DefaultMaven.java:105)
at org.apache.maven.cli.MavenCli.execute (MavenCli.java:960)
at org.apache.maven.cli.MavenCli.doMain (MavenCli.java:293)
at org.apache.maven.cli.MavenCli.main (MavenCli.java:196)
at sun.reflect.NativeMethodAccessorImpl.invoke0 (Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke (NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke (DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke (Method.java:498)
at org.codehaus.plexus.classworlds.launcher.Launcher.launchEnhanced (Launcher.java:282)
at org.codehaus.plexus.classworlds.launcher.Launcher.launch (Launcher.java:225)
at org.codehaus.plexus.classworlds.launcher.Launcher.mainWithExitCode (Launcher.java:406)
at org.codehaus.plexus.classworlds.launcher.Launcher.main (Launcher.java:347)
[ERROR]
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/NoPluginFoundForPrefixException
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
tested locally.
Closes#1579 from cfmcgrady/protobuf-plugin.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: Cheng Pan <chengpan@apache.org>
### What changes were proposed in this pull request?
Refine RssInputStream logs to indicate the failed location's info to help admin debug
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1576 from AngersZhuuuu/CELEBORN-663.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Angerszhuuuu <angers.zhu@gmail.com>
### What changes were proposed in this pull request?
1. renamed `RssShuffleWriterSuiteJ` to `CelebornShuffleWriterSuiteBase`, which now serves as an abstract base class.
2. two new classes, `HashBasedShuffleWriterSuiteJ` and `SortBasedShuffleWriterSuiteJ`, have been added. These classes extend `CelebornShuffleWriterSuiteBase` and provide suites for testing hash-based and sort-based shuffle writers.
### Why are the changes needed?
### Does this PR introduce _any_ user-facing change?
### How was this patch tested?
Closes#1570 from cfmcgrady/sort-based-writer-suite.
Authored-by: Fu Chen <cfmcgrady@gmail.com>
Signed-off-by: zky.zhoukeyong <zky.zhoukeyong@alibaba-inc.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}